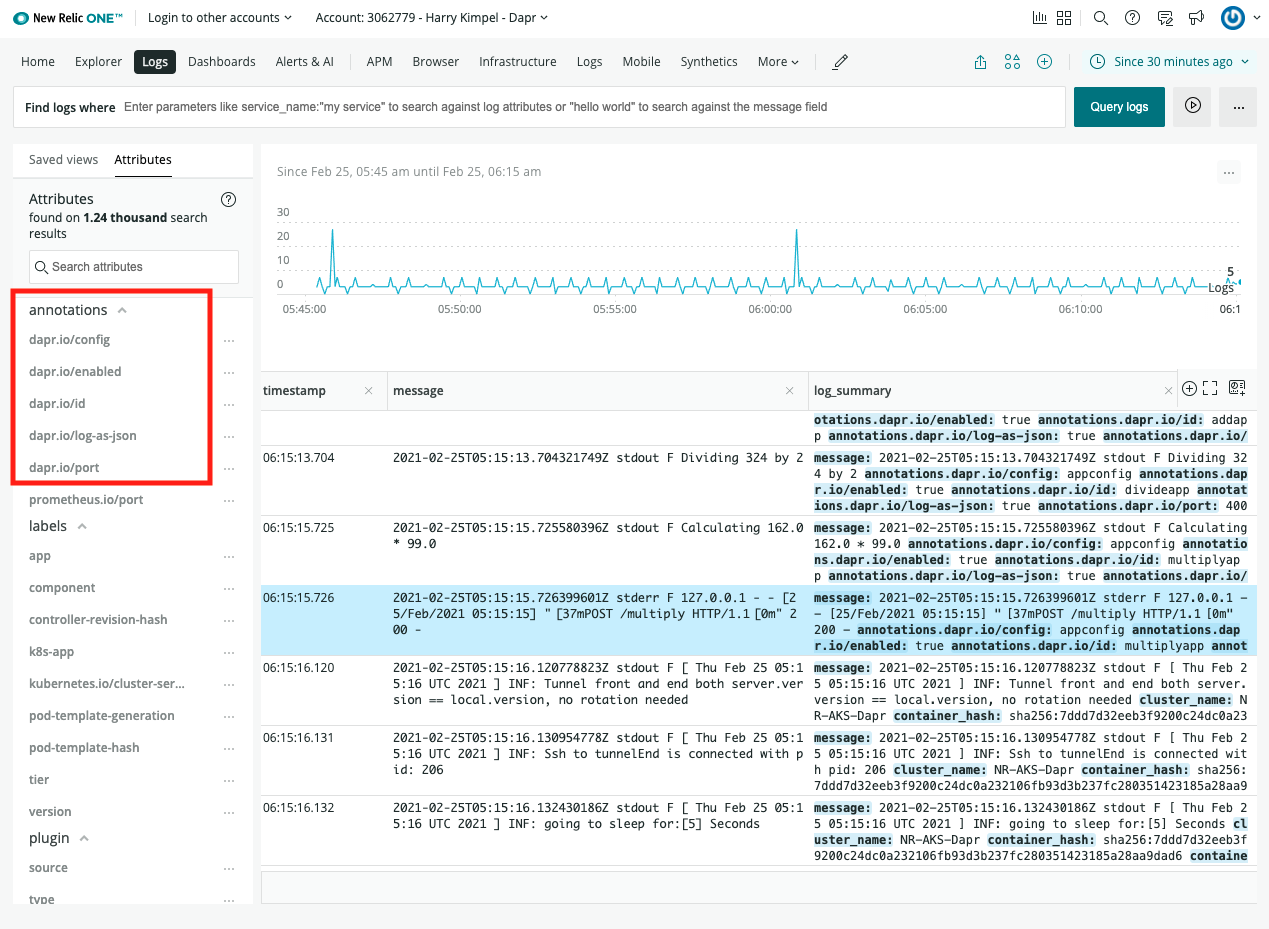
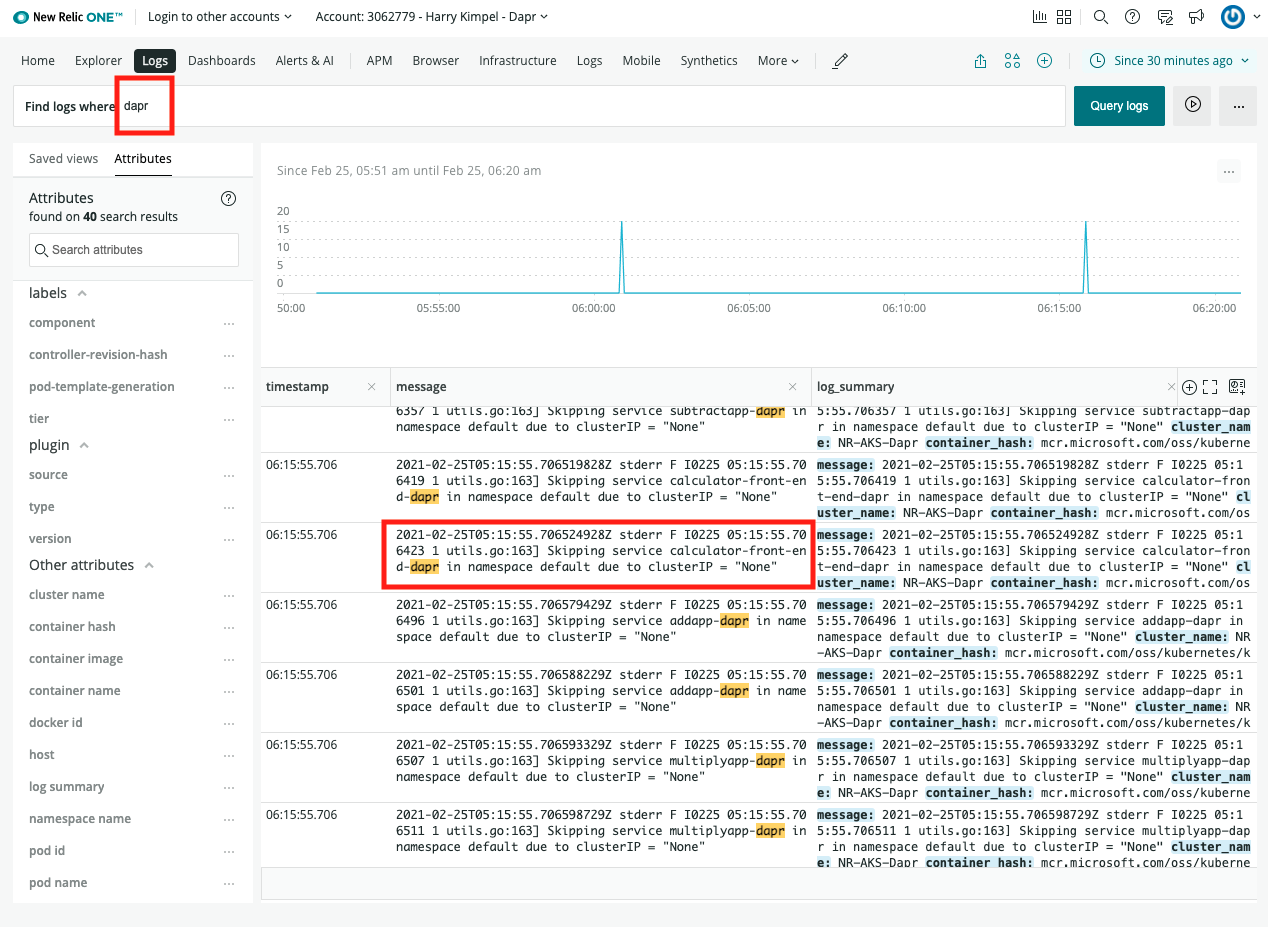
下面的视频和演示概述了Dapr中的可观测性是如何工作的。
This is the multi-page printable view of this section. Click here to print.
可观测性
观察和测量组件的消息调用以及网络服务之间的消息调用
- 1: 代码跟踪
- 1.1: 分布式追踪概述
- 1.2: W3C 跟踪上下文概述
- 1.3: 配置 Dapr 发送分布式追踪数据
- 1.4: Open Telemetry Collector
- 1.4.1: 使用 OpenTelemetry Collector 收集追踪
- 1.4.2: 使用 OpenTelemetry Collector 将跟踪信息发送到应用程序洞察
- 1.4.3: 使用 OpenTelemetry Collector 收集追踪信息并发送到 Jaeger
- 1.5: 操作指南:配置 New Relic 进行分布式追踪
- 1.6: 操作指南:设置 Zipkin 进行分布式追踪
- 1.7: 操作指南:为分布式追踪设置 Datadog
- 2: 监控指标
- 2.1: 操作指南:使用 Prometheus 监控指标
- 2.2: 配置指标
- 2.3: 如何使用Grafana监控指标
- 2.4: 操作指南:配置 New Relic 以收集和分析指标
- 2.5: 操作指南:配置 Azure Monitor 以搜索日志和收集指标
- 3: 日志记录
1 - 代码跟踪
了解代码跟踪的应用场景及如何利用其提升应用程序的监控能力
1.1 - 分布式追踪概述
使用追踪技术获取应用程序可见性的概述
Dapr 通过 Open Telemetry (OTEL) 和 Zipkin 协议来实现分布式追踪。OTEL 是行业标准,并且是推荐使用的追踪协议。
大多数可观测性工具支持 OTEL,包括:
下图展示了 Dapr(使用 OTEL 和 Zipkin 协议)如何与多个可观测性工具集成。
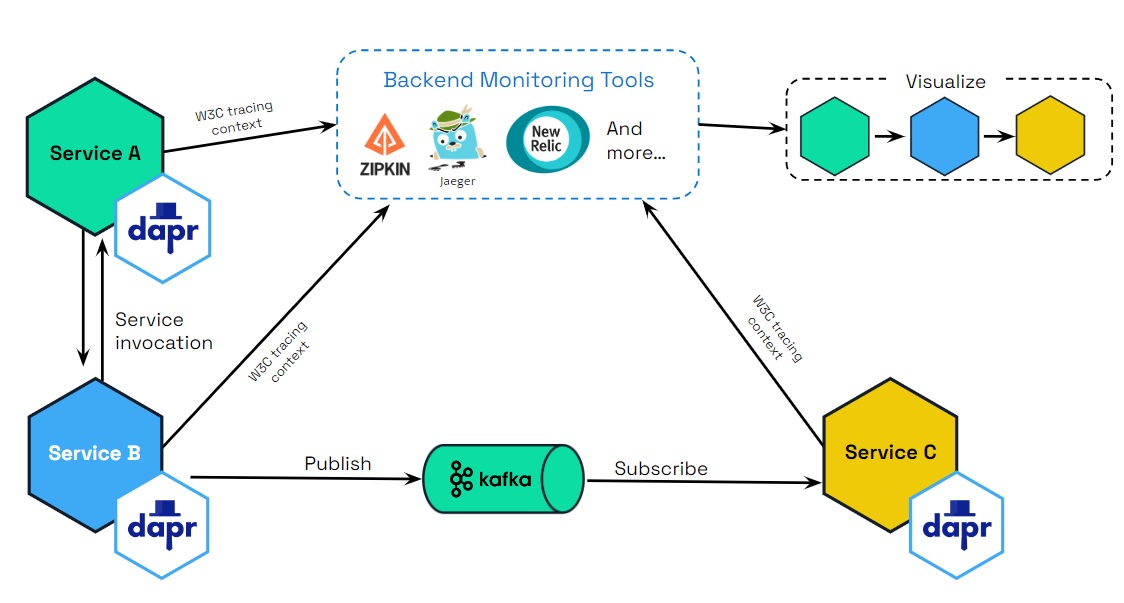
场景
追踪用于服务调用和发布/订阅(pubsub)API。您可以在使用这些 API 的服务之间传递追踪上下文。追踪的使用有两种场景:
- Dapr 生成追踪上下文,您将追踪上下文传递到另一个服务。
- 您生成追踪上下文,Dapr 将追踪上下文传递到服务。
场景 1:Dapr 生成追踪上下文头
顺序服务调用的传递
Dapr 负责创建追踪头。然而,当有两个以上的服务时,您需要负责在它们之间传递追踪头。让我们通过示例来了解这些场景:
单一服务调用
例如,服务 A -> 服务 B。
Dapr 在 服务 A 中生成追踪头,然后从 服务 A 传递到 服务 B。不需要进一步的传递。
多个顺序服务调用
例如,服务 A -> 服务 B -> 传递追踪头到 -> 服务 C,以及其他启用 Dapr 的服务。
Dapr 在请求开始时在 服务 A 中生成追踪头,然后传递到 服务 B。您现在需要负责获取头并将其传递到 服务 C,因为这与您的应用程序特定相关。
换句话说,如果应用程序调用 Dapr 并希望使用现有的追踪头(span)进行追踪,它必须始终传递到 Dapr(在此示例中,从 服务 B 到 服务 C)。Dapr 始终将追踪 span 传递到应用程序。
注意
Dapr SDK 中没有公开的辅助方法来传递和检索追踪上下文。您需要使用 HTTP/gRPC 客户端通过 HTTP 头和 gRPC 元数据传递和检索追踪头。请求来自外部端点
例如,从网关服务到启用 Dapr 的服务 A。
外部网关入口调用 Dapr,Dapr 生成追踪头并调用 服务 A。服务 A 然后调用 服务 B 和其他启用 Dapr 的服务。
您必须从 服务 A 传递头到 服务 B。例如:入口 -> 服务 A -> 传递追踪头 -> 服务 B。这类似于案例 2。
发布/订阅消息
Dapr 在发布的消息主题中生成追踪头。对于 rawPayload 消息,可以指定 traceparent 头以传递追踪信息。这些追踪头会传递到任何监听该主题的服务。
多个不同服务调用的传递
在以下场景中,Dapr 为您完成了一些工作,您需要创建或传递追踪头。
从单个服务调用多个不同的服务
当您从单个服务调用多个服务时,您需要传递追踪头。例如:
服务 A -> 服务 B
[ .. 一些代码逻辑 ..]
服务 A -> 服务 C
[ .. 一些代码逻辑 ..]
服务 A -> 服务 D
[ .. 一些代码逻辑 ..]
在这种情况下:
- 当
服务 A首次调用服务 B时,Dapr 在服务 A中生成追踪头。 服务 A中的追踪头被传递到服务 B。- 这些追踪头作为响应头的一部分在
服务 B的响应中返回。 - 然后,您需要将返回的追踪上下文传递到下一个服务,如
服务 C和服务 D,因为 Dapr 不知道您想要重用相同的头。
场景 2:您从非 Dapr 化应用程序生成自己的追踪上下文头
生成您自己的追踪上下文头较为少见,并且在调用 Dapr 时通常不需要。
然而,在某些场景中,您可能会特别选择在服务调用中添加 W3C 追踪头。例如,您有一个不使用 Dapr 的现有应用程序。在这种情况下,Dapr 仍然为您传递追踪上下文头。
如果您决定自己生成追踪头,可以通过三种方式完成:
标准 OpenTelemetry SDK
您可以使用行业标准的 OpenTelemetry SDKs 生成追踪头,并将这些追踪头传递到启用 Dapr 的服务。这是首选方法。
供应商 SDK
您可以使用提供生成 W3C 追踪头的方法的供应商 SDK,并将其传递到启用 Dapr 的服务。
W3C 追踪上下文
您可以根据 W3C 追踪上下文规范 手工制作追踪上下文,并将其传递到启用 Dapr 的服务。
阅读 追踪上下文概述 以获取有关 W3C 追踪上下文和头的更多背景和示例。
相关链接
1.2 - W3C 跟踪上下文概述
了解如何在 Dapr 中使用 W3C 跟踪上下文和头信息进行分布式跟踪
Dapr 采用 Open Telemetry 协议,该协议利用 W3C 跟踪上下文 来实现服务调用和发布/订阅消息的分布式跟踪。Dapr 生成并传播跟踪上下文信息,可以将其发送到可观测性工具进行可视化和查询。
背景
分布式跟踪是一种由跟踪工具实现的方法,用于跟踪、分析和调试跨多个软件组件的事务。
通常,分布式跟踪会跨越多个服务,因此需要一个唯一的标识符来标识每个事务。跟踪上下文传播就是传递这种唯一标识符的过程。
过去,不同的跟踪供应商各自实现自己的跟踪上下文传播方式。在多供应商环境中,这会导致互操作性的问题,例如:
- 不同供应商收集的跟踪数据无法关联,因为没有共享的唯一标识符。
- 跨越不同供应商边界的跟踪无法传播,因为没有统一的标识符集。
- 中间商可能会丢弃供应商特定的元数据。
- 云平台供应商、中间商和服务提供商无法保证支持跟踪上下文传播,因为没有标准可循。
以前,大多数应用程序由单一的跟踪供应商监控,并保持在单一平台提供商的边界内,因此这些问题没有显著影响。
如今,越来越多的应用程序是分布式的,并利用多个中间件服务和云平台。这种现代应用程序的转变需要一个分布式跟踪上下文传播标准。
W3C 跟踪上下文规范 定义了一种通用格式,用于交换跟踪上下文数据(称为跟踪上下文)。通过提供以下内容,跟踪上下文解决了上述问题:
- 为单个跟踪和请求提供唯一标识符,允许将多个供应商的跟踪数据链接在一起。
- 提供一种机制来转发供应商特定的跟踪数据,避免在单个事务中多个跟踪工具参与时出现断裂的跟踪。
- 一个中间商、平台和硬件供应商可以支持的行业标准。
这种统一的跟踪数据传播方法提高了对分布式应用程序行为的可见性,促进了问题和性能分析。
W3C 跟踪上下文和头格式
W3C 跟踪上下文
Dapr 使用标准的 W3C 跟踪上下文头。
- 对于 HTTP 请求,Dapr 使用
traceparent头。 - 对于 gRPC 请求,Dapr 使用
grpc-trace-bin头。
当请求到达时没有跟踪 ID,Dapr 会创建一个新的。否则,它会沿调用链传递跟踪 ID。
W3C 跟踪头
这些是 Dapr 为 HTTP 和 gRPC 生成和传播的特定跟踪上下文头。
在从 HTTP 响应传播跟踪上下文头到 HTTP 请求时复制这些头:
Traceparent 头
Traceparent 头以所有供应商都能理解的通用格式表示跟踪系统中的传入请求:
traceparent: 00-0af7651916cd43dd8448eb211c80319c-b7ad6b7169203331-01
Tracestate 头
Tracestate 头以可能是供应商特定的格式包含父级:
tracestate: congo=t61rcWkgMzE
在 gRPC API 调用中,跟踪上下文通过 grpc-trace-bin 头传递。
相关链接
1.3 - 配置 Dapr 发送分布式追踪数据
设置 Dapr 发送分布式追踪数据
注意
建议在任何生产环境中启用 Dapr 的追踪功能。您可以根据运行环境配置 Dapr,将追踪和遥测数据发送到多种可观测性工具,无论是在云端还是本地。配置
在 Configuration 规范中的 tracing 部分包含以下属性:
spec:
tracing:
samplingRate: "1"
otel:
endpointAddress: "myendpoint.cluster.local:4317"
zipkin:
endpointAddress: "https://..."
