This is the multi-page printable view of this section. Click here to print.
通过弹性策略实现错误恢复
1 - 概述
Dapr 提供了一种通过弹性规范来定义和应用容错策略的功能。弹性规范与组件规范存放在同一位置,并在 Dapr sidecar 启动时生效。sidecar 决定如何将这些策略应用于您的 Dapr API 调用。在自托管模式下,弹性规范文件必须命名为 resiliency.yaml。在 Kubernetes 中,Dapr 会找到您的应用程序使用的命名弹性规范。在弹性规范中,您可以定义常见的弹性模式策略,例如:
这些策略可以应用于目标,包括:
此外,弹性策略还可以限定到特定应用程序。
演示视频
了解更多关于如何使用 Dapr 编写弹性微服务。
弹性策略结构
以下是弹性策略的一般结构:
apiVersion: dapr.io/v1alpha1
kind: Resiliency
metadata:
name: myresiliency
scopes:
# 可选地将策略限定到特定应用程序
spec:
policies:
timeouts:
# 超时策略定义
retries:
# 重试策略定义
circuitBreakers:
# 断路器策略定义
targets:
apps:
# 应用程序及其应用的策略
actors:
# actor 类型及其应用的策略
components:
# 组件及其应用的策略
完整示例策略
apiVersion: dapr.io/v1alpha1
kind: Resiliency
metadata:
name: myresiliency
# 类似于订阅和配置规范,scopes 列出了可以使用此弹性规范的 Dapr 应用程序 ID。
scopes:
- app1
- app2
spec:
# policies 是定义超时、重试和断路器策略的地方。
# 每个策略都有一个名称,以便可以在弹性规范的 targets 部分引用。
policies:
# 超时是简单的命名持续时间。
timeouts:
general: 5s
important: 60s
largeResponse: 10s
# 重试是重试配置的命名模板,并在操作的生命周期内实例化。
retries:
pubsubRetry:
policy: constant
duration: 5s
maxRetries: 10
retryForever:
policy: exponential
maxInterval: 15s
maxRetries: -1 # 无限重试
important:
policy: constant
duration: 5s
maxRetries: 30
someOperation:
policy: exponential
maxInterval: 15s
largeResponse:
policy: constant
duration: 5s
maxRetries: 3
# 断路器会自动为每个组件和应用实例创建。
# 断路器维护的计数器在 Dapr sidecar 运行期间存在。它们不会被持久化。
circuitBreakers:
simpleCB:
maxRequests: 1
timeout: 30s
trip: consecutiveFailures >= 5
pubsubCB:
maxRequests: 1
interval: 8s
timeout: 45s
trip: consecutiveFailures > 8
# targets 是应用命名策略的对象。Dapr 支持 3 种目标类型 - 应用程序、组件和 actor
targets:
apps:
appB:
timeout: general
retry: important
# 服务的断路器是按应用实例限定的。
# 当断路器被触发时,该路由将从负载均衡中移除,持续配置的 `timeout` 时间。
circuitBreaker: simpleCB
actors:
myActorType: # 自定义 actor 类型名称
timeout: general
retry: important
# actor 的断路器可以按类型、ID 或两者限定。
# 当断路器被触发时,该类型或 ID 将从配置表中移除,持续配置的 `timeout` 时间。
circuitBreaker: simpleCB
circuitBreakerScope: both ##
circuitBreakerCacheSize: 5000
components:
# 对于状态存储,策略适用于保存和检索状态。
statestore1: # 任何组件名称 -- 这里是一个状态存储
outbound:
timeout: general
retry: retryForever
# 组件的断路器是按组件配置/实例限定的。例如 myRediscomponent。
# 当此断路器被触发时,所有与该组件的交互将在配置的 `timeout` 时间内被阻止。
circuitBreaker: simpleCB
pubsub1: # 任何组件名称 -- 这里是一个 pubsub broker
outbound:
retry: pubsubRetry
circuitBreaker: pubsubCB
pubsub2: # 任何组件名称 -- 这里是另一个 pubsub broker