下表列出了追踪的属性:
| 属性 | 类型 | 描述 |
|---|---|---|
samplingRate | string | 设置追踪的采样率来启用或禁用追踪。 |
stdout | bool | 如果为真,则会将更详细的信息写入追踪。 |
otel.endpointAddress | string | 设置 Open Telemetry (OTEL) 目标主机名和可选端口。如果使用此项,则无需指定 ‘zipkin’ 部分。 |
otel.isSecure | bool | 指定连接到端点地址的连接是否加密。 |
otel.protocol | string | 设置为 http 或 grpc 协议。 |
zipkin.endpointAddress | string | 设置 Zipkin 服务器 URL。如果使用此项,则无需指定 otel 部分。 |
要启用追踪,请使用配置文件(在 selfhost 模式下)或 Kubernetes 配置对象(在 Kubernetes 模式下)。例如,以下配置对象将采样率设置为 1(每个 span 都被采样),并使用 OTEL 协议将追踪发送到本地的 OTEL 服务器 localhost:4317。
apiVersion: dapr.io/v1alpha1
kind: Configuration
metadata:
name: tracing
spec:
tracing:
samplingRate: "1"
otel:
endpointAddress: "localhost:4317"
isSecure: false
protocol: grpc
采样率
Dapr 使用概率采样。采样率定义了追踪 span 被采样的概率,值可以在 0 到 1 之间(包括 0 和 1)。默认采样率为 0.0001(即每 10,000 个 span 中采样 1 个)。
将 samplingRate 设置为 0 将完全禁用追踪。
环境变量
OpenTelemetry (otel) 端点也可以通过环境变量进行配置。设置 OTEL_EXPORTER_OTLP_ENDPOINT 环境变量将为 sidecar 启用追踪。
| 环境变量 | 描述 |
|---|---|
OTEL_EXPORTER_OTLP_ENDPOINT | 设置 Open Telemetry (OTEL) 服务器主机名和可选端口,启用追踪 |
OTEL_EXPORTER_OTLP_INSECURE | 将连接设置为未加密(true/false) |
OTEL_EXPORTER_OTLP_PROTOCOL | 传输协议(grpc、http/protobuf、http/json) |
下一步
了解如何使用以下工具之一设置追踪:
1.4 - Open Telemetry Collector
如何配置您的监控工具以接收应用程序追踪数据
1.4.1 - 使用 OpenTelemetry Collector 收集追踪
如何使用 Dapr 通过 OpenTelemetry Collector 推送追踪事件。
Dapr 推荐使用 OpenTelemetry (OTLP) 协议来写入追踪数据。对于直接支持 OTLP 的可观测性工具,建议使用 OpenTelemetry Collector,因为它可以快速卸载数据,并提供重试、批处理和加密等功能。更多信息请参阅 Open Telemetry Collector 的文档。
Dapr 也支持使用 Zipkin 协议来写入追踪数据。在 OTLP 协议支持之前,Zipkin 协议与 OpenTelemetry Collector 一起使用,以将追踪数据发送到 AWS X-Ray、Google Cloud Operations Suite 和 Azure Monitor 等可观测性工具。虽然两种协议都有效,但推荐使用 OpenTelemetry 协议。
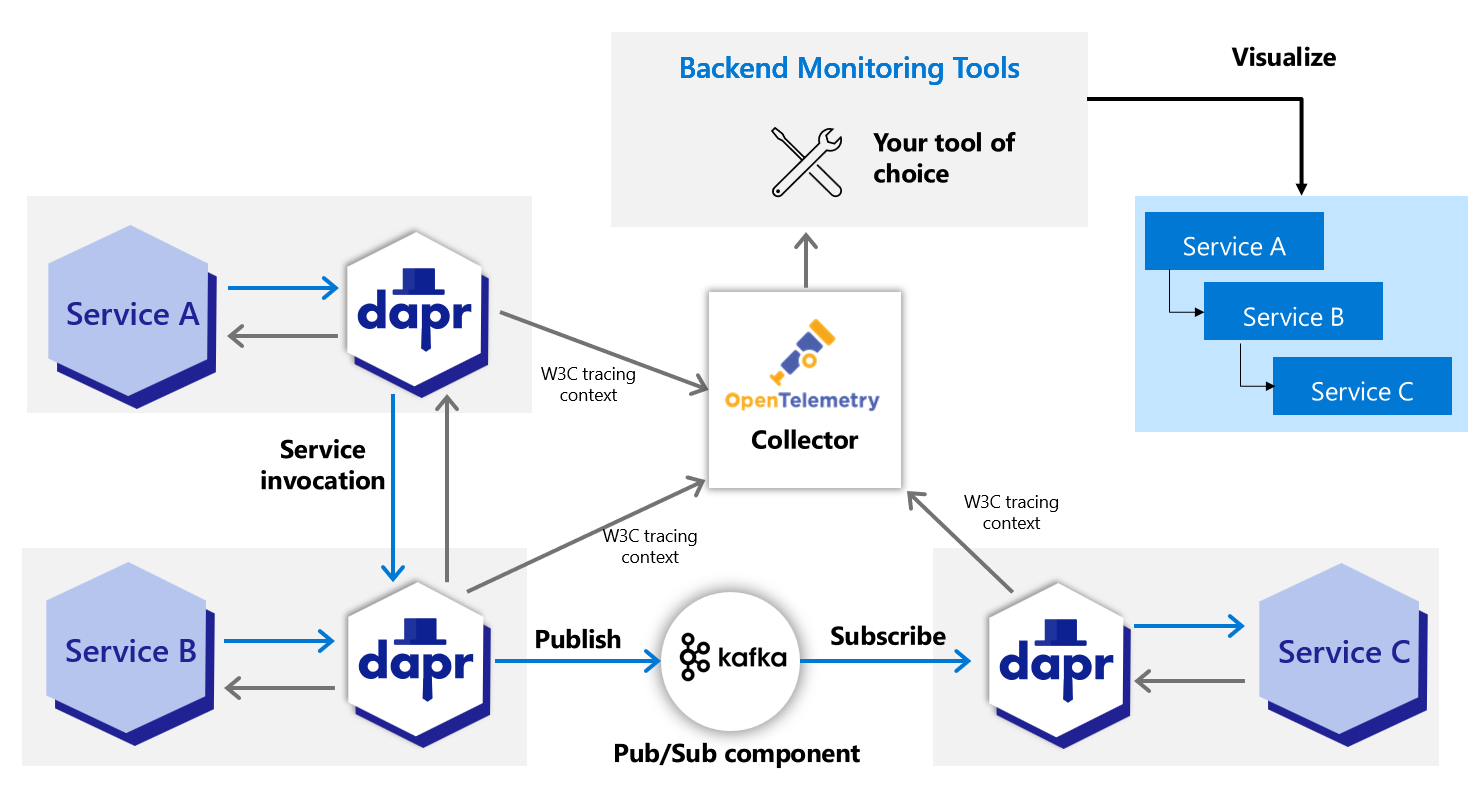
先决条件
- 在 Kubernetes 上安装 Dapr
- 确保您的追踪后端已准备好接收追踪数据
- 查看 OTEL Collector 导出器所需的参数:
配置 OTEL Collector 推送追踪数据到您的后端
将
<your-exporter-here>替换为您的追踪导出器的实际配置。- 请参考先决条件部分中的 OTEL Collector 链接以获取正确的配置。
使用以下命令应用配置:
kubectl apply -f open-telemetry-collector-generic.yaml
配置 Dapr 发送追踪数据到 OTEL Collector
创建一个 Dapr 配置文件以启用追踪,并部署一个使用 OpenTelemetry Collector 的追踪导出器组件。
使用此
collector-config.yaml文件创建您的配置。使用以下命令应用配置:
kubectl apply -f collector-config.yaml
部署应用程序并启用追踪
在需要参与分布式追踪的容器中添加 dapr.io/config 注解以应用 appconfig 配置,如下所示:
apiVersion: apps/v1
kind: Deployment
metadata:
...
spec:
...
template:
metadata:
...
annotations:
dapr.io/enabled: "true"
dapr.io/app-id: "MyApp"
dapr.io/app-port: "8080"
dapr.io/config: "appconfig"
您可以同时注册多个追踪导出器,追踪数据将被转发到所有注册的导出器。
就是这样!无需包含任何 SDK 或对您的应用程序代码进行修改。Dapr 会自动为您处理分布式追踪。
查看追踪
部署并运行一些应用程序。等待追踪数据传播到您的追踪后端并在那里查看它们。
相关链接
1.4.2 - 使用 OpenTelemetry Collector 将跟踪信息发送到应用程序洞察
如何使用 OpenTelemetry Collector 将跟踪事件推送到 Azure 应用程序洞察。
Dapr 使用 Zipkin API 集成了 OpenTelemetry (OTEL) Collector。本指南演示了如何通过 Dapr 使用 OpenTelemetry Collector 将跟踪事件推送到 Azure 应用程序洞察。
前提条件
- 在 Kubernetes 上安装 Dapr
- 设置一个应用程序洞察资源并记录下你的应用程序洞察仪器密钥。
配置 OTEL Collector 以推送数据到应用程序洞察
要将事件推送到你的应用程序洞察实例,请在 Kubernetes 集群中安装 OTEL Collector。
用你的应用程序洞察仪器密钥替换
<INSTRUMENTATION-KEY>占位符。使用以下命令应用配置:
kubectl apply -f open-telemetry-collector-appinsights.yaml
配置 Dapr 以发送跟踪数据到 OTEL Collector
创建一个 Dapr 配置文件以启用跟踪,并部署一个使用 OpenTelemetry Collector 的跟踪导出组件。
使用此
collector-config.yaml文件创建你自己的配置。使用以下命令应用配置:
kubectl apply -f collector-config.yaml
部署应用程序并启用跟踪
在你希望参与分布式跟踪的容器中添加 dapr.io/config 注解以应用 appconfig 配置,如下例所示:
apiVersion: apps/v1
kind: Deployment
metadata:
...
spec:
...
template:
metadata:
...
annotations:
dapr.io/enabled: "true"
dapr.io/app-id: "MyApp"
dapr.io/app-port: "8080"
dapr.io/config: "appconfig"
你可以同时注册多个跟踪导出器,跟踪日志会被转发到所有注册的导出器。
就是这样!无需包含任何 SDK 或对你的应用程序代码进行额外的修改。Dapr 会自动为你处理分布式跟踪。
查看跟踪
部署并运行一些应用程序。几分钟后,你应该会在你的应用程序洞察资源中看到跟踪日志。你还可以使用 应用程序地图 来检查你的服务拓扑,如下所示:
注意
只有通过 Dapr sidecar 暴露的 Dapr API(例如,服务调用或事件发布)的操作会显示在应用程序地图拓扑中。相关链接
1.4.3 - 使用 OpenTelemetry Collector 收集追踪信息并发送到 Jaeger
如何使用 OpenTelemetry Collector 将追踪事件推送到 Jaeger 分布式追踪平台。
Dapr 支持通过 OpenTelemetry (OTLP) 和 Zipkin 协议进行追踪信息的写入。然而,由于 Jaeger 对 Zipkin 的支持已被弃用,建议使用 OTLP。虽然 Jaeger 可以直接支持 OTLP,但在生产环境中,推荐使用 OpenTelemetry Collector 从 Dapr 收集追踪信息并发送到 Jaeger。这样可以让您的应用程序更高效地处理数据,并利用重试、批处理和加密等功能。更多信息请阅读 Open Telemetry Collector 文档。
在自托管模式下配置 Jaeger
本地设置
启动 Jaeger 的最简单方法是运行发布到 DockerHub 的预构建的 all-in-one Jaeger 镜像,并暴露 OTLP 端口:
docker run -d --name jaeger \
-p 4317:4317 \
-p 16686:16686 \
jaegertracing/all-in-one:1.49
接下来,在本地创建以下 config.yaml 文件:
注意: 因为您使用 Open Telemetry 协议与 Jaeger 通信,您需要填写追踪配置的
otel部分,并将endpointAddress设置为 Jaeger 容器的地址。
apiVersion: dapr.io/v1alpha1
kind: Configuration
metadata:
name: tracing
namespace: default
spec:
tracing:
samplingRate: "1"
stdout: true
otel:
endpointAddress: "localhost:4317"
isSecure: false
protocol: grpc
要启动引用新 YAML 配置文件的应用程序,请使用 --config 选项。例如:
dapr run --app-id myapp --app-port 3000 node app.js --config config.yaml
查看追踪信息
要在浏览器中查看追踪信息,请访问 http://localhost:16686 查看 Jaeger UI。
在 Kubernetes 上使用 OpenTelemetry Collector 配置 Jaeger
以下步骤展示了如何配置 Dapr 以将分布式追踪数据发送到 OpenTelemetry Collector,然后将追踪信息发送到 Jaeger。
前提条件
- 在 Kubernetes 上安装 Dapr
- 使用 Jaeger Kubernetes Operator 设置 Jaeger
设置 OpenTelemetry Collector 推送到 Jaeger
要将追踪信息推送到您的 Jaeger 实例,请在您的 Kubernetes 集群上安装 OpenTelemetry Collector。
下载并检查
open-telemetry-collector-jaeger.yaml文件。在
otel-collector-confConfigMap 的数据部分,更新otlp/jaeger.endpoint值以匹配您的 Jaeger collector Kubernetes 服务对象的端点。将 OpenTelemetry Collector 部署到运行 Dapr 应用程序的相同命名空间中:
kubectl apply -f open-telemetry-collector-jaeger.yaml
设置 Dapr 发送追踪信息到 OpenTelemetryCollector
创建一个 Dapr 配置文件以启用追踪,并将 sidecar 追踪信息导出到 OpenTelemetry Collector。
使用
collector-config-otel.yaml文件创建您自己的 Dapr 配置。更新
namespace和otel.endpointAddress值以与部署 Dapr 应用程序和 OpenTelemetry Collector 的命名空间对齐。应用配置:
kubectl apply -f collector-config.yaml
部署启用追踪的应用程序
通过在您希望启用分布式追踪的应用程序部署中添加 dapr.io/config 注释来应用 tracing Dapr 配置,如下例所示:
apiVersion: apps/v1
kind: Deployment
metadata:
...
spec:
...
template:
metadata:
...
annotations:
dapr.io/enabled: "true"
dapr.io/app-id: "MyApp"
dapr.io/app-port: "8080"
dapr.io/config: "tracing"
您可以同时注册多个追踪导出器,追踪日志将被转发到所有注册的导出器。
就是这样!无需包含 OpenTelemetry SDK 或对您的应用程序代码进行检测。Dapr 会自动为您处理分布式追踪。
查看追踪信息
要查看 Dapr sidecar 追踪信息,请端口转发 Jaeger 服务并打开 UI:
kubectl port-forward svc/jaeger-query 16686 -n observability
在您的浏览器中,访问 http://localhost:16686,您将看到 Jaeger UI。
参考资料
1.5 - 操作指南:配置 New Relic 进行分布式追踪
配置 New Relic 进行分布式追踪
前提条件
- 需要一个 New Relic 账户,该账户永久免费,每月可免费处理 100 GB 的数据,包含 1 个完全访问用户和无限数量的基本用户。
配置 Dapr 追踪
Dapr 可以直接将其捕获的指标和追踪数据发送到 New Relic。最简单的方式是通过配置 Dapr,将追踪数据以 Zipkin 格式发送到 New Relic 的 Trace API。
为了将数据集成到 New Relic 的 Telemetry Data Platform,您需要一个 New Relic Insights Insert API key。
apiVersion: dapr.io/v1alpha1
kind: Configuration
metadata:
name: appconfig
namespace: default
spec:
tracing:
samplingRate: "1"
zipkin:
endpointAddress: "https://trace-api.newrelic.com/trace/v1?Api-Key=<NR-INSIGHTS-INSERT-API-KEY>&Data-Format=zipkin&Data-Format-Version=2"
查看追踪
New Relic 分布式追踪概览
New Relic 分布式追踪详情
(选择性)New Relic 仪器化
为了将数据集成到 New Relic Telemetry Data Platform,您需要一个 New Relic license key 或 New Relic Insights Insert API key。
OpenTelemetry 仪器化
您可以使用不同语言的 OpenTelemetry 实现,例如 New Relic Telemetry SDK 和 .NET 的 OpenTelemetry 支持。在这种情况下,使用 OpenTelemetry Trace Exporter。示例请参见此处。
New Relic 语言代理
类似于 OpenTelemetry 仪器化,您也可以使用 New Relic 语言代理。例如,.NET Core 的 New Relic 代理仪器化 是 Dockerfile 的一部分。示例请参见此处。
(选择性)启用 New Relic Kubernetes 集成
如果 Dapr 和您的应用程序在 Kubernetes 环境中运行,您可以启用额外的指标和日志。
安装 New Relic Kubernetes 集成的最简单方法是使用 自动安装程序 生成清单。它不仅包含集成 DaemonSets,还包括其他 New Relic Kubernetes 配置,如 Kubernetes 事件、Prometheus OpenMetrics 和 New Relic 日志监控。
New Relic Kubernetes 集群浏览器
New Relic Kubernetes 集群浏览器 提供了一个独特的可视化界面,展示了 Kubernetes 集成收集的所有数据和部署。
这是观察所有数据并深入了解应用程序或微服务内部发生的任何性能问题或事件的良好起点。
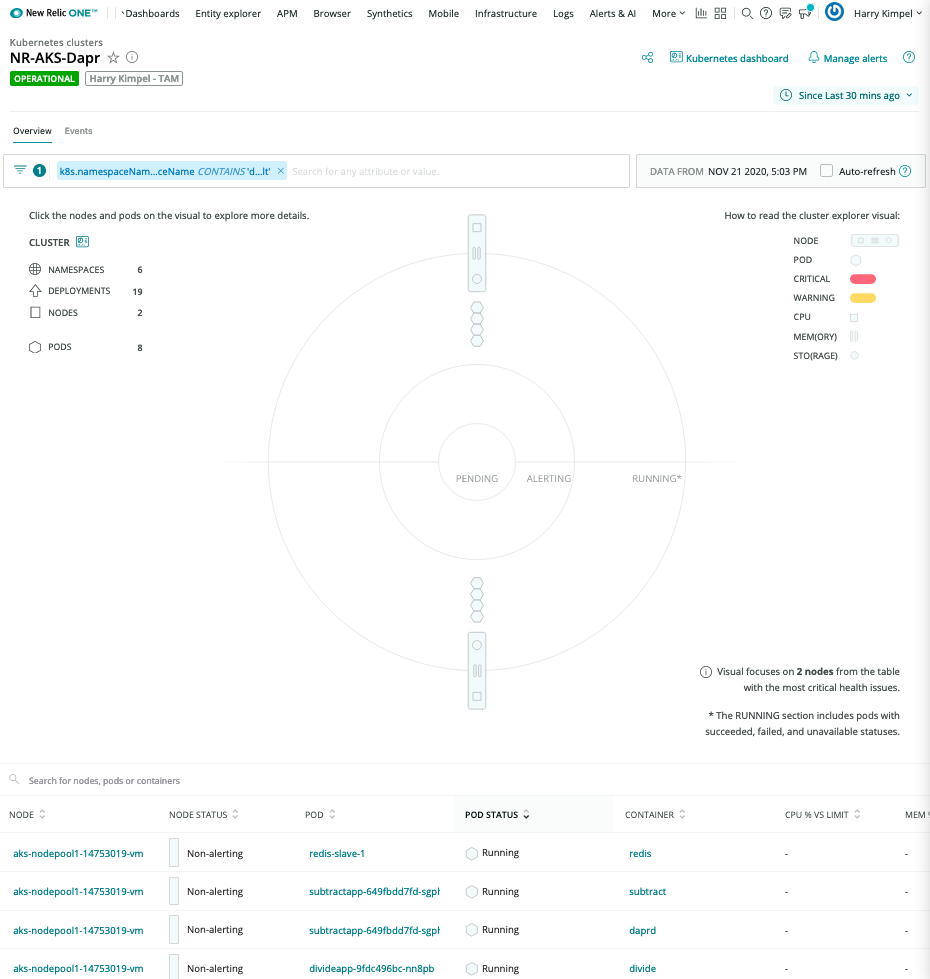
自动关联是 New Relic 可视化功能的一部分。
Pod 级别详情
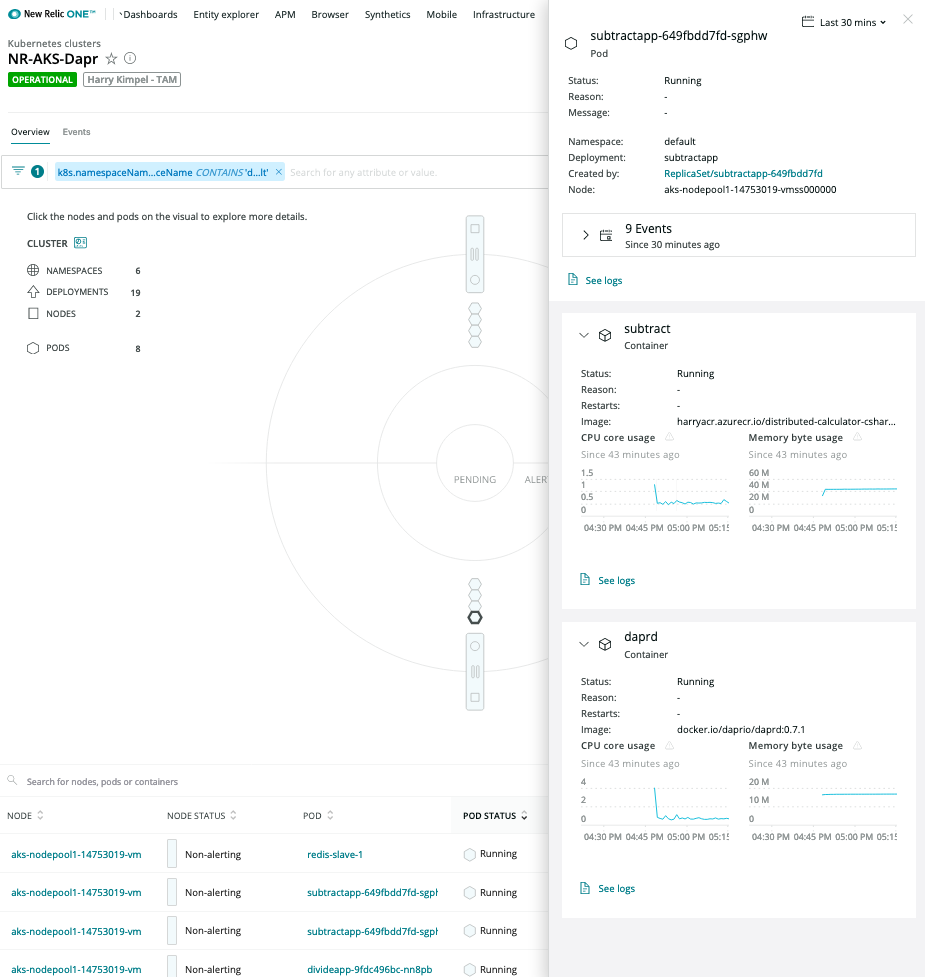
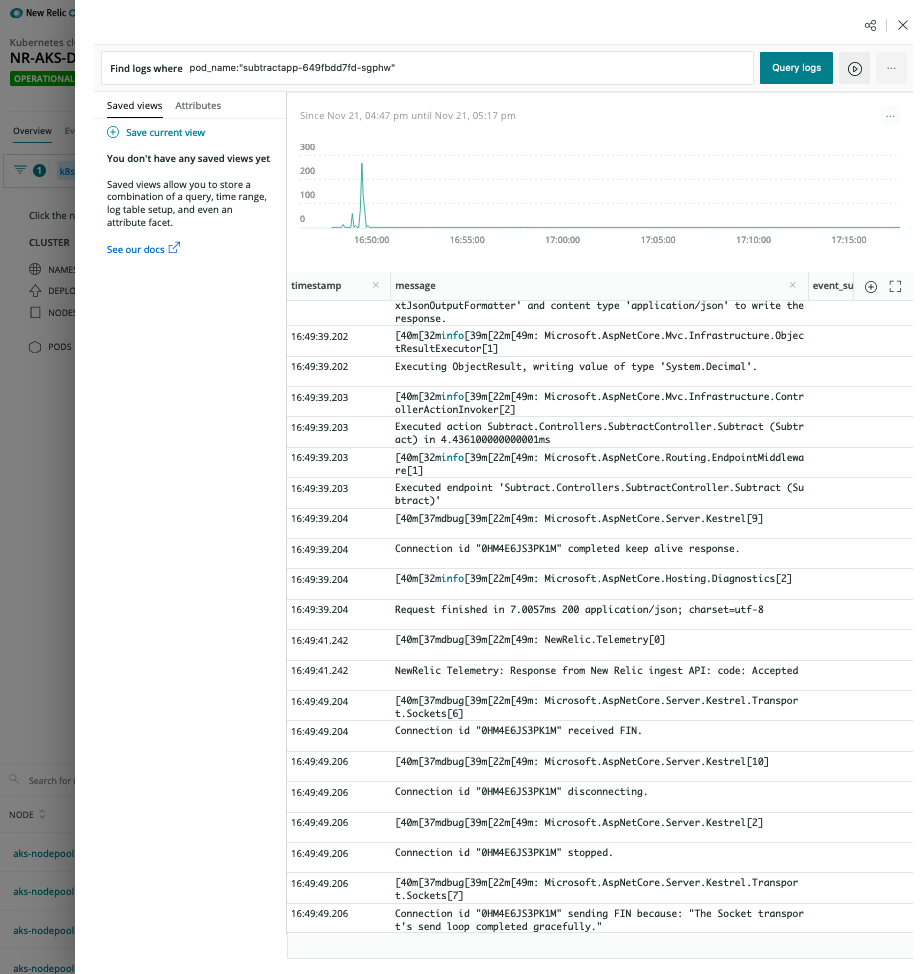
上下文中的日志
New Relic 仪表板
Kubernetes 概览
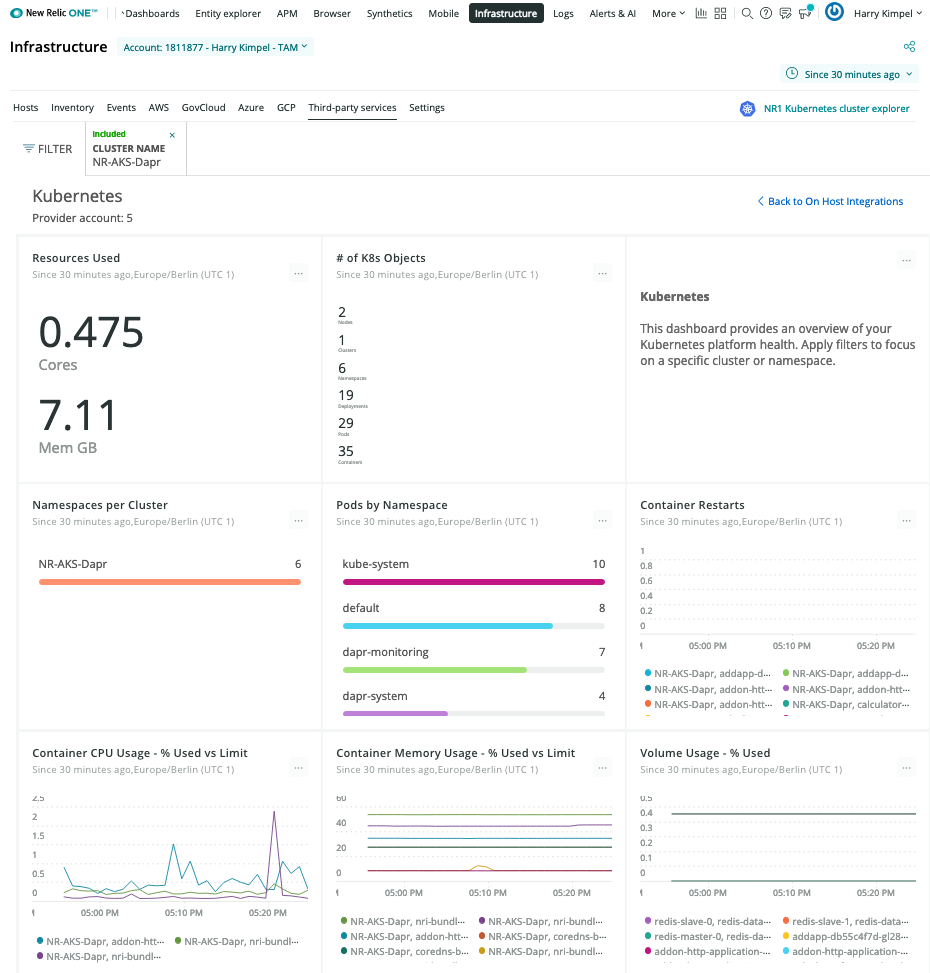
Dapr 系统服务
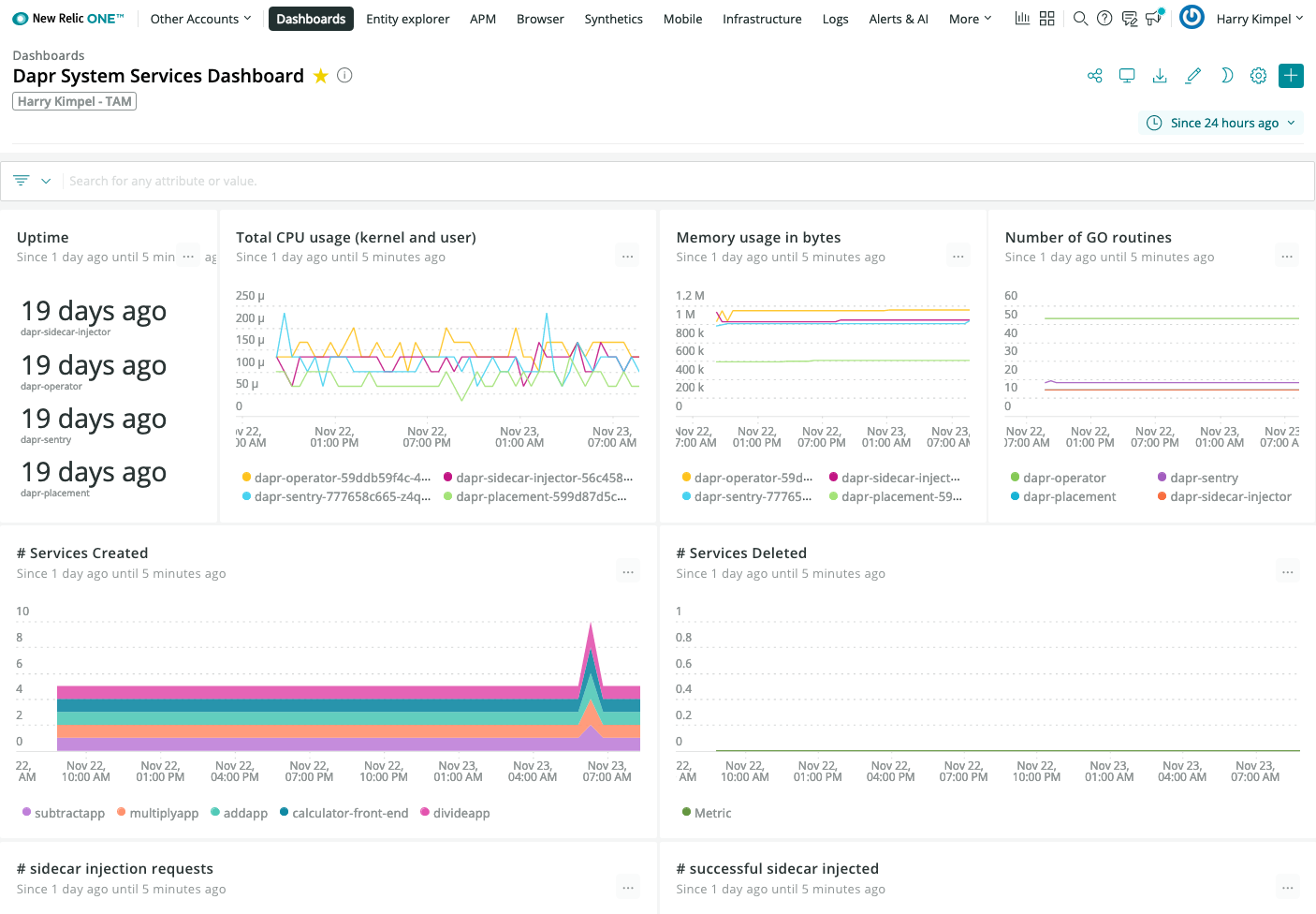
Dapr 指标
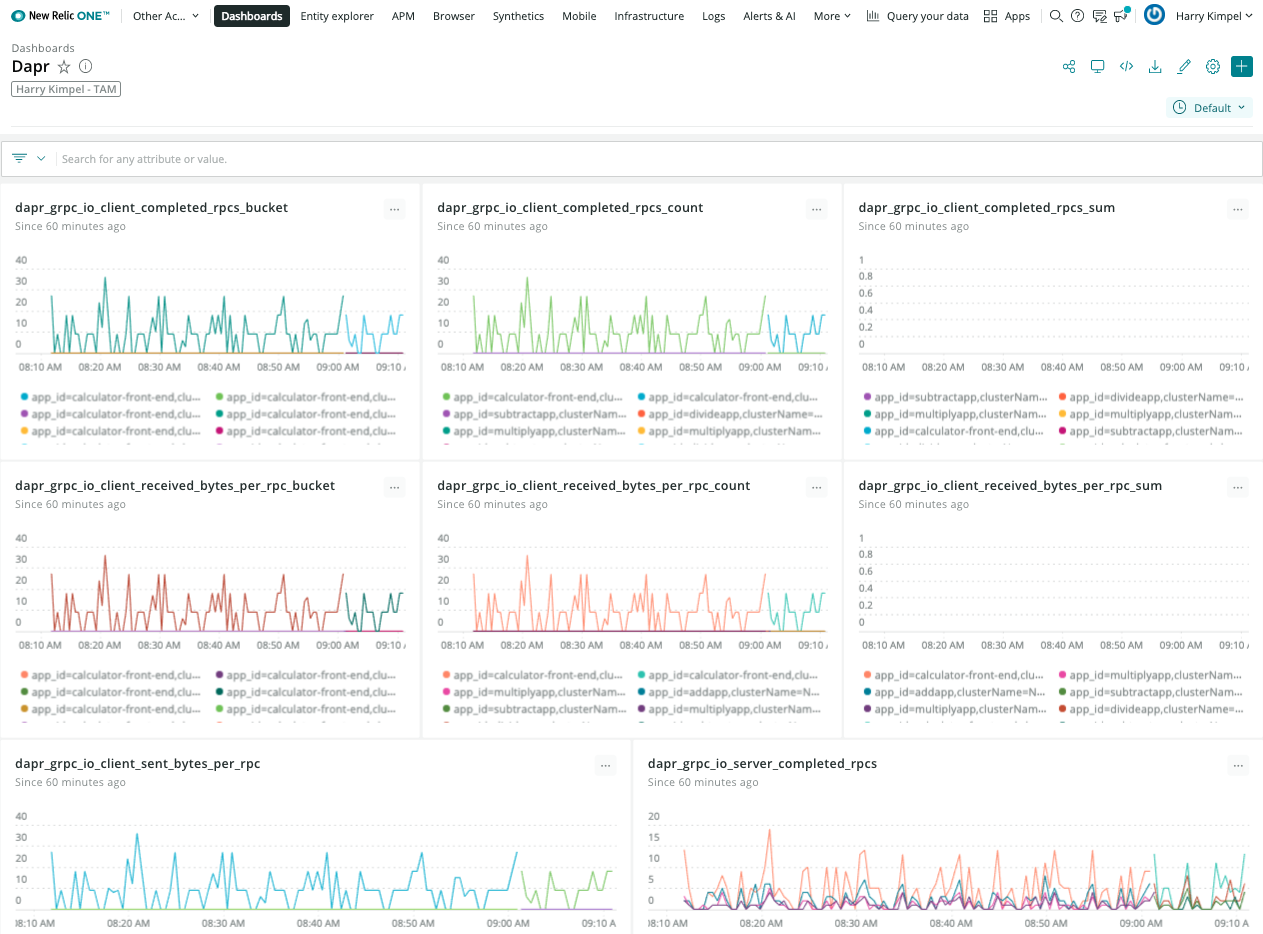
New Relic Grafana 集成
New Relic 与 Grafana Labs 合作,您可以使用 Telemetry Data Platform 作为 Prometheus 指标的数据源,并在现有仪表板中查看它们,轻松利用 New Relic 提供的可靠性、规模和安全性。
用于监控 Dapr 系统服务和 sidecar 的 Grafana 仪表板模板 可以轻松使用,无需任何更改。New Relic 提供了一个 Prometheus 指标的本地端点 到 Grafana。可以轻松设置数据源:
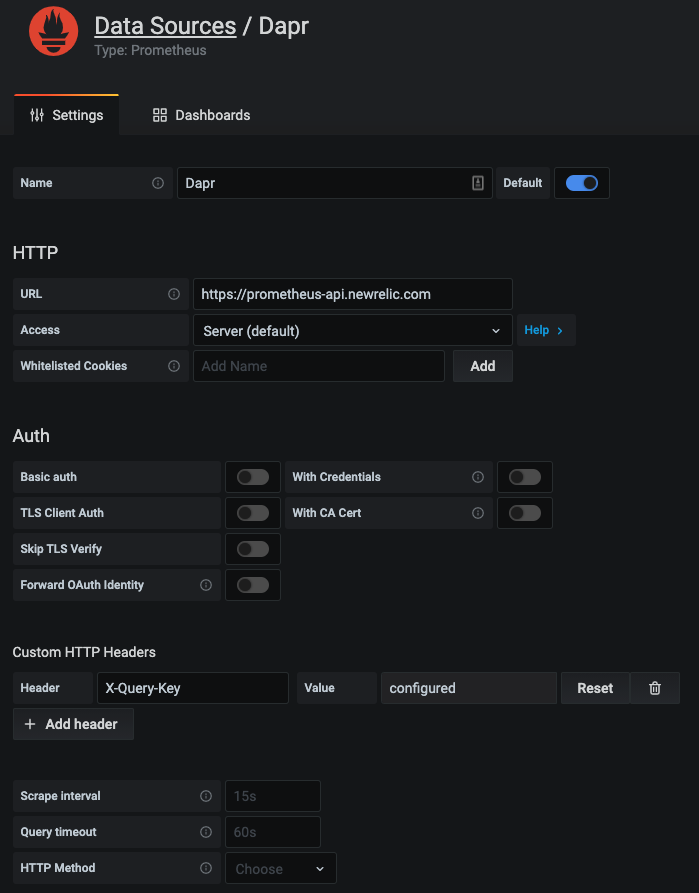
并且可以导入来自 Dapr 的完全相同的仪表板模板,以可视化 Dapr 系统服务和 sidecar。
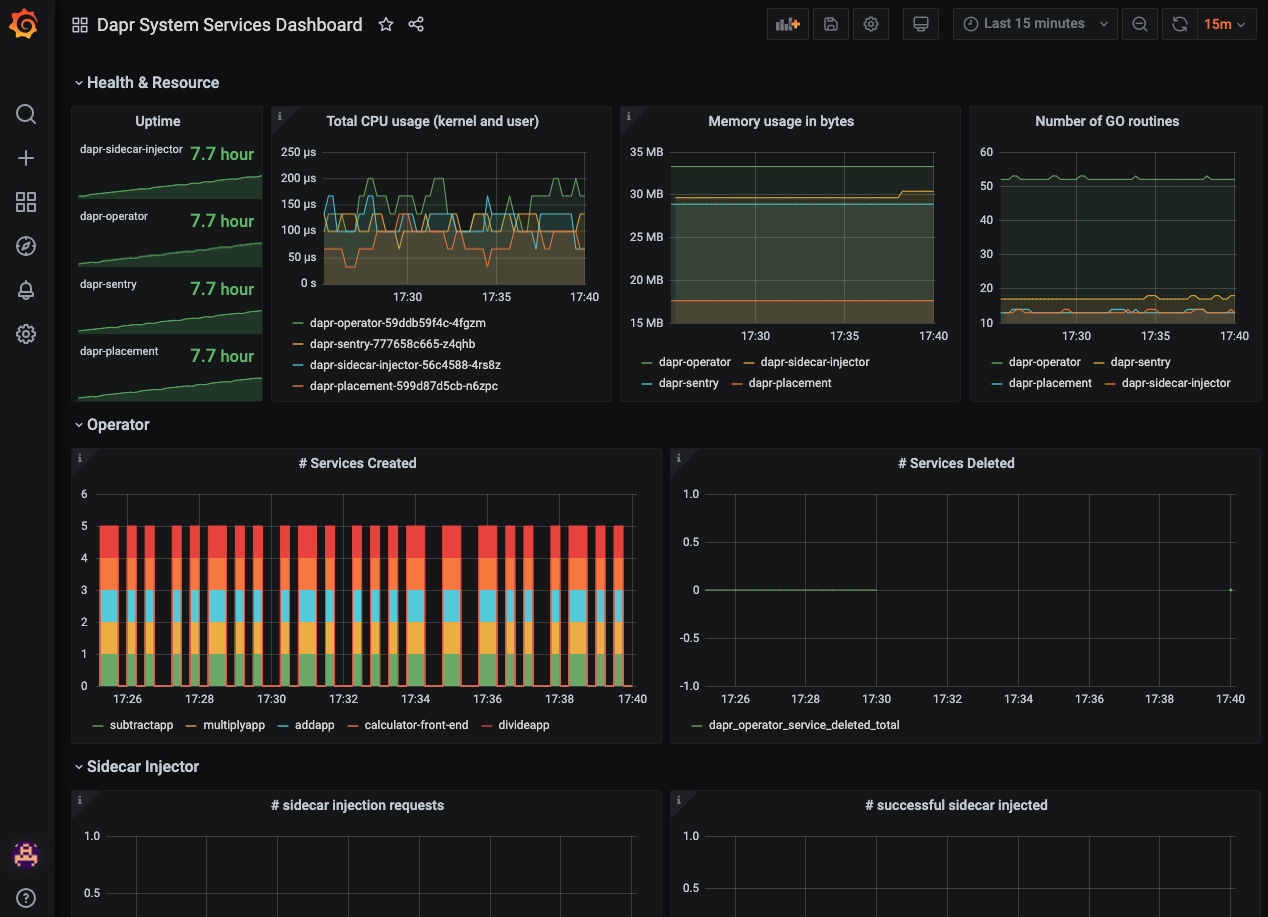
New Relic 警报
从 Dapr、Kubernetes 或任何在其上运行的服务收集的所有数据都可以用于设置警报和通知到您选择的首选渠道。请参见 Alerts and Applied Intelligence。
相关链接/参考
1.6 - 操作指南:设置 Zipkin 进行分布式追踪
设置 Zipkin 进行分布式追踪
配置自托管模式
在自托管模式下,运行 dapr init 时:
- 系统会默认创建一个 YAML 文件,路径为
$HOME/.dapr/config.yaml(Linux/Mac)或%USERPROFILE%\.dapr\config.yaml(Windows)。在执行dapr run时,系统会默认引用该文件,除非您指定了其他配置:
- config.yaml
apiVersion: dapr.io/v1alpha1
kind: Configuration
metadata:
name: daprConfig
namespace: default
spec:
tracing:
samplingRate: "1"
zipkin:
endpointAddress: "http://localhost:9411/api/v2/spans"
- 运行
dapr init时,openzipkin/zipkin 的 Docker 容器会自动启动。您也可以手动启动:
使用 Docker 启动 Zipkin:
docker run -d -p 9411:9411 openzipkin/zipkin
- 使用
dapr run启动应用程序时,默认会引用$HOME/.dapr/config.yaml或%USERPROFILE%\.dapr\config.yaml中的配置文件。您可以通过 Dapr CLI 的--config参数来指定其他配置:
dapr run --app-id mynode --app-port 3000 node app.js
查看追踪
要查看追踪数据,请在浏览器中访问 http://localhost:9411,您将看到 Zipkin 的用户界面。
配置 Kubernetes
以下步骤将指导您如何配置 Dapr,将分布式追踪数据发送到 Kubernetes 集群中的 Zipkin 容器,并查看这些数据。
设置
首先,部署 Zipkin:
kubectl create deployment zipkin --image openzipkin/zipkin
为 Zipkin pod 创建一个 Kubernetes 服务:
kubectl expose deployment zipkin --type ClusterIP --port 9411
接下来,在本地创建以下 YAML 文件:
- tracing.yaml 配置
apiVersion: dapr.io/v1alpha1
kind: Configuration
metadata:
name: tracing
namespace: default
spec:
tracing:
samplingRate: "1"
zipkin:
endpointAddress: "http://zipkin.default.svc.cluster.local:9411/api/v2/spans"
现在,部署 Dapr 配置文件:
kubectl apply -f tracing.yaml
要在 Dapr sidecar 中启用此配置,请在 pod 规范模板中添加以下注释:
annotations:
dapr.io/config: "tracing"
完成!您的 sidecar 现在已配置为将追踪数据发送到 Zipkin。
查看追踪数据
要查看追踪数据,请连接到 Zipkin 服务并打开用户界面:
kubectl port-forward svc/zipkin 9411:9411
在浏览器中,访问 http://localhost:9411,您将看到 Zipkin 的用户界面。
参考资料
1.7 - 操作指南:为分布式追踪设置 Datadog
为分布式追踪设置 Datadog
Dapr 捕获的指标和追踪信息可以通过 OpenTelemetry Collector 的 Datadog 导出器直接发送到 Datadog。
使用 OpenTelemetry Collector 和 Datadog 配置 Dapr 追踪
您可以使用 OpenTelemetry Collector 的 Datadog 导出器来配置 Dapr,为 Kubernetes 集群中的每个应用程序创建追踪,并将这些追踪信息收集到 Datadog 中。