outbound:
retry: pubsubRetry
circuitBreaker: pubsubCB
inbound: # inbound 仅适用于从 sidecar 到应用程序的传递
timeout: general
retry: important
circuitBreaker: pubsubCB
相关链接
观看此视频以了解如何使用弹性:
下一步
了解更多关于弹性策略和目标:
2 - 弹性策略
在 policies 下定义超时、重试和断路器策略。每个策略都有一个名称,以便您可以在弹性规范的 targets 部分中引用它们。
注意:Dapr 为某些 API 提供默认的重试机制。请参阅此处了解如何使用用户定义的重试策略覆盖默认重试逻辑。
超时
超时是可选策略,用于提前终止长时间运行的操作。如果超过了超时时间:
- 正在进行的操作将被终止(如果可能)。
- 返回错误。
有效值是 Go 的 time.ParseDuration 接受的格式,例如:15s、2m、1h30m。超时没有设置最大值。
示例:
spec:
policies:
# 超时是简单的命名持续时间。
timeouts:
general: 5s
important: 60s
largeResponse: 10s
如果未指定超时值,则策略不会强制执行时间限制,默认使用请求客户端设置的任何值。
重试
通过 retries,您可以为失败的操作定义重试策略,包括由于触发定义的超时或断路器策略而失败的请求。
Pub/sub 组件重试与入站弹性
每个 pub/sub 组件 都有其内置的重试行为。显式应用 Dapr 弹性策略不会覆盖这些内置重试机制。相反,重试策略补充了内置重试机制,这可能导致消息的重复聚集。以下重试选项是可配置的:
| 重试选项 | 描述 |
|---|---|
policy | 确定退避和重试间隔策略。有效值为 constant 和 exponential。默认为 constant。 |
duration | 确定重试之间的时间间隔。仅适用于 constant 策略。有效值为 200ms、15s、2m 等格式。默认为 5s。 |
maxInterval | 确定 exponential 退避策略可以增长到的最大间隔。额外的重试总是在 maxInterval 的持续时间之后发生。默认为 60s。有效值为 5s、1m、1m30s 等格式。 |
maxRetries | 尝试的最大重试次数。-1 表示无限次重试,而 0 表示请求不会被重试(本质上表现为未设置重试策略)。默认为 -1。 |
matching.httpStatusCodes | 可选:要重试的 HTTP 状态代码或代码范围的逗号分隔字符串。未列出的状态代码不重试。 有效值:100-599,参考 格式: <code> 或范围 <start>-<end>示例:“429,501-503” 默认:空字符串 "" 或字段未设置。重试所有 HTTP 错误。 |
matching.gRPCStatusCodes | 可选:要重试的 gRPC 状态代码或代码范围的逗号分隔字符串。未列出的状态代码不重试。 有效值:0-16,参考 格式: <code> 或范围 <start>-<end>示例:“1,501-503” 默认:空字符串 "" 或字段未设置。重试所有 gRPC 错误。 |
httpStatusCodes 和 gRPCStatusCodes 格式
字段值应遵循字段描述中指定的格式或下面的“示例 2”中的格式。 格式不正确的值将产生错误日志(“无法读取弹性策略”),并且daprd 启动序列将继续。指数退避窗口使用以下公式:
BackOffDuration = PreviousBackOffDuration * (随机值从 0.5 到 1.5) * 1.5
if BackOffDuration > maxInterval {
BackoffDuration = maxInterval
}
示例:
spec:
policies:
# 重试是重试配置的命名模板,并在操作的生命周期内实例化。
retries:
pubsubRetry:
policy: constant
duration: 5s
maxRetries: 10
retryForever:
policy: exponential
maxInterval: 15s
maxRetries: -1 # 无限重试
示例 2:
spec:
policies:
retries:
retry5xxOnly:
policy: constant
duration: 5s
maxRetries: 3
matching:
httpStatusCodes: "429,500-599" # 重试此范围内的 HTTP 状态代码。所有其他不重试。
gRPCStatusCodes: "1-4,8-11,13,14" # 重试这些范围内的 gRPC 状态代码并分隔单个代码。
断路器
断路器(CB)策略用于当其他应用程序/服务/组件经历较高的失败率时。CB 监控请求,并在满足某个条件时关闭所有流向受影响服务的流量(“打开”状态)。通过这样做,CB 给服务时间从其故障中恢复,而不是用事件淹没它。CB 还可以允许部分流量通过,以查看系统是否已恢复(“半开”状态)。一旦请求恢复成功,CB 进入“关闭”状态并允许流量完全恢复。
| 重试选项 | 描述 |
|---|---|