在开始之前,请先设置 OpenTelemetry Collector。
在
datadog导出器的配置部分,将您的 Datadog API 密钥添加到./deploy/opentelemetry-collector-generic-datadog.yaml文件中:data: otel-collector-config: ... exporters: ... datadog: api: key: <YOUR_API_KEY>运行以下命令以应用
opentelemetry-collector的配置。kubectl apply -f ./deploy/open-telemetry-collector-generic-datadog.yaml设置一个 Dapr 配置文件以启用追踪,并部署一个使用 OpenTelemetry Collector 的追踪导出器组件。
kubectl apply -f ./deploy/collector-config.yaml在您希望参与分布式追踪的容器中添加
dapr.io/config注解,以应用appconfig配置。annotations: dapr.io/config: "appconfig"创建并配置应用程序。应用程序运行后,遥测数据将被发送到 Datadog,并可以在 Datadog APM 中查看。
相关链接/参考
2 - 监控指标
如何查看和理解Dapr的监控指标
2.1 - 操作指南:使用 Prometheus 监控指标
使用 Prometheus 收集与 Dapr 运行时执行相关的时间序列数据
本地设置 Prometheus
在本地计算机上,您可以选择安装并作为进程运行 Prometheus,或者将其作为Docker 容器运行。
安装
注意
如果您计划将 Prometheus 作为 Docker 容器运行,则无需单独安装 Prometheus。请参阅容器部分的说明。请按照此处提供的步骤,根据您的操作系统安装 Prometheus。
配置
安装完成后,您需要创建一个配置文件。
以下是一个示例 Prometheus 配置,请将其保存为文件,例如 /tmp/prometheus.yml 或 C:\Temp\prometheus.yml:
global:
scrape_interval: 15s # 默认情况下,每 15 秒收集一次指标。
# 包含一个收集端点的配置:
# 这里是 Prometheus 自身。
scrape_configs:
- job_name: 'dapr'
# 覆盖全局默认值,每 5 秒从此 job 收集指标。
scrape_interval: 5s
static_configs:
- targets: ['localhost:9090'] # 如果不是默认值,请替换为 Dapr 指标端口
作为进程运行
使用您的配置文件运行 Prometheus,以开始从指定目标收集指标。
./prometheus --config.file=/tmp/prometheus.yml --web.listen-address=:8080
我们更改了端口以避免与 Dapr 自身的指标端点冲突。
如果您当前没有运行 Dapr 应用程序,目标将显示为离线。要开始收集指标,您必须启动 Dapr,并确保其指标端口与配置中指定的目标一致。
一旦 Prometheus 运行,您可以通过访问 http://localhost:8080 来查看其仪表板。
作为容器运行
要在本地计算机上将 Prometheus 作为 Docker 容器运行,首先确保已安装并运行 Docker。
然后可以使用以下命令将 Prometheus 作为 Docker 容器运行:
docker run \
--net=host \
-v /tmp/prometheus.yml:/etc/prometheus/prometheus.yml \
prom/prometheus --config.file=/etc/prometheus/prometheus.yml --web.listen-address=:8080
--net=host 确保 Prometheus 实例能够连接到在主机上运行的任何 Dapr 实例。如果您计划也在容器中运行 Dapr 应用程序,则需要在共享的 Docker 网络上运行它们,并使用正确的目标地址更新配置。
一旦 Prometheus 运行,您可以通过访问 http://localhost:8080 来查看其仪表板。
在 Kubernetes 上设置 Prometheus
先决条件
安装 Prometheus
- 首先创建一个命名空间,用于部署 Grafana 和 Prometheus 监控工具
kubectl create namespace dapr-monitoring
- 安装 Prometheus
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update
helm install dapr-prom prometheus-community/prometheus -n dapr-monitoring
如果您是 Minikube 用户或想要禁用持久卷以进行开发,可以使用以下命令禁用它。
helm install dapr-prom prometheus-community/prometheus -n dapr-monitoring
--set alertmanager.persistence.enabled=false --set pushgateway.persistentVolume.enabled=false --set server.persistentVolume.enabled=false
要自动发现 Dapr 目标(服务发现),请使用:
helm install dapr-prom prometheus-community/prometheus -f values.yaml -n dapr-monitoring --create-namespace
values.yaml 文件
alertmanager:
persistence:
enabled: false
pushgateway:
persistentVolume:
enabled: false
server:
persistentVolume:
enabled: false
# 向 prometheus.yml 添加额外的收集配置
# 使用服务发现找到 Dapr 和 Dapr sidecar 目标
extraScrapeConfigs: |-
- job_name: dapr-sidecars
kubernetes_sd_configs:
- role: pod
relabel_configs:
- action: keep
regex: "true"
source_labels:
- __meta_kubernetes_pod_annotation_dapr_io_enabled
- action: keep
regex: "true"
source_labels:
- __meta_kubernetes_pod_annotation_dapr_io_enable_metrics
- action: replace
replacement: ${1}
source_labels:
- __meta_kubernetes_namespace
target_label: namespace
- action: replace
replacement: ${1}
source_labels:
- __meta_kubernetes_pod_name
target_label: pod
- action: replace
regex: (.*);daprd
replacement: ${1}-dapr
source_labels:
- __meta_kubernetes_pod_annotation_dapr_io_app_id
- __meta_kubernetes_pod_container_name
target_label: service
- action: replace
replacement: ${1}:9090
source_labels:
- __meta_kubernetes_pod_ip
target_label: __address__
- job_name: dapr
kubernetes_sd_configs:
- role: pod
relabel_configs:
- action: keep
regex: dapr
source_labels:
- __meta_kubernetes_pod_label_app_kubernetes_io_name
- action: keep
regex: dapr
source_labels:
- __meta_kubernetes_pod_label_app_kubernetes_io_part_of
- action: replace
replacement: ${1}
source_labels:
- __meta_kubernetes_pod_label_app
target_label: app
- action: replace
replacement: ${1}
source_labels:
- __meta_kubernetes_namespace
target_label: namespace
- action: replace
replacement: ${1}
source_labels:
- __meta_kubernetes_pod_name
target_label: pod
- action: replace
replacement: ${1}:9090
source_labels:
- __meta_kubernetes_pod_ip
target_label: __address__
- 验证
确保 Prometheus 在您的集群中运行。
kubectl get pods -n dapr-monitoring
预期输出:
NAME READY STATUS RESTARTS AGE
dapr-prom-kube-state-metrics-9849d6cc6-t94p8 1/1 Running 0 4m58s
dapr-prom-prometheus-alertmanager-749cc46f6-9b5t8 2/2 Running 0 4m58s
dapr-prom-prometheus-node-exporter-5jh8p 1/1 Running 0 4m58s
dapr-prom-prometheus-node-exporter-88gbg 1/1 Running 0 4m58s
dapr-prom-prometheus-node-exporter-bjp9f 1/1 Running 0 4m58s
dapr-prom-prometheus-pushgateway-688665d597-h4xx2 1/1 Running 0 4m58s
dapr-prom-prometheus-server-694fd8d7c-q5d59 2/2 Running 0 4m58s
访问 Prometheus 仪表板
要查看 Prometheus 仪表板并检查服务发现:
kubectl port-forward svc/dapr-prom-prometheus-server 9090:80 -n dapr-monitoring
打开浏览器并访问 http://localhost:9090。导航到 Status > Service Discovery 以验证 Dapr 目标是否被正确发现。
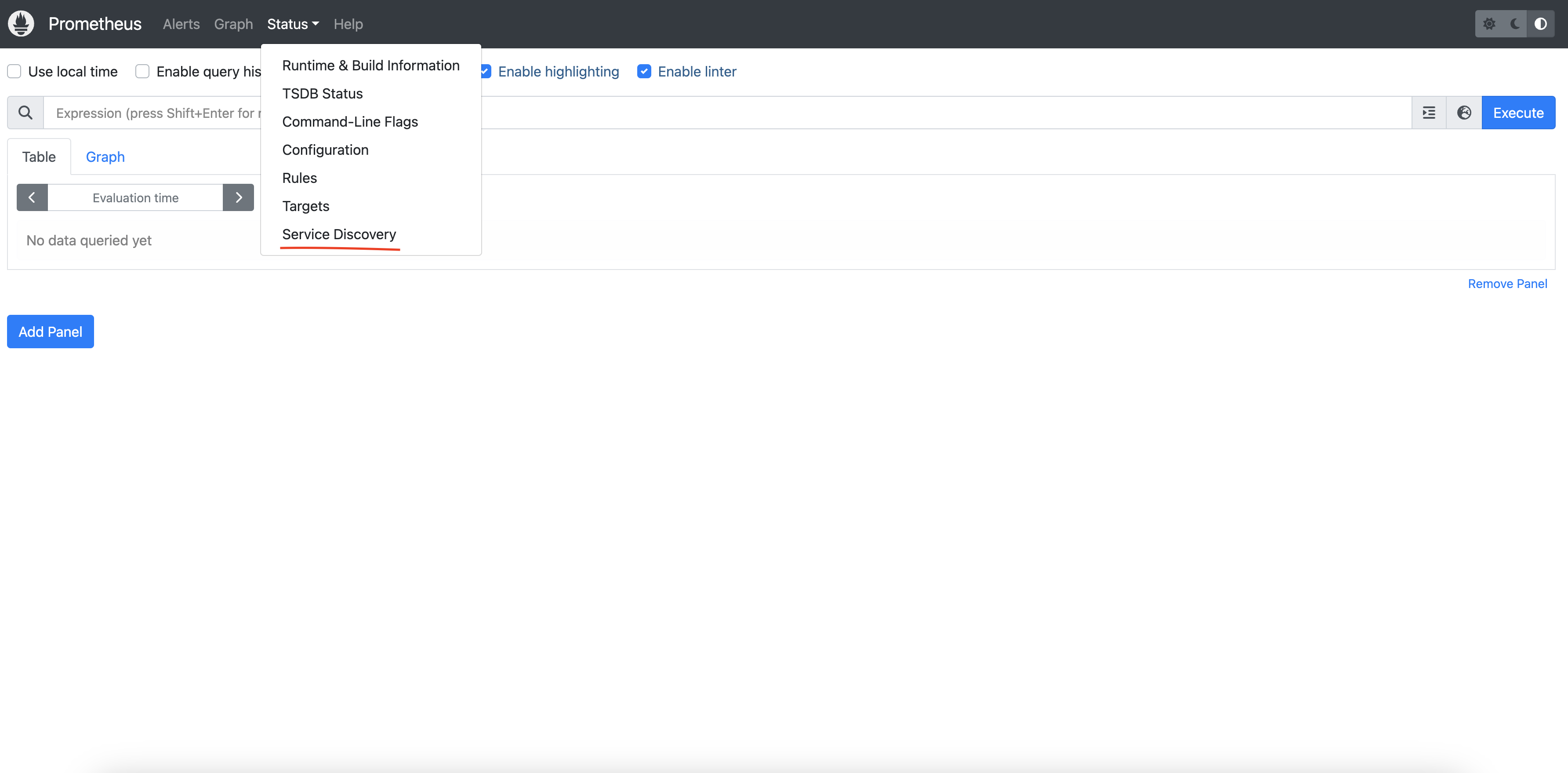
您可以看到 job_name 及其发现的目标。
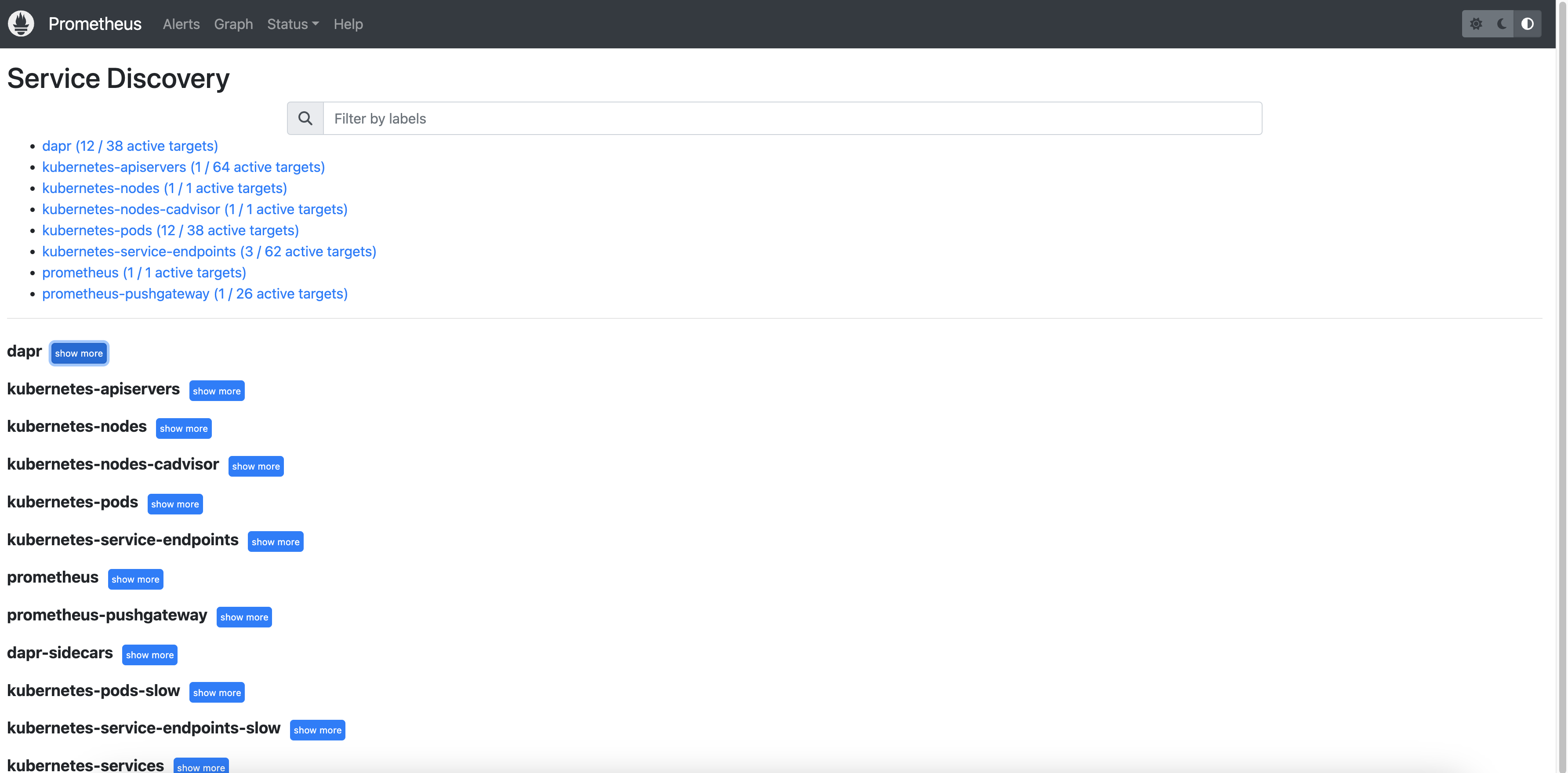
示例
参考资料
2.2 - 配置指标
启用或禁用Dapr指标
默认情况下,每个Dapr系统进程都会发出Go运行时和进程指标,并拥有自己的Dapr指标。
Prometheus端点
Dapr sidecar提供了一个与Prometheus兼容的指标端点,您可以通过抓取该端点来更好地了解Dapr的运行状况。
使用CLI配置指标
指标应用程序端点默认是启用的。您可以通过传递命令行参数--enable-metrics=false来禁用它。
默认的指标端口是9090。您可以通过传递命令行参数--metrics-port给daprd来更改此设置。
在Kubernetes中配置指标
您还可以通过在应用程序部署上设置dapr.io/enable-metrics: "false"注解来启用或禁用特定应用程序的指标。禁用指标导出器后,daprd不会打开指标监听端口。
以下Kubernetes部署示例显示了如何显式启用指标,并将端口指定为"9090"。
apiVersion: apps/v1
kind: Deployment
metadata:
name: nodeapp
labels:
app: node
spec:
replicas: 1
selector:
matchLabels:
app: node
template:
metadata:
labels:
app: node
annotations:
dapr.io/enabled: "true"
dapr.io/app-id: "nodeapp"
dapr.io/app-port: "3000"
dapr.io/enable-metrics: "true"
dapr.io/metrics-port: "9090"
spec:
containers:
- name: node
image: dapriosamples/hello-k8s-node:latest
ports:
- containerPort: 3000
imagePullPolicy: Always
使用应用程序配置启用指标
您还可以通过应用程序配置启用指标。要默认禁用Dapr sidecar中的指标收集,请将spec.metrics.enabled设置为false。
apiVersion: dapr.io/v1alpha1
kind: Configuration
metadata:
name: tracing
namespace: default
spec:
metrics:
enabled: false
为错误代码配置指标
您可以通过设置spec.metrics.recordErrorCodes为true来为Dapr API错误代码启用额外的指标。Dapr API可能会返回标准化的错误代码。一个名为error_code_total的新指标被记录,它允许监控由应用程序、代码和类别触发的错误代码。有关特定代码和类别,请参见errorcodes包。
示例配置:
apiVersion: dapr.io/v1alpha1
kind: Configuration
metadata:
name: tracing
namespace: default
spec:
metrics:
enabled: true
recordErrorCodes: true
示例指标:
{
"app_id": "publisher-app",
"category": "state",
"dapr_io_enabled": "true",
"error_code": "ERR_STATE_STORE_NOT_CONFIGURED",
"instance": "10.244.1.64:9090",
"job": "kubernetes-service-endpoints",
"namespace": "my-app",
"node": "my-node",
"service": "publisher-app-dapr"
}
使用路径匹配优化HTTP指标报告
在使用HTTP调用Dapr时,默认情况下会为每个请求的方法创建指标。这可能导致大量指标,称为高基数,这可能会影响内存使用和CPU。
路径匹配允许您管理和控制Dapr中HTTP指标的基数。通过聚合指标,您可以减少指标事件的数量并报告一个总体数量。了解更多关于如何在配置中设置基数。
此配置是选择加入的,并通过Dapr配置spec.metrics.http.pathMatching启用。当定义时,它启用路径匹配,这将标准化指定路径的两个指标路径。这减少了唯一指标路径的数量,使指标更易于管理,并以受控方式减少资源消耗。
当spec.metrics.http.pathMatching与increasedCardinality标志设置为false结合使用时,未匹配的路径会被转换为一个通用桶,以控制和限制基数,防止路径无限增长。相反,当increasedCardinality为true(默认值)时,未匹配的路径会像通常一样传递,允许潜在的更高基数,但保留原始路径数据。
HTTP指标中的路径匹配示例
以下示例演示了如何在Dapr中使用路径匹配API来管理HTTP指标。在每个示例中,指标是从5个HTTP请求到/orders端点收集的,具有不同的订单ID。通过调整基数和利用路径匹配,您可以微调指标粒度以平衡细节和资源效率。
这些示例说明了指标的基数,强调高基数配置会导致许多条目,这对应于处理指标的更高内存使用。为简单起见,以下示例专注于单个指标:dapr_http_server_request_count。
低基数与路径匹配(推荐)
配置:
http:
increasedCardinality: false
pathMatching:
- /orders/{orderID}
生成的指标:
# 匹配的路径
dapr_http_server_request_count{app_id="order-service",method="GET",path="/orders/{orderID}",status="200"} 5
# 未匹配的路径
dapr_http_server_request_count{app_id="order-service",method="GET",path="",status="200"} 1
通过配置低基数和路径匹配,您可以在不影响基数的情况下对重要端点的指标进行分组。这种方法有助于避免高内存使用和潜在的安全问题。
无路径匹配的低基数
配置:
http:
increasedCardinality: false
生成的指标:
dapr_http_server_request_count{app_id="order-service",method="GET", path="",status="200"} 5
在低基数模式下,路径是无限基数的主要来源,被丢弃。这导致的指标主要指示给定HTTP方法的服务请求数量,但没有关于调用路径的信息。
高基数与路径匹配
配置:
http:
increasedCardinality: true
pathMatching:
- /orders/{orderID}
生成的指标:
dapr_http_server_request_count{app_id="order-service",method="GET",path="/orders/{orderID}",status="200"} 5
此示例来自与上例相同的HTTP请求,但为路径/orders/{orderID}配置了路径匹配。通过使用路径匹配,您可以通过基于匹配路径分组指标来实现减少基数。
无路径匹配的高基数
配置:
http:
increasedCardinality: true
生成的指标:
dapr_http_server_request_count{app_id="order-service",method="GET",path="/orders/1",status="200"} 1
dapr_http_server_request_count{app_id="order-service",method="GET",path="/orders/2",status="200"} 1
dapr_http_server_request_count{app_id="order-service",method="GET",path="/orders/3",status="200"} 1
dapr_http_server_request_count{app_id="order-service",method="GET",path="/orders/4",status="200"} 1
dapr_http_server_request_count{app_id="order-service",method="GET",path="/orders/5",status="200"} 1
对于每个请求,都会创建一个带有请求路径的新指标。此过程会继续为每个新订单ID的请求创建新指标,导致基数无限增长,因为ID是不断增长的。
HTTP指标排除动词