maxRequests | 在 CB 半开(从故障中恢复)时允许通过的最大请求数。默认为 1。 |
interval | CB 用于清除其内部计数的周期性时间段。如果设置为 0 秒,则永不清除。默认为 0s。 |
timeout | 开放状态(直接在故障后)到 CB 切换到半开的时间段。默认为 60s。 |
trip | 由 CB 评估的 通用表达式语言(CEL) 语句。当语句评估为 true 时,CB 触发并变为打开。默认为 consecutiveFailures > 5。其他可能的值是 requests 和 totalFailures,其中 requests 表示电路打开之前的成功或失败调用次数,totalFailures 表示电路打开之前的总失败尝试次数(不一定是连续的)。示例:requests > 5 和 totalFailures >3。 |
示例:
spec:
policies:
circuitBreakers:
pubsubCB:
maxRequests: 1
interval: 8s
timeout: 45s
trip: consecutiveFailures > 8
覆盖默认重试
Dapr 为任何不成功的请求(如失败和瞬态错误)提供默认重试。在弹性规范中,您可以通过定义具有保留名称关键字的策略来覆盖 Dapr 的默认重试逻辑。例如,定义名为 DaprBuiltInServiceRetries 的策略,覆盖通过服务到服务请求的 sidecar 之间的失败的默认重试。策略覆盖不适用于特定目标。
注意:尽管您可以使用更强大的重试覆盖默认值,但您不能使用比提供的默认值更低的值覆盖,或完全删除默认重试。这可以防止意外停机。
下面是描述 Dapr 默认重试和覆盖它们的策略关键字的表格:
| 功能 | 覆盖关键字 | 默认重试行为 | 描述 |
|---|---|---|---|
| 服务调用 | DaprBuiltInServiceRetries | 每次调用重试以 1 秒的退避间隔执行,最多达到 3 次的阈值。 | sidecar 到 sidecar 请求(服务调用方法调用)失败并导致 gRPC 代码 Unavailable 或 Unauthenticated |
| actor | DaprBuiltInActorRetries | 每次调用重试以 1 秒的退避间隔执行,最多达到 3 次的阈值。 | sidecar 到 sidecar 请求(actor 方法调用)失败并导致 gRPC 代码 Unavailable 或 Unauthenticated |
| actor 提醒 | DaprBuiltInActorReminderRetries | 每次调用重试以指数退避执行,初始间隔为 500ms,最多 60s,持续 15 分钟 | 请求失败将 actor 提醒持久化到状态存储 |
| 初始化重试 | DaprBuiltInInitializationRetries | 每次调用重试 3 次,指数退避,初始间隔为 500ms,持续 10s | 向应用程序发出请求以检索给定规范时的失败。例如,无法检索订阅、组件或弹性规范 |
下面的弹性规范示例显示了使用保留名称关键字 ‘DaprBuiltInServiceRetries’ 覆盖 所有 服务调用请求的默认重试。
还定义了一个名为 ‘retryForever’ 的重试策略,仅适用于 appB 目标。appB 使用 ‘retryForever’ 重试策略,而所有其他应用程序服务调用重试失败使用覆盖的 ‘DaprBuiltInServiceRetries’ 默认策略。
spec:
policies:
retries:
DaprBuiltInServiceRetries: # 覆盖服务到服务调用的默认重试行为
policy: constant
duration: 5s
maxRetries: 10
retryForever: # 用户定义的重试策略替换默认重试。目标仅依赖于应用的策略。
policy: exponential
maxInterval: 15s
maxRetries: -1 # 无限重试
targets:
apps:
appB: # 目标服务的 app-id
retry: retryForever
设置默认策略
在弹性中,您可以设置默认策略,这些策略具有广泛的范围。这是通过保留关键字完成的,这些关键字让 Dapr 知道何时应用策略。有 3 种默认策略类型:
DefaultRetryPolicyDefaultTimeoutPolicyDefaultCircuitBreakerPolicy
如果定义了这些策略,它们将用于服务、应用程序或组件的每个操作。它们还可以通过附加其他关键字进行更具体的修改。特定策略遵循以下模式,Default%sRetryPolicy、Default%sTimeoutPolicy 和 Default%sCircuitBreakerPolicy。其中 %s 被策略的目标替换。
下面是所有可能的默认策略关键字及其如何转换为策略名称的表格。
| 关键字 | 目标操作 | 示例策略名称 |
|---|---|---|
App | 服务调用。 | DefaultAppRetryPolicy |
Actor | actor 调用。 | DefaultActorTimeoutPolicy |