excludeVerbs选项允许您从指标中排除特定的HTTP动词。这在内存节省至关重要的高性能应用程序中非常有用。
在指标中排除HTTP动词的示例
以下示例演示了如何在Dapr中排除HTTP动词以管理HTTP指标。
默认 - 包含HTTP动词
配置:
http:
excludeVerbs: false
生成的指标:
dapr_http_server_request_count{app_id="order-service",method="GET",path="/orders",status="200"} 1
dapr_http_server_request_count{app_id="order-service",method="POST",path="/orders",status="200"} 1
在此示例中,HTTP方法包含在指标中,导致每个请求到/orders端点的单独指标。
排除HTTP动词
配置:
http:
excludeVerbs: true
生成的指标:
dapr_http_server_request_count{app_id="order-service",method="",path="/orders",status="200"} 2
在此示例中,HTTP方法从指标中排除,导致所有请求到/orders端点的单个指标。
配置自定义延迟直方图桶
Dapr使用累积直方图指标将延迟值分组到桶中,其中每个桶包含:
- 具有该延迟的请求数量
- 所有具有较低延迟的请求
使用默认延迟桶配置
默认情况下,Dapr将请求延迟指标分组到以下桶中:
1, 2, 3, 4, 5, 6, 8, 10, 13, 16, 20, 25, 30, 40, 50, 65, 80, 100, 130, 160, 200, 250, 300, 400, 500, 650, 800, 1000, 2000, 5000, 10000, 20000, 50000, 100000
以累积方式分组延迟值允许根据需要使用或丢弃桶以增加或减少数据的粒度。 例如,如果一个请求需要3ms,它会被计入3ms桶、4ms桶、5ms桶,依此类推。 同样,如果一个请求需要10ms,它会被计入10ms桶、13ms桶、16ms桶,依此类推。 在这两个请求完成后,3ms桶的计数为1,而10ms桶的计数为2,因为这两个请求都包含在这里。
这显示如下:
| 1 | 2 | 3 | 4 | 5 | 6 | 8 | 10 | 13 | 16 | 20 | 25 | 30 | 40 | 50 | 65 | 80 | 100 | 130 | 160 | ….. | 100000 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 1 | 1 | 1 | 1 | 1 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | ….. | 2 |
默认的桶数量适用于大多数用例,但可以根据需要进行调整。每个请求创建34个不同的指标,这个值可能会随着大量应用程序而显著增长。 通过增加桶的数量可以获得更准确的延迟百分位数。然而,更多的桶会增加存储指标所需的内存量,可能会对您的监控系统产生负面影响。
建议将延迟桶的数量设置为默认值,除非您在监控系统中看到不必要的内存压力。配置桶的数量允许您选择应用程序:
- 您希望通过更多的桶看到更多细节
- 通过减少桶来获得更广泛的值
在配置桶的数量之前,请注意您的应用程序产生的默认延迟值。
根据您的场景自定义延迟桶
通过修改应用程序的Dapr配置规范中的spec.metrics.latencyDistributionBuckets字段,定制延迟桶以满足您的需求。
例如,如果您对极低的延迟值(1-10ms)不感兴趣,可以将它们分组到一个10ms桶中。同样,您可以将高值分组到一个桶中(1000-5000ms),同时在您最感兴趣的中间范围内保持更多细节。
以下配置规范示例用11个桶替换了默认的34个桶,在中间范围内提供了更高的粒度:
apiVersion: dapr.io/v1alpha1
kind: Configuration
metadata:
name: custom-metrics
spec:
metrics:
enabled: true
latencyDistributionBuckets: [10, 25, 40, 50, 70, 100, 150, 200, 500, 1000, 5000]
使用正则表达式转换指标
您可以为Dapr sidecar公开的每个指标设置正则表达式以“转换”其值。查看所有Dapr指标的列表。
规则的名称必须与被转换的指标名称匹配。以下示例显示了如何为指标dapr_runtime_service_invocation_req_sent_total中的标签method应用正则表达式:
apiVersion: dapr.io/v1alpha1
kind: Configuration
metadata:
name: daprConfig
spec:
metrics:
enabled: true
http:
increasedCardinality: true
rules:
- name: dapr_runtime_service_invocation_req_sent_total
labels:
- name: method
regex:
"orders/": "orders/.+"
应用此配置后,记录的带有method标签的指标orders/a746dhsk293972nz将被替换为orders/。
使用正则表达式减少指标基数被认为是遗留的。我们鼓励所有用户将spec.metrics.http.increasedCardinality设置为false,这更易于配置并提供更好的性能。
参考
2.3 - 如何使用Grafana监控指标
在Grafana仪表板中查看Dapr指标的方法。
可用的仪表板
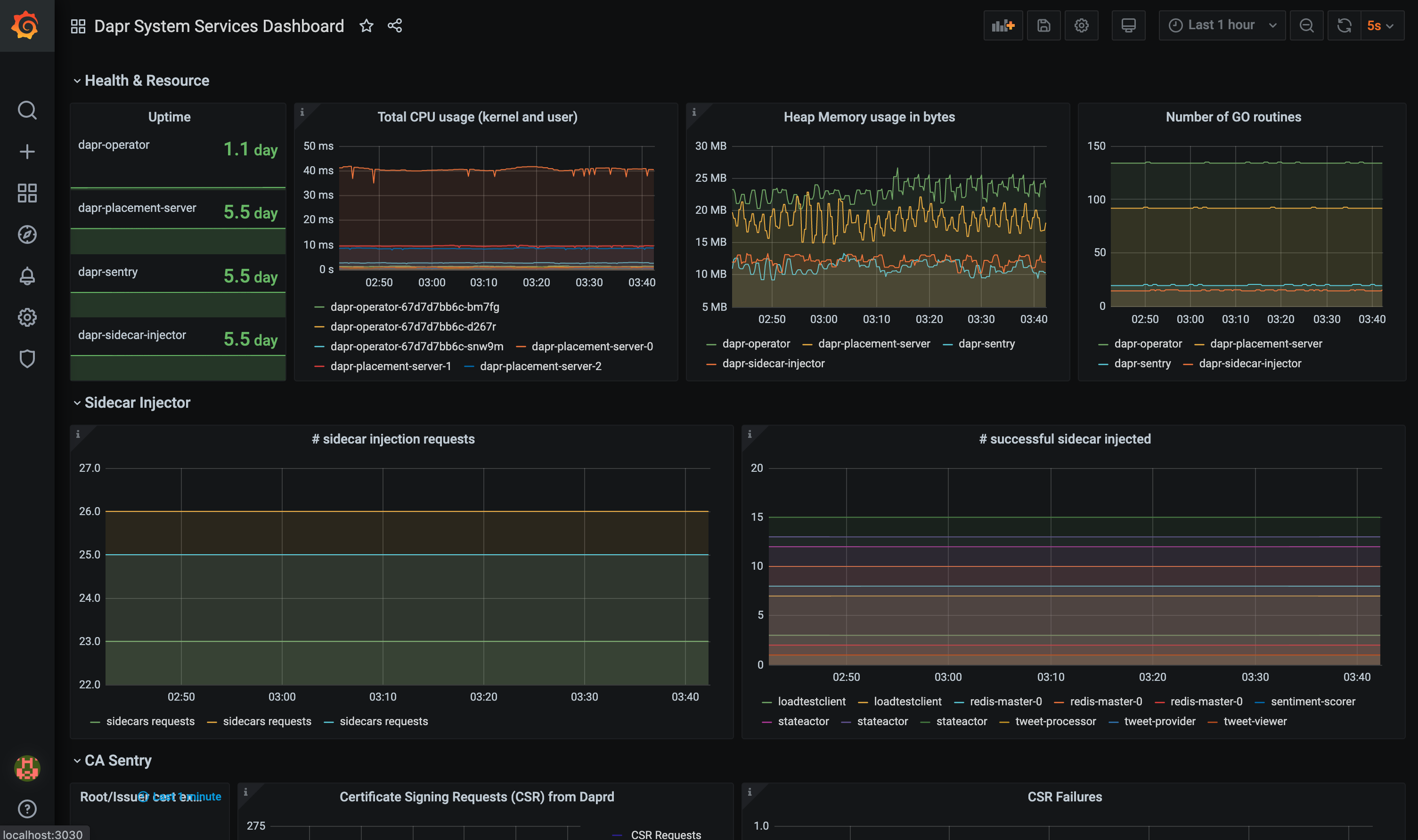
grafana-system-services-dashboard.json模板展示了Dapr系统组件的状态,包括dapr-operator、dapr-sidecar-injector、dapr-sentry和dapr-placement:
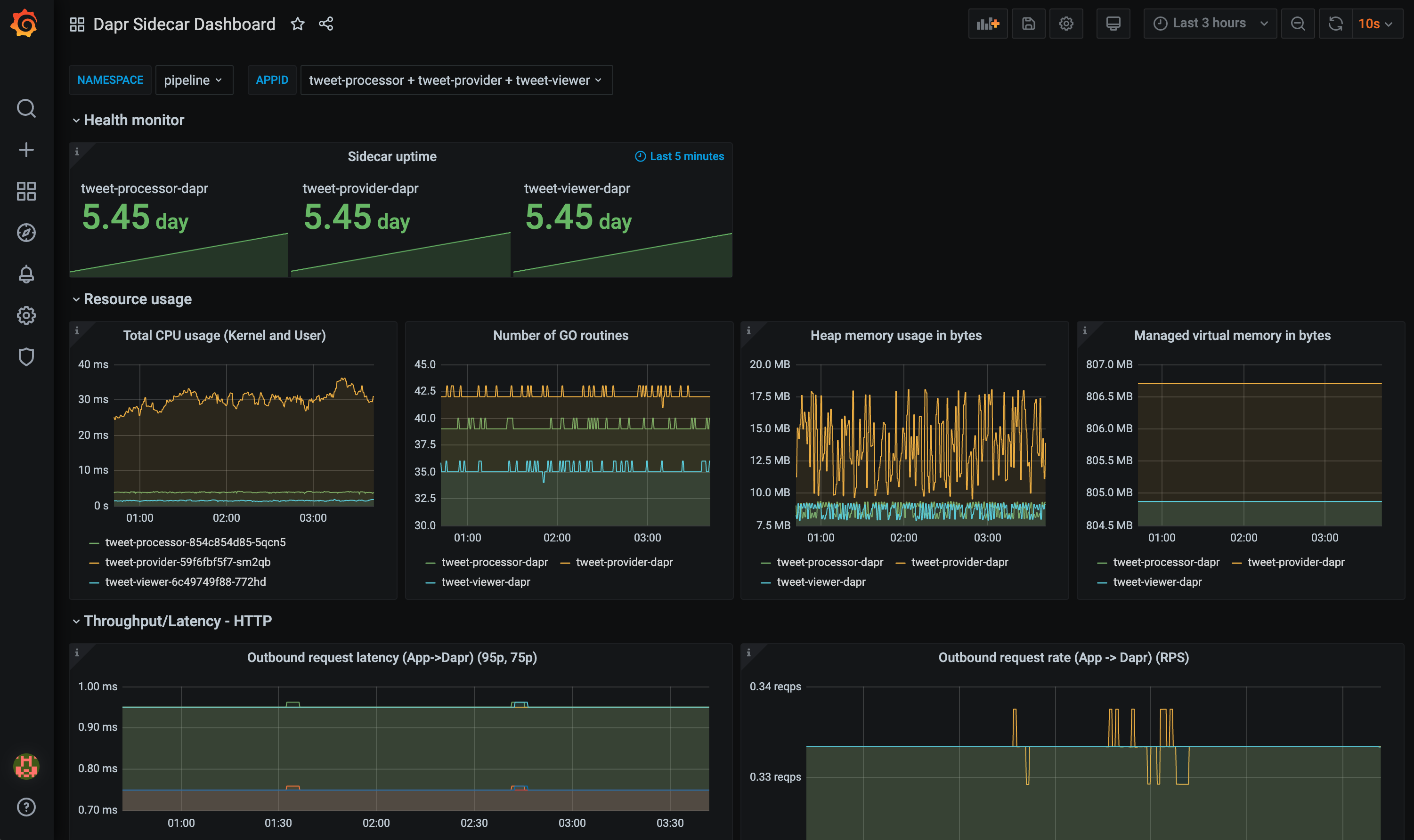
grafana-sidecar-dashboard.json模板展示了Dapr sidecar 的状态,包括sidecar 的健康状况/资源使用情况、HTTP和gRPC的吞吐量/延迟、actor、mTLS等:
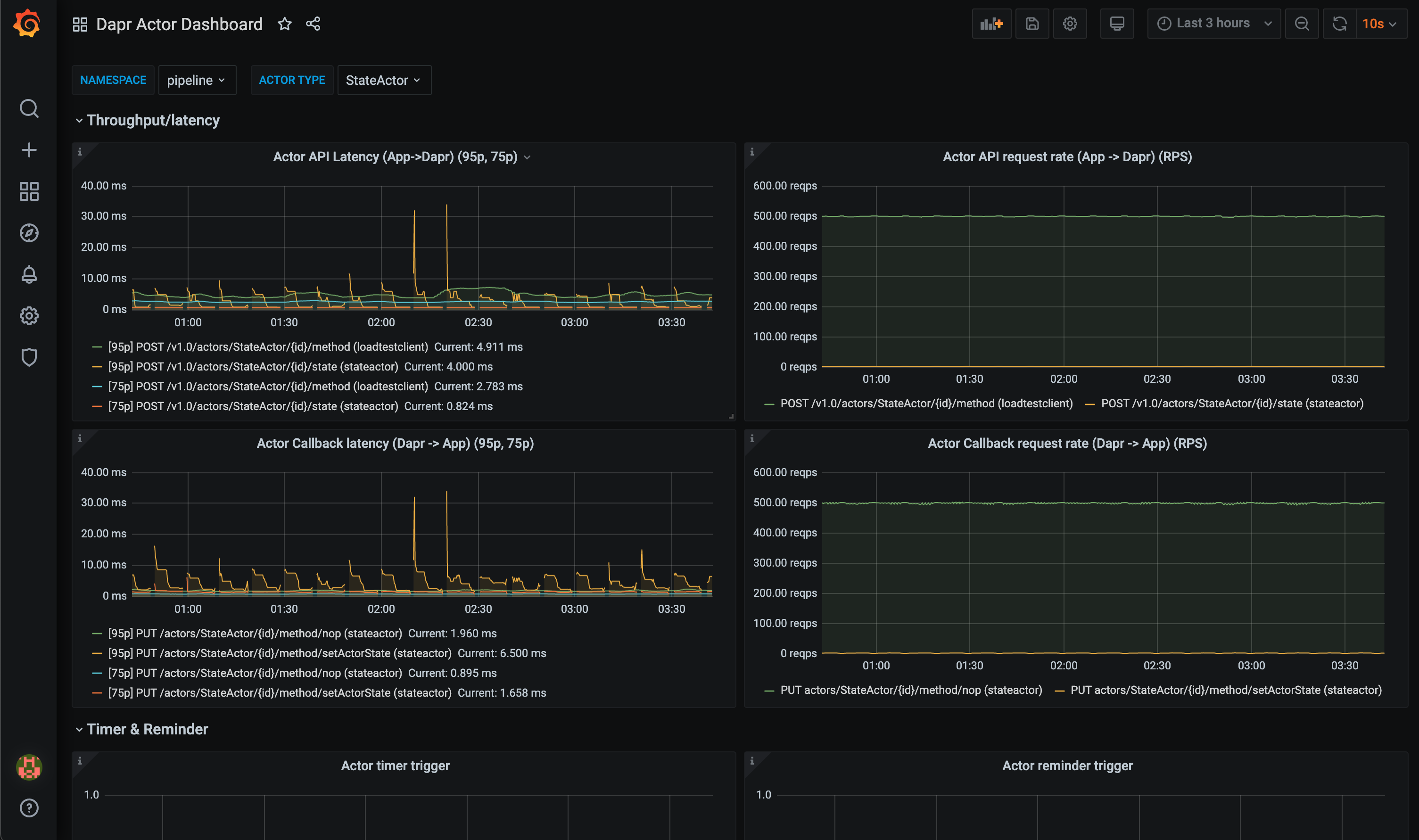
grafana-actor-dashboard.json模板展示了Dapr sidecar 的状态、actor 调用的吞吐量/延迟、timer/reminder触发器和基于回合的并发性:
前提条件
在Kubernetes上设置
安装Grafana
添加Grafana Helm仓库:
helm repo add grafana https://grafana.github.io/helm-charts helm repo update安装图表:
helm install grafana grafana/grafana -n dapr-monitoring注意
如果您使用Minikube或希望在开发中禁用持久卷,可以使用以下命令禁用:
helm install grafana grafana/grafana -n dapr-monitoring --set persistence.enabled=false获取Grafana登录的管理员密码:
kubectl get secret --namespace dapr-monitoring grafana -o jsonpath="{.data.admin-password}" | base64 --decode ; echo您将看到一个类似于
cj3m0OfBNx8SLzUlTx91dEECgzRlYJb60D2evof1%的密码。请去掉密码中的%字符,得到cj3m0OfBNx8SLzUlTx91dEECgzRlYJb60D2evof1作为管理员密码。检查Grafana是否在您的集群中运行:
kubectl get pods -n dapr-monitoring NAME READY STATUS RESTARTS AGE dapr-prom-kube-state-metrics-9849d6cc6-t94p8 1/1 Running 0 4m58s dapr-prom-prometheus-alertmanager-749cc46f6-9b5t8 2/2 Running 0 4m58s dapr-prom-prometheus-node-exporter-5jh8p 1/1 Running 0 4m58s dapr-prom-prometheus-node-exporter-88gbg 1/1 Running 0 4m58s dapr-prom-prometheus-node-exporter-bjp9f 1/1 Running 0 4m58s dapr-prom-prometheus-pushgateway-688665d597-h4xx2 1/1 Running 0 4m58s dapr-prom-prometheus-server-694fd8d7c-q5d59 2/2 Running 0 4m58s grafana-c49889cff-x56vj 1/1 Running 0 5m10s
配置Prometheus作为数据源
首先,您需要将Prometheus连接为Grafana的数据源。
端口转发到svc/grafana:
kubectl port-forward svc/grafana 8080:80 -n dapr-monitoring Forwarding from 127.0.0.1:8080 -> 3000 Forwarding from [::1]:8080 -> 3000 Handling connection for 8080 Handling connection for 8080打开浏览器访问
http://localhost:8080登录Grafana
- 用户名 =
admin - 密码 = 上述密码
- 用户名 =
选择
Configuration和Data Sources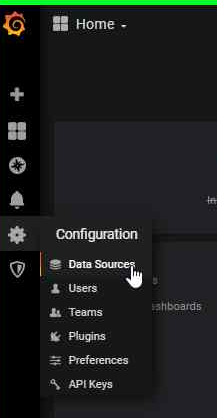
添加Prometheus作为数据源。
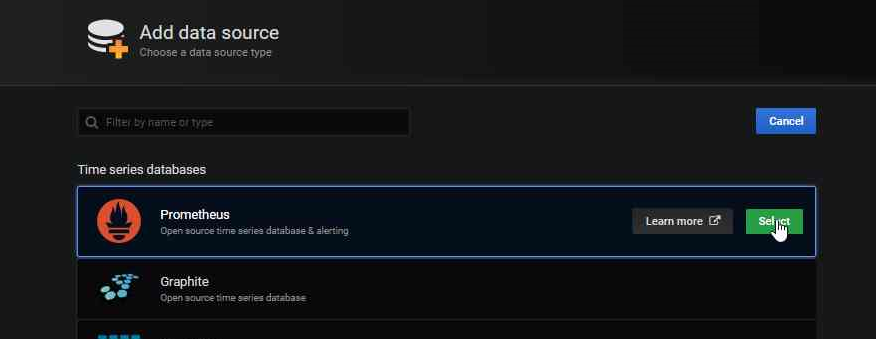
获取您的Prometheus HTTP URL
Prometheus HTTP URL的格式为
http://<prometheus服务端点>.<命名空间>首先通过运行以下命令获取Prometheus服务器端点:
kubectl get svc -n dapr-monitoring NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE dapr-prom-kube-state-metrics ClusterIP 10.0.174.177 <none> 8080/TCP 7d9h dapr-prom-prometheus-alertmanager ClusterIP 10.0.255.199 <none> 80/TCP 7d9h dapr-prom-prometheus-node-exporter ClusterIP None <none> 9100/TCP 7d9h dapr-prom-prometheus-pushgateway ClusterIP 10.0.190.59 <none> 9091/TCP 7d9h dapr-prom-prometheus-server ClusterIP 10.0.172.191 <none> 80/TCP 7d9h elasticsearch-master ClusterIP 10.0.36.146 <none> 9200/TCP,9300/TCP 7d10h elasticsearch-master-headless ClusterIP None <none> 9200/TCP,9300/TCP 7d10h grafana ClusterIP 10.0.15.229 <none> 80/TCP 5d5h kibana-kibana ClusterIP 10.0.188.224 <none> 5601/TCP 7d10h在本指南中,服务器名称为
dapr-prom-prometheus-server,命名空间为dapr-monitoring,因此HTTP URL将是http://dapr-prom-prometheus-server.dapr-monitoring。填写以下设置:
- 名称:
Dapr - HTTP URL:
http://dapr-prom-prometheus-server.dapr-monitoring - 默认:开启
- 跳过TLS验证:开启
- 这是保存和测试配置所必需的
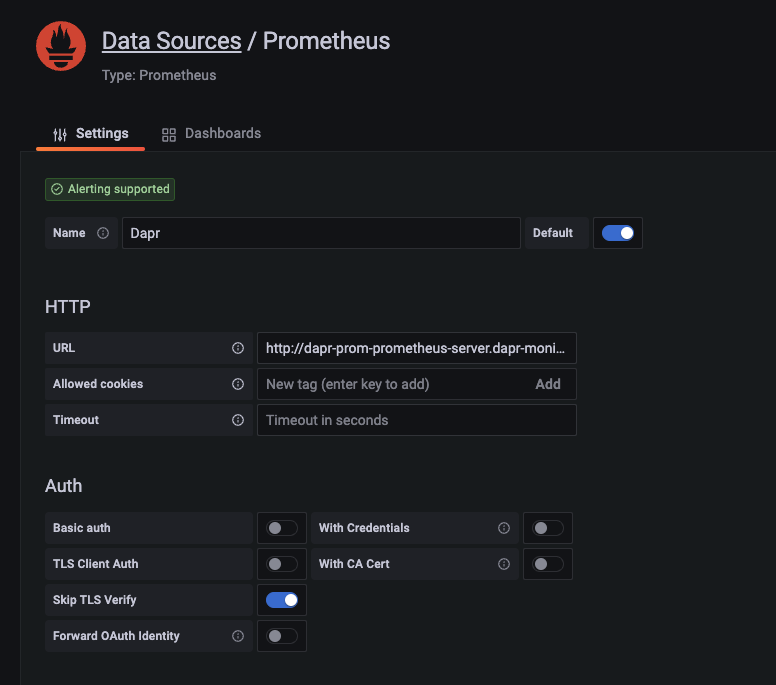
- 名称:
点击
Save & Test按钮以验证连接是否成功。
在Grafana中导入仪表板
在Grafana主屏幕的左上角,点击“+”选项,然后选择“Import”。
现在,您可以从发布资产中为您的Dapr版本导入Grafana仪表板模板:
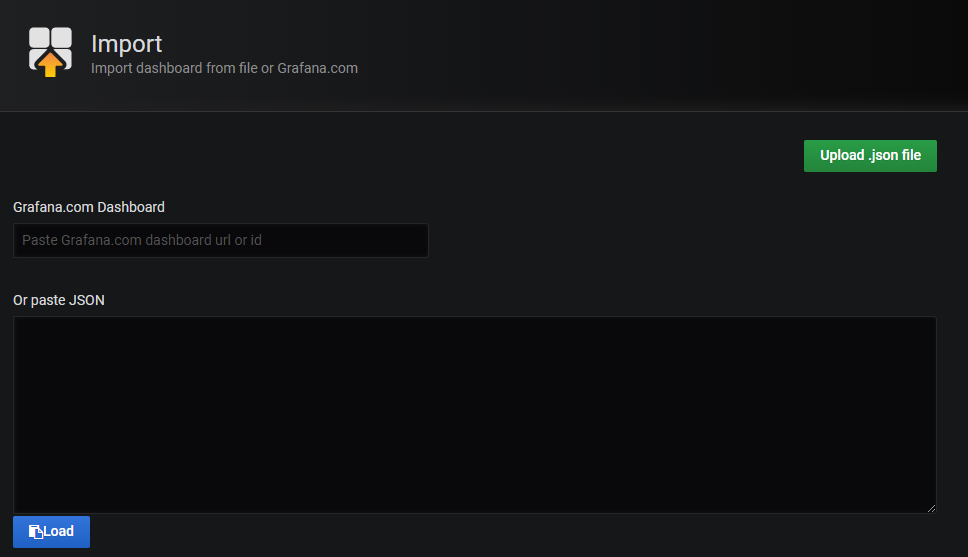
找到您导入的仪表板并享受
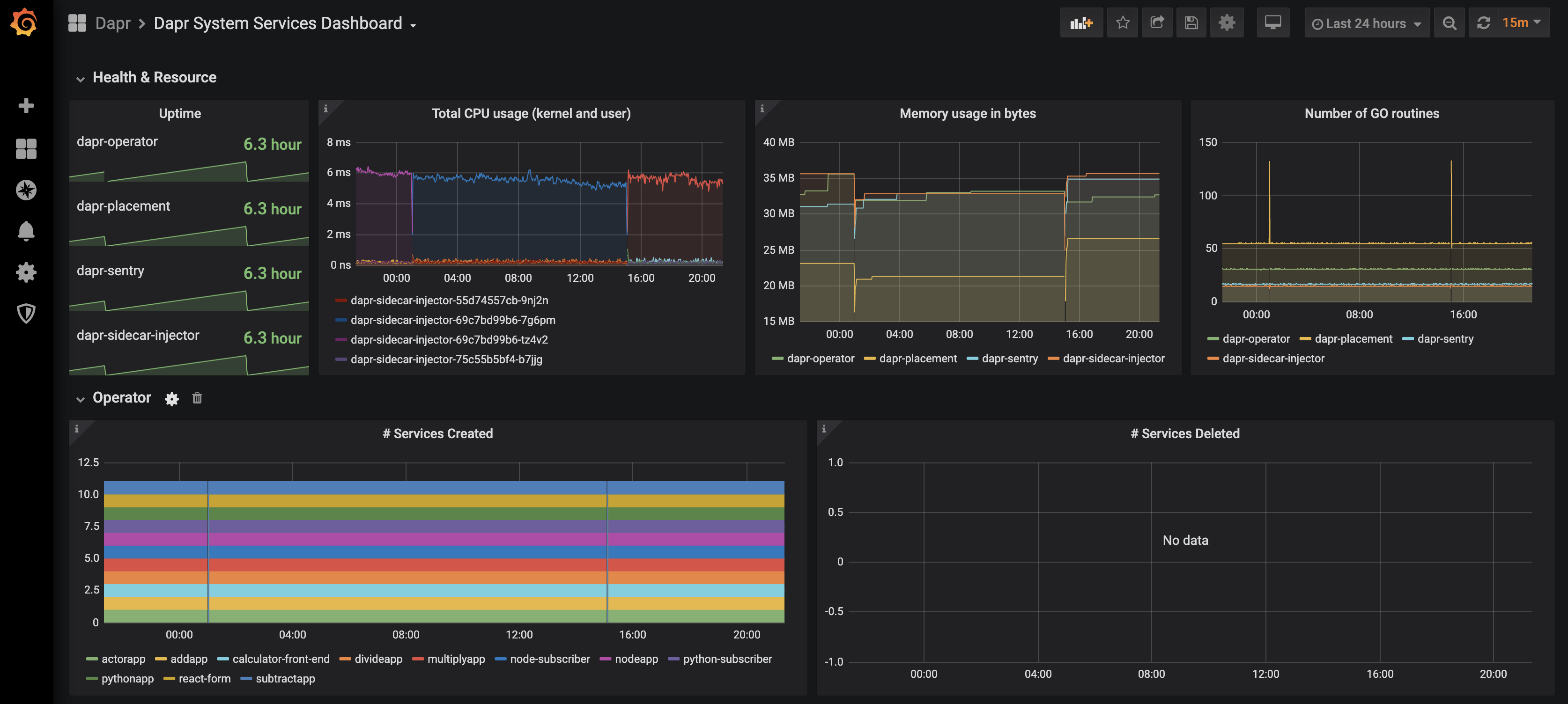
提示
将鼠标悬停在每个图表描述角落的
i上: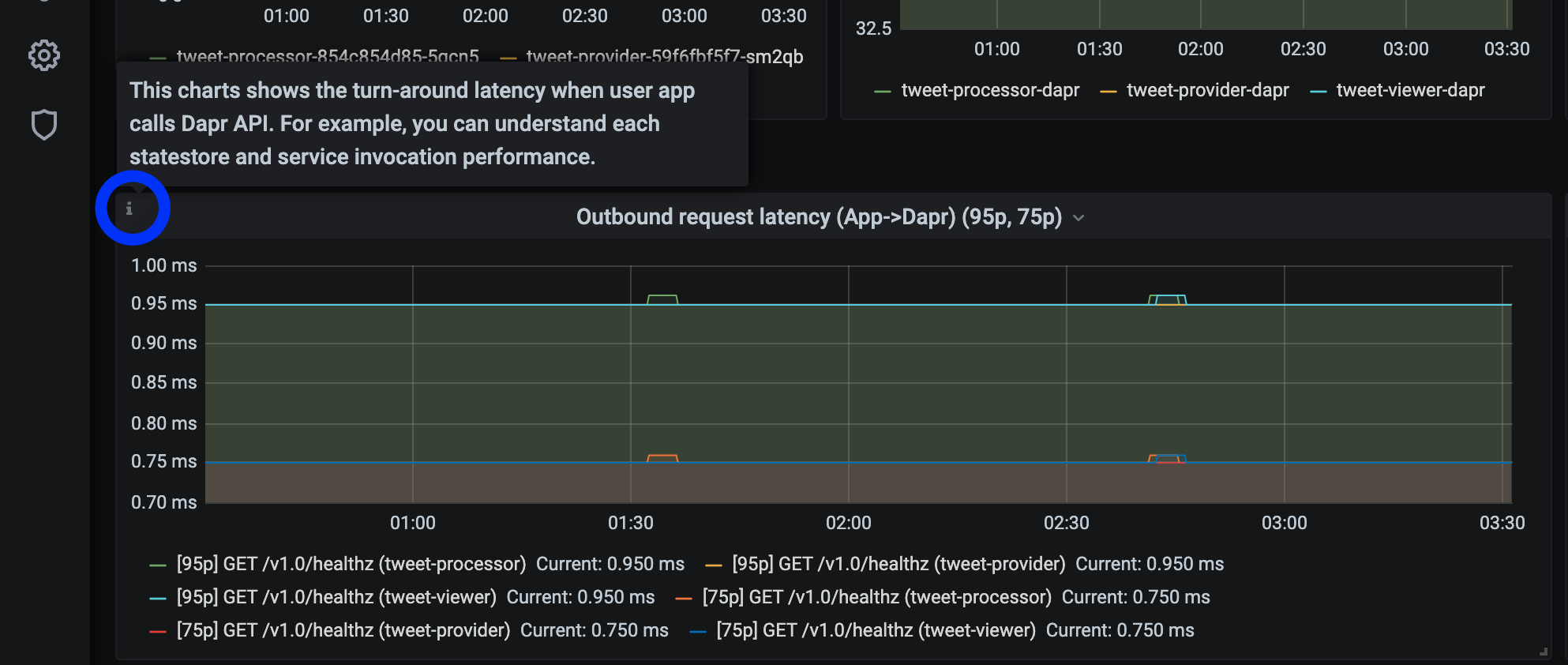
参考资料
示例
2.4 - 操作指南:配置 New Relic 以收集和分析指标
为 Dapr 指标配置 New Relic
前提条件
- New Relic 账户,永久免费,每月提供 100 GB 的免费数据摄取,1 个免费完全访问用户,无限制的免费基本用户
背景信息
New Relic 支持 Prometheus 的 OpenMetrics 集成。
本文档将介绍如何在集群中安装该集成,建议使用 Helm chart 进行安装。
安装步骤
根据官方说明安装 Helm。
按照这些说明添加 New Relic 官方 Helm chart 仓库。
运行以下命令通过 Helm 安装 New Relic Logging Kubernetes 插件,并将 YOUR_LICENSE_KEY 替换为您的 New Relic 许可证密钥:
helm install nri-prometheus newrelic/nri-prometheus --set licenseKey=YOUR_LICENSE_KEY
查看指标
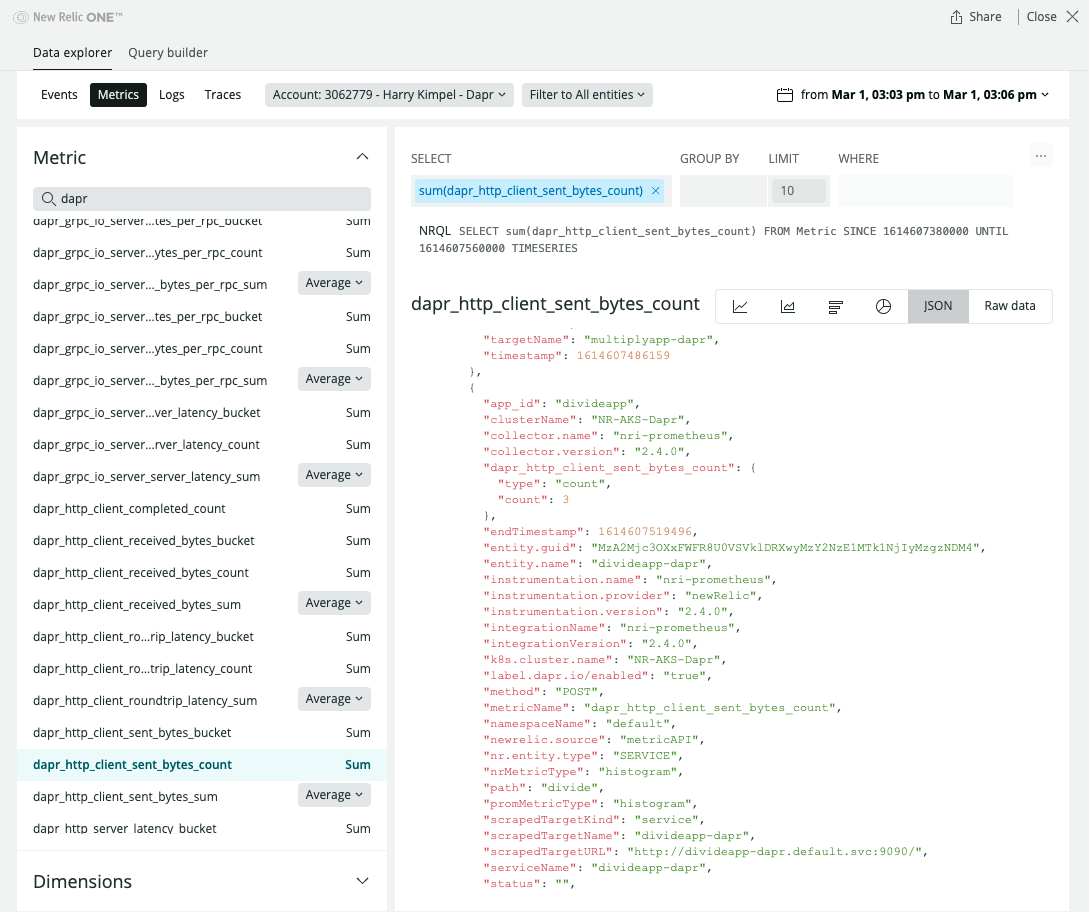
相关链接/参考
2.5 - 操作指南:配置 Azure Monitor 以搜索日志和收集指标
为 Azure Kubernetes Service (AKS) 启用 Dapr 指标和日志的 Azure Monitor
前提条件
使用配置映射启用 Prometheus 指标抓取
确认 Azure Monitor Agents (AMA) 正在运行。
$ kubectl get pods -n kube-system NAME READY STATUS RESTARTS AGE ... ama-logs-48kpv 2/2 Running 0 2d13h ama-logs-mx24c 2/2 Running 0 2d13h ama-logs-rs-f9bbb9898-vbt6k 1/1 Running 0 30h ama-logs-sm2mz 2/2 Running 0 2d13h ama-logs-z7p4c 2/2 Running 0 2d13h ...使用配置映射启用 Prometheus 指标端点抓取。
可以使用 azm-config-map.yaml 来启用 Prometheus 指标端点抓取。
如果 Dapr 安装在不同的命名空间,需要修改
monitor_kubernetes_pod_namespaces数组的值。例如:... prometheus-data-collection-settings: |- [prometheus_data_collection_settings.cluster] interval = "1m" monitor_kubernetes_pods = true monitor_kubernetes_pods_namespaces = ["dapr-system", "default"] [prometheus_data_collection_settings.node] interval = "1m" ...应用配置映射:
kubectl apply -f ./azm-config.map.yaml
安装带有 JSON 格式日志的 Dapr
安装 Dapr 并启用 JSON 格式日志。
helm install dapr dapr/dapr --namespace dapr-system --set global.logAsJson=true在 Dapr sidecar 中启用 JSON 格式日志并添加 Prometheus 注解。
注意:只有设置了 Prometheus 注解,Azure Monitor Agents (AMA) 才会发送指标。
在部署的 YAML 文件中添加
dapr.io/log-as-json: "true"注解。示例:
apiVersion: apps/v1 kind: Deployment metadata: name: pythonapp namespace: default labels: app: python spec: replicas: 1 selector: matchLabels: app: python template: metadata: labels: app: python annotations: dapr.io/enabled: "true" dapr.io/app-id: "pythonapp" dapr.io/log-as-json: "true" prometheus.io/scrape: "true" prometheus.io/port: "9090" prometheus.io/path: "/" ...
使用 Azure Monitor 搜索指标和日志
在 Azure 门户中进入 Azure Monitor。
搜索 Dapr 日志。
下面是一个示例查询,用于解析 JSON 格式日志并查询来自 Dapr 系统进程的日志。
ContainerLog | extend parsed=parse_json(LogEntry) | project Time=todatetime(parsed['time']), app_id=parsed['app_id'], scope=parsed['scope'],level=parsed['level'], msg=parsed['msg'], type=parsed['type'], ver=parsed['ver'], instance=parsed['instance'] | where level != "" | sort by Time搜索 指标。
这个查询,查询
process_resident_memory_bytesPrometheus 指标用于 Dapr 系统进程并渲染时间图表。InsightsMetrics | where Namespace == "prometheus" and Name == "process_resident_memory_bytes" | extend tags=parse_json(Tags) | project TimeGenerated, Name, Val, app=tostring(tags['app']) | summarize memInBytes=percentile(Val, 99) by bin(TimeGenerated, 1m), app | where app startswith "dapr-" | render timechart
参考资料
3 - 日志记录
如何为 Dapr sidecar 和您的应用程序设置日志记录
在 Dapr 中,日志记录是一个关键功能,帮助开发者监控和调试应用程序。Dapr 提供了多种日志记录选项,您可以根据需求进行灵活配置。
配置 Dapr sidecar 日志