Component | 所有组件操作。 | DefaultComponentCircuitBreakerPolicy |
ComponentInbound | 所有入站组件操作。 | DefaultComponentInboundRetryPolicy |
ComponentOutbound | 所有出站组件操作。 | DefaultComponentOutboundTimeoutPolicy |
StatestoreComponentOutbound | 所有状态存储组件操作。 | DefaultStatestoreComponentOutboundCircuitBreakerPolicy |
PubsubComponentOutbound | 所有出站 pubsub(发布)组件操作。 | DefaultPubsubComponentOutboundRetryPolicy |
PubsubComponentInbound | 所有入站 pubsub(订阅)组件操作。 | DefaultPubsubComponentInboundTimeoutPolicy |
BindingComponentOutbound | 所有出站绑定(调用)组件操作。 | DefaultBindingComponentOutboundCircuitBreakerPolicy |
BindingComponentInbound | 所有入站绑定(读取)组件操作。 | DefaultBindingComponentInboundRetryPolicy |
SecretstoreComponentOutbound | 所有 secretstore 组件操作。 | DefaultSecretstoreComponentTimeoutPolicy |
ConfigurationComponentOutbound | 所有配置组件操作。 | DefaultConfigurationComponentOutboundCircuitBreakerPolicy |
LockComponentOutbound | 所有锁组件操作。 | DefaultLockComponentOutboundRetryPolicy |
策略层次结构解析
如果正在执行的操作与策略类型匹配,并且没有更具体的策略针对它,则应用默认策略。对于每个目标类型(应用程序、actor 和组件),优先级最高的策略是命名策略,即专门针对该构造的策略。
如果不存在,则策略从最具体到最广泛应用。
默认策略和内置重试如何协同工作
在 [内置重试](https://v1-16.docs.dapr.io/zh-hans/operations/resiliency/policies/#Override Default Retries) 的情况下,默认策略不会阻止内置重试策略运行。两者一起使用,但仅在特定情况下。
对于服务和 actor 调用,内置重试专门处理连接到远程 sidecar 的问题(如有必要)。由于这些对于 Dapr 运行时的稳定性至关重要,因此它们不会被禁用除非为操作专门引用了命名策略。在某些情况下,可能会有来自内置重试和默认重试策略的额外重试,但这可以防止过于弱的默认策略降低 sidecar 的可用性/成功率。
应用程序的策略解析层次结构,从最具体到最广泛:
- 应用程序目标中的命名策略
- 默认应用程序策略 / 内置服务重试
- 默认策略 / 内置服务重试
actor 的策略解析层次结构,从最具体到最广泛:
- actor 目标中的命名策略
- 默认 actor 策略 / 内置 actor 重试
- 默认策略 / 内置 actor 重试
组件的策略解析层次结构,从最具体到最广泛:
- 组件目标中的命名策略
- 默认组件类型 + 组件方向策略 / 内置 actor 提醒重试(如适用)
- 默认组件方向策略 / 内置 actor 提醒重试(如适用)
- 默认组件策略 / 内置 actor 提醒重试(如适用)
- 默认策略 / 内置 actor 提醒重试(如适用)
例如,以下解决方案由三个应用程序、三个组件和两个 actor 类型组成:
应用程序:
- AppA
- AppB
- AppC
组件:
- Redis Pubsub: pubsub
- Redis 状态存储: statestore
- CosmosDB 状态存储: actorstore
actor:
- EventActor
- SummaryActor
下面是使用默认和命名策略的策略,并将其应用于目标。
spec:
policies:
retries:
# 全局重试策略
DefaultRetryPolicy:
policy: constant
duration: 1s
maxRetries: 3
# 应用程序的全局重试策略
DefaultAppRetryPolicy:
policy: constant
duration: 100ms
maxRetries: 5
# actor 的全局重试策略
DefaultActorRetryPolicy:
policy: exponential
maxInterval: 15s
maxRetries: 10
# 入站组件操作的全局重试策略
DefaultComponentInboundRetryPolicy:
policy: constant
duration: 5s
maxRetries: 5
# 状态存储的全局重试策略
DefaultStatestoreComponentOutboundRetryPolicy:
policy: exponential
maxInterval: 60s
maxRetries: -1
# 命名策略
fastRetries:
policy: constant
duration: 10ms
maxRetries: 3
# 命名策略
retryForever:
policy: exponential
maxInterval: 10s
maxRetries: -1
targets:
apps:
appA:
retry: fastRetries
appB:
retry: retryForever
actors:
EventActor:
retry: retryForever
components:
actorstore:
retry: fastRetries
下表是尝试调用此解决方案中的各种目标时应用的策略的细分。
| 目标 | 使用的策略 |
|---|---|
| AppA | fastRetries |
| AppB | retryForever |
| AppC | DefaultAppRetryPolicy / DaprBuiltInActorRetries |
| pubsub - 发布 | DefaultRetryPolicy |
| pubsub - 订阅 | DefaultComponentInboundRetryPolicy |
| statestore | DefaultStatestoreComponentOutboundRetryPolicy |
| actorstore | fastRetries |
| EventActor | retryForever |
| SummaryActor | DefaultActorRetryPolicy |
下一步
尝试其中一个弹性快速入门:
3 - 目标
目标
命名的策略被应用于目标。Dapr支持三种目标类型,这些类型适用于所有Dapr构建块的API:
appscomponentsactors
应用程序
使用apps目标,您可以将retry、timeout和circuitBreaker策略应用于Dapr应用程序之间的服务调用。在targets/apps下,策略应用于每个目标服务的app-id。当sidecar之间的通信出现故障时,这些策略将被调用,如下图所示。
Dapr提供了内置的服务调用重试,因此任何应用的
retry策略都是额外的。
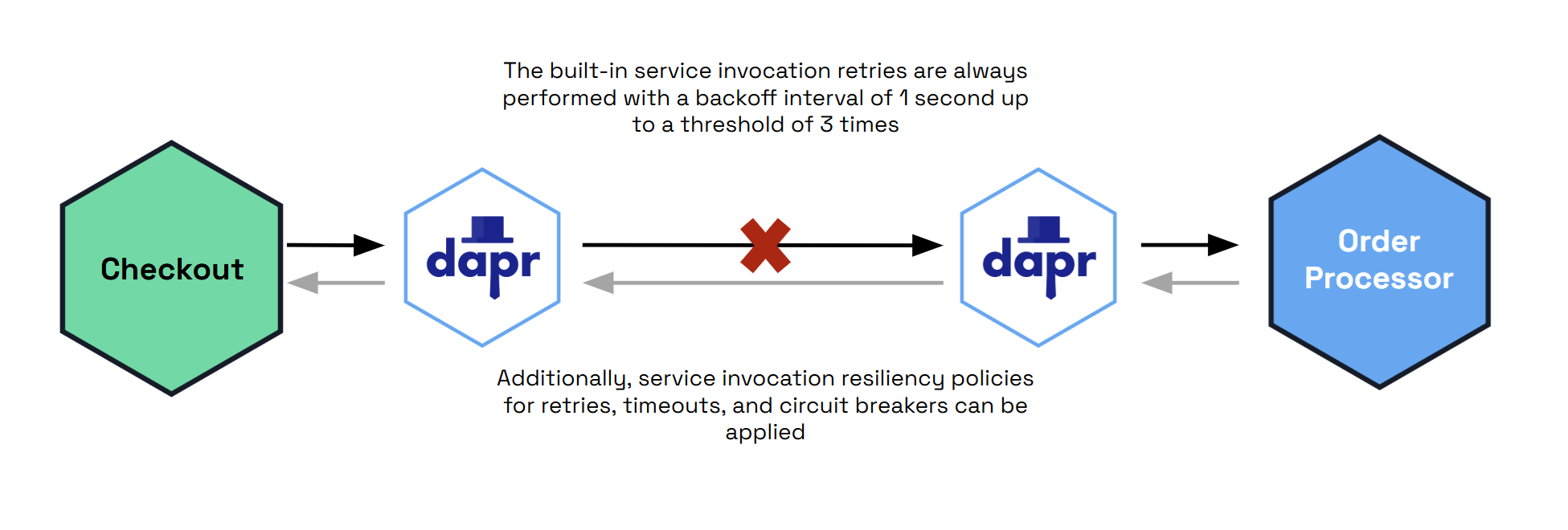
应用于目标应用程序app-id为"appB"的策略示例:
specs:
targets:
apps:
appB: # 目标服务的app-id
timeout: general
retry: general
circuitBreaker: general
组件
使用components目标,您可以将retry、timeout和circuitBreaker策略应用于组件操作。
策略可以应用于outbound操作(从Dapr sidecar到组件的调用)和/或inbound(从sidecar到您的应用程序的调用)。
出站
outbound操作是从sidecar到组件的调用,例如:
- 持久化或检索状态。
- 在pubsub组件上发布消息。
- 调用输出绑定。
某些组件可能具有内置的重试功能,并且可以在每个组件的基础上进行配置。
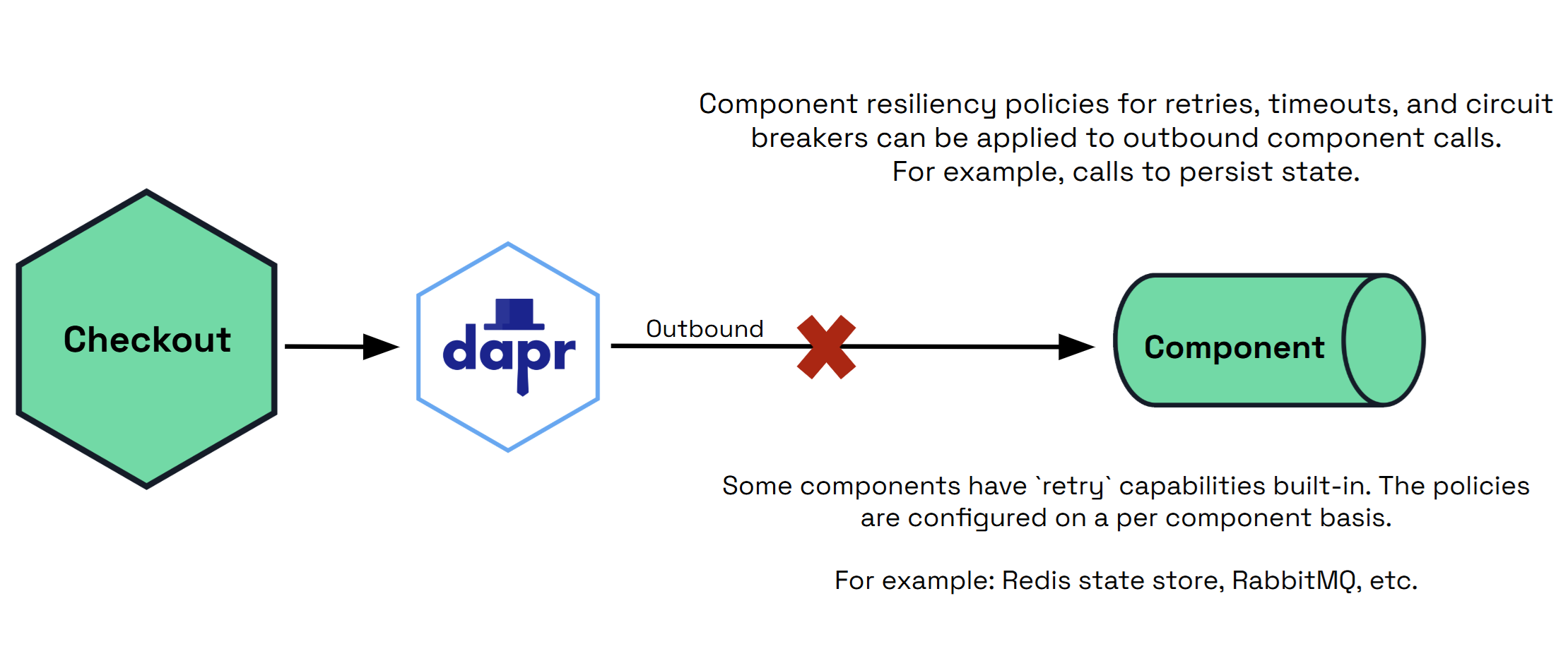
spec:
targets:
components:
myStateStore:
outbound:
retry: retryForever
circuitBreaker: simpleCB
入站
inbound操作是从sidecar到您的应用程序的调用,例如:
- pubsub订阅在传递消息时。
- 输入绑定。
某些组件可能具有内置的重试功能,并且可以在每个组件的基础上进行配置。
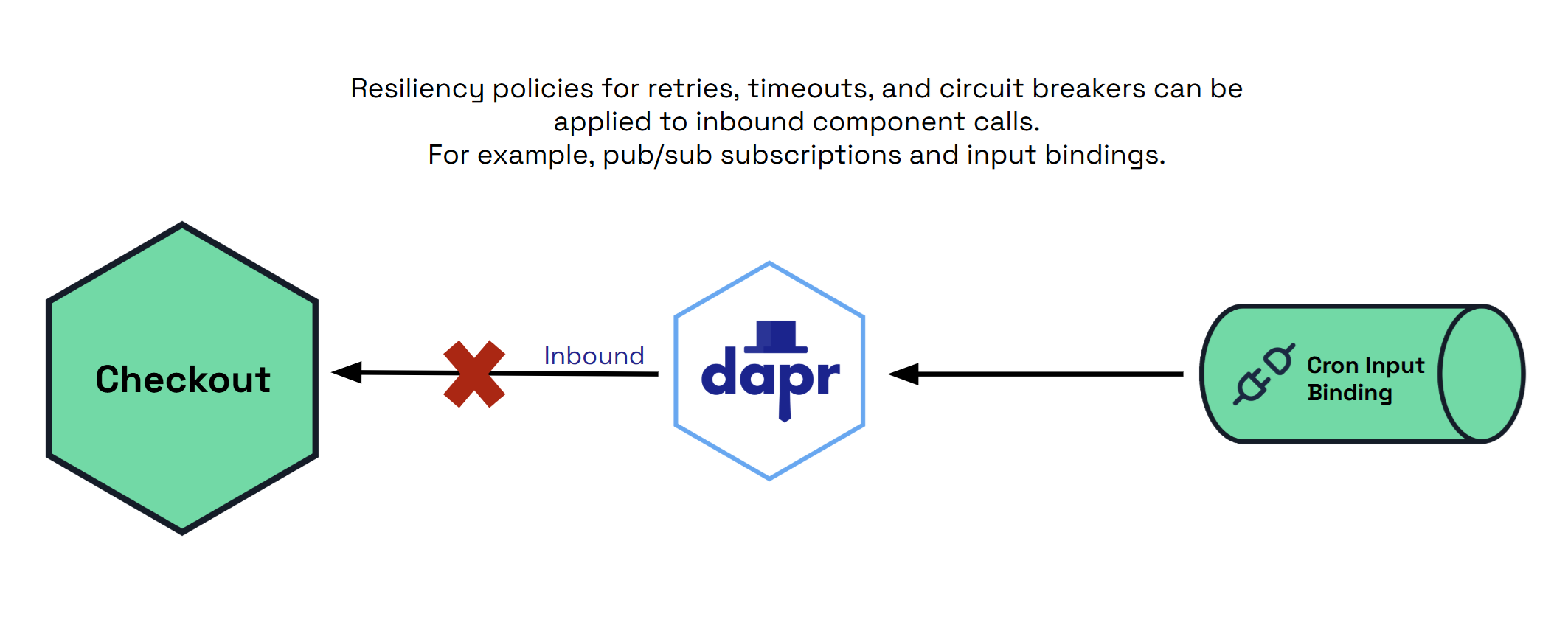
spec:
targets:
components:
myInputBinding:
inbound:
timeout: general
retry: general
circuitBreaker: general
PubSub
在pubsub target/component中,您可以同时指定inbound和outbound操作。
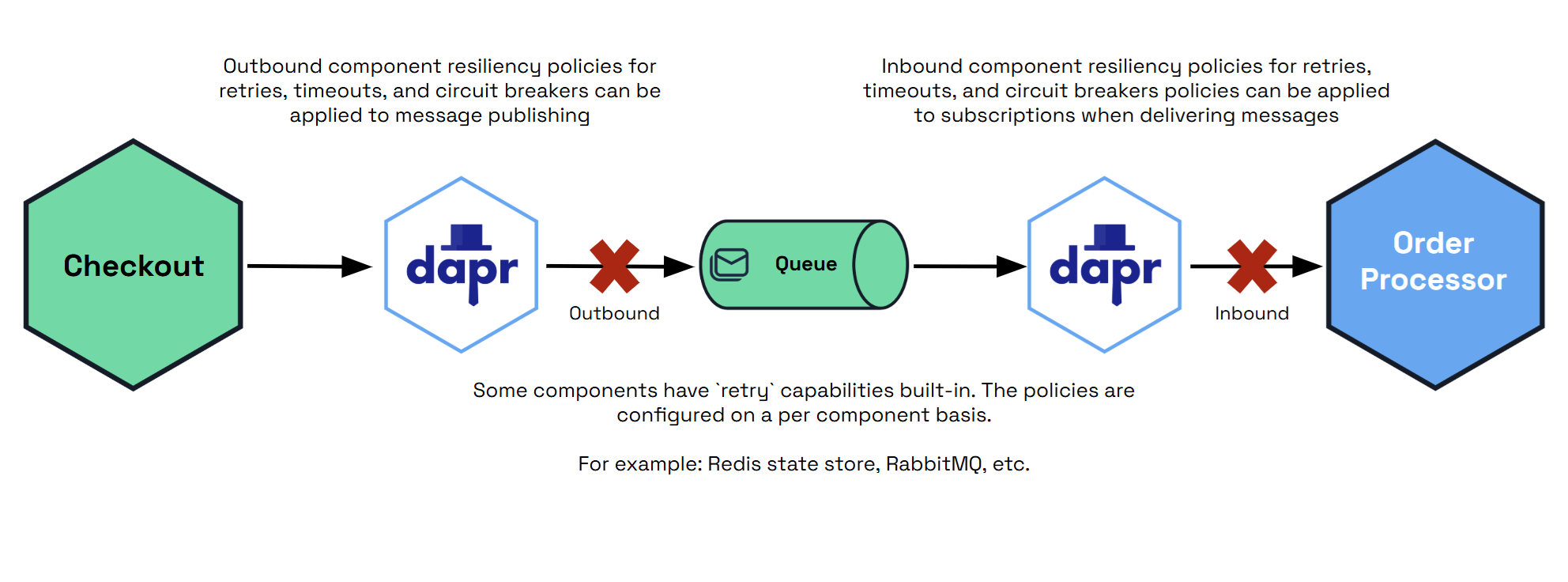
spec:
targets:
components:
myPubsub:
outbound:
retry: pubsubRetry
circuitBreaker: pubsubCB
inbound: # 入站仅适用于从sidecar到应用程序的传递
timeout: general
retry: general
circuitBreaker: general
Actor
使用actors目标,您可以将retry、timeout和circuitBreaker策略应用于actor操作。
当为actors目标使用circuitBreaker策略时,您可以通过circuitBreakerScope指定电路断开的范围:
id:单个actor IDtype:给定actor类型的所有actorboth:以上两者
您还可以使用circuitBreakerCacheSize属性指定要在内存中保留的电路断路器数量的缓存大小,提供一个整数值,例如5000。
示例
spec:
targets:
actors:
myActorType:
timeout: general
retry: general
circuitBreaker: general
circuitBreakerScope: both
circuitBreakerCacheSize: 5000
下一步
尝试其中一个弹性快速入门:
4 - 健康检查
4.1 - 应用健康检查
应用健康检查功能可以检测应用程序的健康状况,并对状态变化做出反应。
应用程序可能由于多种原因变得无响应。例如,您的应用程序:
- 可能太忙而无法接受新工作;
- 可能已崩溃;或
- 可能处于死锁状态。
有时这种情况可能是暂时的,例如:
- 如果应用程序只是忙碌,最终会恢复接受新工作
- 如果应用程序因某种原因正在重启并处于初始化阶段
应用健康检查默认情况下是禁用的。一旦启用,Dapr 运行时(sidecar)会通过 HTTP 或 gRPC 调用定期轮询您的应用程序。当检测到应用程序的健康状况出现问题时,Dapr 会通过以下方式暂停接受新工作:
- 取消所有 pub/sub 订阅
- 停止所有输入绑定
- 短路所有服务调用请求,这些请求在 Dapr 运行时终止,不会转发到应用程序
这些变化是暂时的,一旦 Dapr 检测到应用程序恢复响应,它将恢复正常操作。

应用健康检查与平台级健康检查
Dapr 的应用健康检查旨在补充而不是替代任何平台级健康检查,例如在 Kubernetes 上运行时的存活探针。
平台级健康检查(或存活探针)通常确保应用程序正在运行,并在出现故障时导致平台重启应用程序。
与平台级健康检查不同,Dapr 的应用健康检查专注于暂停当前无法接受工作的应用程序,但预计最终能够恢复接受工作。目标包括:
- 不给已经超载的应用程序带来更多负担。
- 当 Dapr 知道应用程序无法处理消息时,不从队列、绑定或 pub/sub 代理中获取消息。
在这方面,Dapr 的应用健康检查是“较软”的,等待应用程序能够处理工作,而不是以“硬”方式终止正在运行的进程。
注意
对于 Kubernetes,失败的应用健康检查不会将 pod 从服务发现中移除:这仍然是 Kubernetes 存活探针的责任,而不是 Dapr。配置应用健康检查
应用健康检查默认情况下是禁用的,但可以通过以下方式启用:
--enable-app-health-checkCLI 标志;或- 在 Kubernetes 上运行时使用
dapr.io/enable-app-health-check: true注释。
添加此标志是启用应用健康检查的必要且充分条件,使用默认选项。
完整的选项列表如下表所示:
| CLI 标志 | Kubernetes 部署注释 | 描述 | 默认值 |
|---|---|---|---|
--enable-app-health-check | dapr.io/enable-app-health-check | 启用健康检查的布尔值 | 禁用 |
--app-health-check-path | dapr.io/app-health-check-path | 当应用通道为 HTTP 时,Dapr 用于健康探测的路径(如果应用通道使用 gRPC,则忽略此值) | /healthz |
--app-health-probe-interval | dapr.io/app-health-probe-interval | 每次健康探测之间的秒数 | 5 |
--app-health-probe-timeout | dapr.io/app-health-probe-timeout | 健康探测请求的超时时间(以毫秒为单位) | 500 |
--app-health-threshold | dapr.io/app-health-threshold | 在应用被视为不健康之前的最大连续失败次数 | 3 |
请参阅完整的 Dapr 参数和注释参考以获取所有选项及其启用方法。
此外,应用健康检查受应用通道使用的协议影响,该协议通过以下标志或注释进行配置:
| CLI 标志 | Kubernetes 部署注释 | 描述 | 默认值 |
|---|---|---|---|
--app-protocol | dapr.io/app-protocol | 应用通道使用的协议。支持的值有 http、grpc、https、grpcs 和 h2c(HTTP/2 明文)。 | http |
注意
如果应用健康探测超时值过低,可能会在应用程序遇到突然高负载时将其分类为不健康,导致响应时间下降。如果发生这种情况,请增加dapr.io/app-health-probe-timeout 值。健康检查路径
HTTP
当使用 HTTP(包括 http、https 和 h2c)作为 app-protocol 时,Dapr 通过对 app-health-check-path 指定的路径进行 HTTP 调用来执行健康探测,默认路径为 /health。
为了使您的应用被视为健康,响应必须具有 200-299 范围内的 HTTP 状态码。任何其他状态码都被视为失败。Dapr 只关心响应的状态码,忽略任何响应头或正文。
gRPC
当使用 gRPC 作为应用通道(app-protocol 设置为 grpc 或 grpcs)时,Dapr 在您的应用程序中调用方法 /dapr.proto.runtime.v1.AppCallbackHealthCheck/HealthCheck。您很可能会使用 Dapr SDK 来实现此方法的处理程序。
在响应健康探测请求时,您的应用可以决定执行额外的内部健康检查,以确定它是否准备好处理来自 Dapr 运行时的工作。然而,这不是必需的;这取决于您的应用程序的需求。
间隔、超时和阈值
间隔
默认情况下,当启用应用健康检查时,Dapr 每 5 秒探测一次您的应用程序。您可以使用 app-health-probe-interval 配置间隔(以秒为单位)。这些探测会定期发生,无论您的应用程序是否健康。
超时
当 Dapr 运行时(sidecar)最初启动时,Dapr 会等待成功的健康探测,然后才认为应用程序是健康的。这意味着在第一次健康检查完成并成功之前,pub/sub 订阅、输入绑定和服务调用请求不会为您的应用程序启用。
如果应用程序在 app-health-probe-timeout 中配置的超时内发送成功响应(如上所述),则健康探测请求被视为成功。默认值为 500,对应于 500 毫秒(半秒)。
阈值
在 Dapr 认为应用程序进入不健康状态之前,它将等待 app-health-threshold 次连续失败,默认值为 3。此默认值意味着您的应用程序必须连续失败健康探测 3 次才能被视为不健康。
如果您将阈值设置为 1,任何失败都会导致 Dapr 假设您的应用程序不健康,并停止向其传递工作。
大于 1 的阈值可以帮助排除由于外部情况导致的瞬态故障。适合您的应用程序的正确值取决于您的要求。
阈值仅适用于失败。单个成功响应足以让 Dapr 认为您的应用程序是健康的,并恢复正常操作。
示例
使用 dapr run 命令的 CLI 标志启用应用健康检查:
dapr run \
--app-id my-app \
--app-port 7001 \
--app-protocol http \
--enable-app-health-check \
--app-health-check-path=/healthz \
--app-health-probe-interval 3 \
--app-health-probe-timeout 200 \
--app-health-threshold 2 \
-- \
<command to execute>
要在 Kubernetes 中启用应用健康检查,请将相关注释添加到您的 Deployment:
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-app
labels:
app: my-app
spec:
template:
metadata:
labels:
app: my-app
annotations:
dapr.io/enabled: "true"
dapr.io/app-id: "my-app"
dapr.io/app-port: "7001"
dapr.io/app-protocol: "http"
dapr.io/enable-app-health-check: "true"
dapr.io/app-health-check-path: "/healthz"
dapr.io/app-health-probe-interval: "3"
dapr.io/app-health-probe-timeout: "200"
dapr.io/app-health-threshold: "2"
演示
观看此视频以获取使用应用健康检查的概述:
4.2 - Sidecar 健康检查
Dapr 提供了一种方法,通过 HTTP /healthz 端点 来确定其健康状态。通过这个端点,daprd 进程或 sidecar 可以:
- 检查整体健康状况
- 在初始化期间确认 Dapr sidecar 的就绪状态
- 在 Kubernetes 中确定就绪和存活状态
在本指南中,您将了解 Dapr /healthz 端点如何与应用托管平台(如 Kubernetes)以及 Dapr SDK 的健康检查功能集成。
注意
Dapr actor 也有一个健康 API 端点,Dapr 会探测应用程序以响应 Dapr 发出的信号,确认 actor 应用程序是健康且正在运行的。请参阅 actor 健康 API。下图展示了 Dapr sidecar 启动时,healthz 端点和应用通道初始化的步骤。
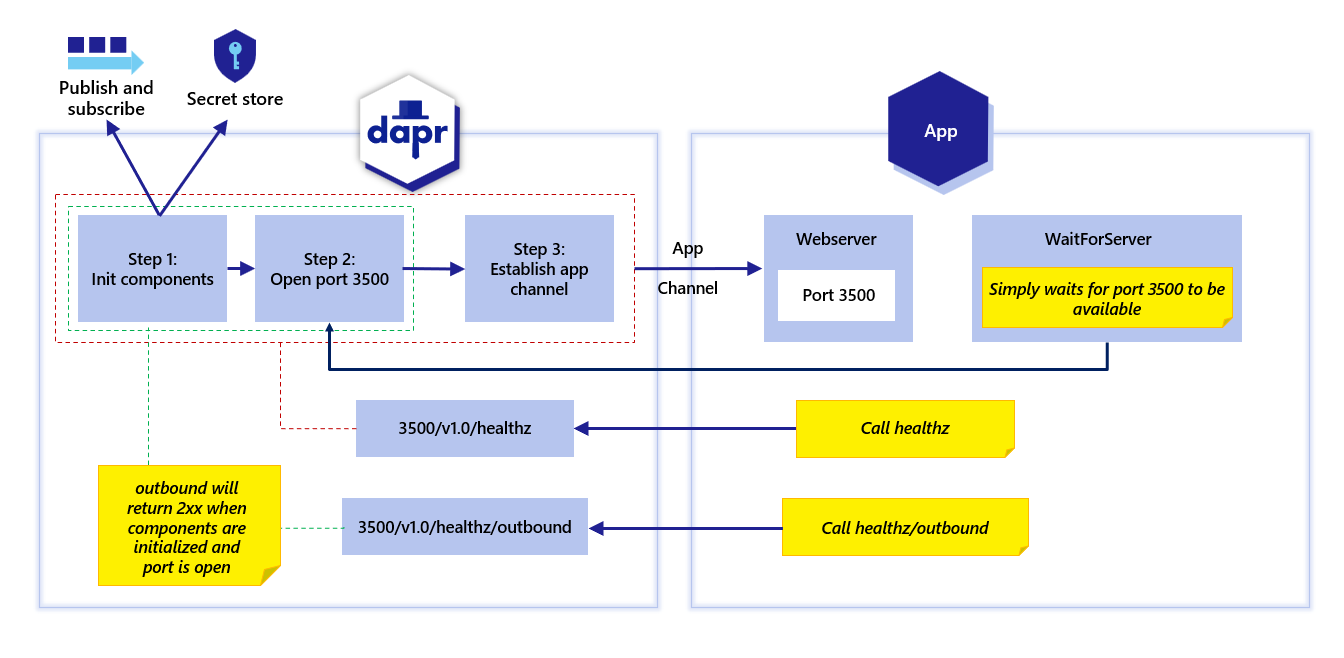
出站健康端点
如上图中的红色边界线所示,v1.0/healthz/ 端点用于等待以下情况:
- 所有组件已初始化;
- Dapr HTTP 端口可用;并且,
- 应用通道已初始化。
这用于确认 Dapr sidecar 的完整初始化及其健康状况。
您可以通过设置 DAPR_HEALTH_TIMEOUT 环境变量来控制健康检查的超时时间,这在高延迟环境中可能很重要。
另一方面,如上图中的绿色边界线所示,当 v1.0/healthz/outbound 端点返回成功时:
- 所有组件已初始化;
- Dapr HTTP 端口可用;但,
- 应用通道尚未建立。
在 Dapr SDK 中,waitForSidecar/wait_until_ready 方法(取决于您使用的 SDK)用于通过 v1.0/healthz/outbound 端点进行此特定检查。使用这种方法,您的应用程序可以在应用通道初始化之前调用 Dapr sidecar API,例如,通过 secret API 读取 secret。
如果您在 SDK 上使用 waitForSidecar/wait_until_ready 方法,则会执行正确的初始化。否则,您可以在初始化期间调用 v1.0/healthz/outbound 端点,如果成功,您可以调用 Dapr sidecar API。
支持出站健康端点的 SDK
目前,v1.0/healthz/outbound 端点在以下 SDK 中得到支持:
健康端点:与 Kubernetes 的集成
当将 Dapr 部署到像 Kubernetes 这样的托管平台时,Dapr 健康端点会自动为您配置。
Kubernetes 使用 就绪 和 存活 探针来确定容器的健康状况。
存活性
kubelet 使用存活探针来判断何时需要重启容器。例如,存活探针可以捕获死锁(一个无法进展的运行应用程序)。在这种状态下重启容器可以帮助提高应用程序的可用性,即使存在错误。
如何在 Kubernetes 中配置存活探针
在 pod 配置文件中,存活探针被添加到容器规范部分,如下所示:
livenessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 3
periodSeconds: 3
在上述示例中,periodSeconds 字段指定 kubelet 应每 3 秒执行一次存活探针。initialDelaySeconds 字段告诉 kubelet 应在执行第一次探针前等待 3 秒。为了执行探针,kubelet 向在容器中运行并监听端口 8080 的服务器发送 HTTP GET 请求。如果服务器的 /healthz 路径的处理程序返回成功代码,kubelet 认为容器是存活且健康的。如果处理程序返回失败代码,kubelet 会杀死容器并重启它。
任何介于 200 和 399 之间的 HTTP 状态代码表示成功;任何其他状态代码表示失败。
就绪性
kubelet 使用就绪探针来判断容器何时准备好开始接受流量。当所有容器都准备好时,pod 被认为是就绪的。就绪信号的一个用途是控制哪些 pod 被用作 Kubernetes 服务的后端。当 pod 未就绪时,它会从 Kubernetes 服务负载均衡器中移除。
注意
一旦应用程序在其配置的端口上可访问,Dapr sidecar 将处于就绪状态。在应用程序启动/初始化期间,应用程序无法访问 Dapr 组件。如何在 Kubernetes 中配置就绪探针
就绪探针的配置与存活探针类似。唯一的区别是使用 readinessProbe 字段而不是 livenessProbe 字段:
readinessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 3
periodSeconds: 3
Sidecar 注入器
在与 Kubernetes 集成时,Dapr sidecar 被注入了一个 Kubernetes 探针配置,告诉它使用 Dapr healthz 端点。这是由 “Sidecar 注入器” 系统服务完成的。与 kubelet 的集成如下面的图示所示。
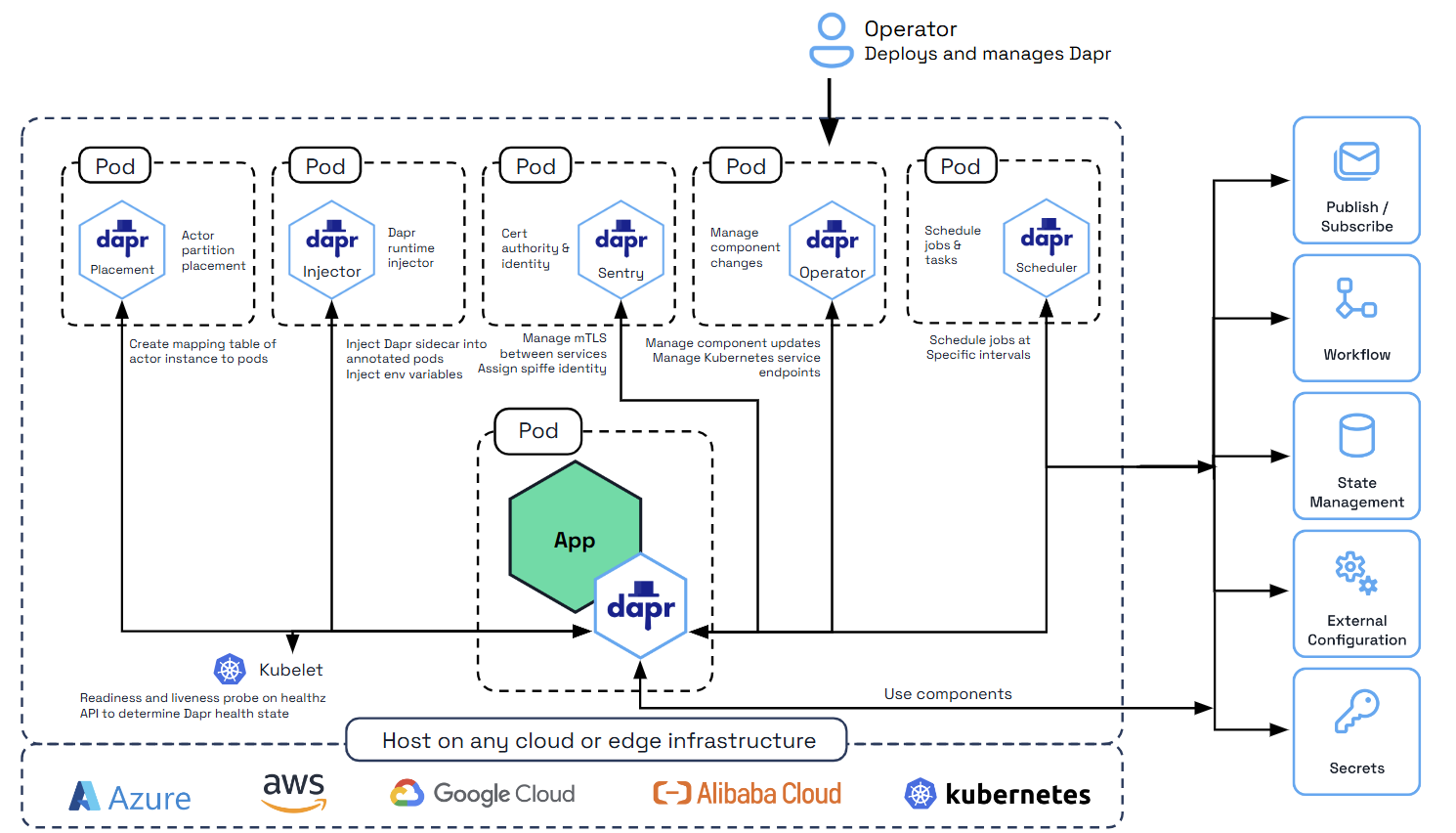
Dapr sidecar 健康端点如何与 Kubernetes 配置
如上所述,此配置由 Sidecar 注入器服务自动完成。本节描述了在存活和就绪探针上设置的具体值。
Dapr 在端口 3500 上有其 HTTP 健康端点 /v1.0/healthz。这可以与 Kubernetes 一起用于就绪和存活探针。当 Dapr sidecar 被注入时,存活和就绪探针在 pod 配置文件中配置为以下值:
livenessProbe:
httpGet:
path: v1.0/healthz
port: 3500
initialDelaySeconds: 5
periodSeconds: 10
timeoutSeconds : 5
failureThreshold : 3
readinessProbe:
httpGet:
path: v1.0/healthz
port: 3500
initialDelaySeconds: 5
periodSeconds: 10
timeoutSeconds : 5
failureThreshold: 3
延迟优雅关闭
Dapr 提供了一个 dapr.io/block-shutdown-duration 注释或 --dapr-block-shutdown-duration CLI 标志,它会延迟完整的关闭过程,直到指定的持续时间,或直到应用报告为不健康,以较早者为准。
在此期间,所有订阅和输入绑定都会关闭。这对于需要在其自身关闭过程中使用 Dapr API 的应用程序非常有用。
适用的注释或 CLI 标志包括:
--dapr-graceful-shutdown-seconds/dapr.io/graceful-shutdown-seconds--dapr-block-shutdown-duration/dapr.io/block-shutdown-duration
在 注释和参数指南 中了解更多关于这些及其使用方法。