您可以通过设置环境变量来配置 Dapr sidecar 的日志记录。可以调整日志级别、输出格式等,以适应不同的需求。常见的日志级别包括 Debug、Info、Warning 和 Error。
应用程序日志记录
除了 Dapr sidecar,您还可以为您的应用程序设置日志记录。通过使用 Dapr 的日志记录功能,您可以更有效地监控应用程序的行为和性能。
日志输出
Dapr 支持将日志输出到多种目标,包括控制台、文件和远程日志服务。您可以根据应用程序的部署环境选择最合适的日志输出方式。
通过合理配置日志记录,您可以更好地了解应用程序的运行状况,快速发现和解决问题。
3.1 - 日志
了解 Dapr 日志
Dapr 生成的结构化日志会输出到 stdout,可以选择纯文本或 JSON 格式。默认情况下,所有 Dapr 进程(包括运行时或 sidecar,以及所有控制平面服务)都会以纯文本形式将日志写入控制台(stdout)。若要启用 JSON 格式的日志记录,您需要在运行 Dapr 进程时添加 --log-as-json 命令标志。
注意
如果您希望使用 Elastic Search 或 Azure Monitor 等搜索引擎来搜索日志,强烈建议使用 JSON 格式的日志,因为日志收集器和搜索引擎可以利用内置的 JSON 解析器更好地解析这些日志。日志模式
Dapr 生成的日志遵循以下模式:
| 字段 | 描述 | 示例 |
|---|---|---|
| time | ISO8601 时间戳 | 2011-10-05T14:48:00.000Z |
| level | 日志级别 (info/warn/debug/error) | info |
| type | 日志类型 | log |
| msg | 日志消息 | hello dapr! |
| scope | 日志范围 | dapr.runtime |
| instance | 容器名称 | dapr-pod-xxxxx |
| app_id | Dapr 应用 ID | dapr-app |
| ver | Dapr 运行时版本 | 1.9.0 |
API 日志可能会添加其他结构化字段,具体请参阅 API 日志记录文档。
纯文本和 JSON 格式的日志
- 纯文本日志示例
time="2022-11-01T17:08:48.303776-07:00" level=info msg="starting Dapr Runtime -- version 1.9.0 -- commit v1.9.0-g5dfcf2e" instance=dapr-pod-xxxx scope=dapr.runtime type=log ver=1.9.0
time="2022-11-01T17:08:48.303913-07:00" level=info msg="log level set to: info" instance=dapr-pod-xxxx scope=dapr.runtime type=log ver=1.9.0
- JSON 格式日志示例
{"instance":"dapr-pod-xxxx","level":"info","msg":"starting Dapr Runtime -- version 1.9.0 -- commit v1.9.0-g5dfcf2e","scope":"dapr.runtime","time":"2022-11-01T17:09:45.788005Z","type":"log","ver":"1.9.0"}
{"instance":"dapr-pod-xxxx","level":"info","msg":"log level set to: info","scope":"dapr.runtime","time":"2022-11-01T17:09:45.788075Z","type":"log","ver":"1.9.0"}
日志格式
Dapr 支持输出纯文本(默认)或 JSON 格式的日志。
若要使用 JSON 格式的日志,您需要在安装 Dapr 和部署应用时添加额外的配置选项。建议使用 JSON 格式的日志,因为大多数日志收集器和搜索引擎可以更容易地解析 JSON。
使用 Dapr CLI 启用 JSON 日志
使用 Dapr CLI 运行应用程序时,传递 --log-as-json 选项以启用 JSON 格式的日志,例如:
dapr run \
--app-id orderprocessing \
--resources-path ./components/ \
--log-as-json \
-- python3 OrderProcessingService.py
在 Kubernetes 中启用 JSON 日志
以下步骤描述了如何为 Kubernetes 配置 JSON 格式的日志
Dapr 控制平面
Dapr 控制平面中的所有服务(如 operator、sentry 等)支持 --log-as-json 选项以启用 JSON 格式的日志记录。
如果您使用 Helm chart 将 Dapr 部署到 Kubernetes,可以通过传递 --set global.logAsJson=true 选项为 Dapr 系统服务启用 JSON 格式的日志;例如:
helm upgrade --install dapr \
dapr/dapr \
--namespace dapr-system \
--set global.logAsJson=true
为 Dapr sidecar 启用 JSON 格式日志
您可以通过在部署中添加 dapr.io/log-as-json: "true" 注释来为 Dapr sidecar 启用 JSON 格式的日志,例如:
apiVersion: apps/v1
kind: Deployment
metadata:
name: pythonapp
labels:
app: python
spec:
selector:
matchLabels:
app: python
template:
metadata:
labels:
app: python
annotations:
dapr.io/enabled: "true"
dapr.io/app-id: "pythonapp"
# 启用 JSON 格式的日志
dapr.io/log-as-json: "true"
...
API 日志
API 日志使您能够查看应用程序对 Dapr sidecar 的 API 调用,以调试问题或监控应用程序的行为。您可以将 Dapr API 日志与 Dapr 日志事件结合使用。
有关更多信息,请参阅 配置和查看 Dapr 日志 和 配置和查看 Dapr API 日志。
日志收集器
如果您在 Kubernetes 集群中运行 Dapr,Fluentd 是一个流行的容器日志收集器。您可以使用带有 JSON 解析器插件 的 Fluentd 来解析 Dapr JSON 格式的日志。这个 操作指南 显示了如何在集群中配置 Fluentd。
如果您使用 Azure Kubernetes Service,您可以使用内置代理通过 Azure Monitor 收集日志,而无需安装 Fluentd。
搜索引擎
如果您使用 Fluentd,我们建议使用 Elastic Search 和 Kibana。这个 操作指南 显示了如何在 Kubernetes 集群中设置 Elastic Search 和 Kibana。
如果您使用 Azure Kubernetes Service,您可以使用 Azure Monitor for containers 而无需安装任何额外的监控工具。另请阅读 如何启用 Azure Monitor for containers
参考资料
3.2 - 操作指南:在 Kubernetes 中设置 Fluentd、Elastic search 和 Kibana
如何在 Kubernetes 中安装 Fluentd、Elastic Search 和 Kibana 以搜索日志
前提条件
安装 Elastic search 和 Kibana
创建一个用于监控工具的 Kubernetes 命名空间
kubectl create namespace dapr-monitoring添加 Elastic Search 的 Helm 仓库
helm repo add elastic https://helm.elastic.co helm repo update使用 Helm 安装 Elastic Search
默认情况下,chart 会创建 3 个副本,要求它们位于不同的节点上。如果您的集群少于 3 个节点,请指定较少的副本数。例如,将副本数设置为 1:
helm install elasticsearch elastic/elasticsearch --version 7.17.3 -n dapr-monitoring --set replicas=1否则:
helm install elasticsearch elastic/elasticsearch --version 7.17.3 -n dapr-monitoring如果您使用 minikube 或仅在开发过程中想禁用持久卷,可以使用以下命令:
helm install elasticsearch elastic/elasticsearch --version 7.17.3 -n dapr-monitoring --set persistence.enabled=false,replicas=1安装 Kibana
helm install kibana elastic/kibana --version 7.17.3 -n dapr-monitoring确保 Elastic Search 和 Kibana 在您的 Kubernetes 集群中正常运行
$ kubectl get pods -n dapr-monitoring NAME READY STATUS RESTARTS AGE elasticsearch-master-0 1/1 Running 0 6m58s kibana-kibana-95bc54b89-zqdrk 1/1 Running 0 4m21s
安装 Fluentd
作为 daemonset 安装配置映射和 Fluentd
下载这些配置文件:
注意:如果您的集群中已经运行了 Fluentd,请启用嵌套的 JSON 解析器,以便它可以解析来自 Dapr 的 JSON 格式日志。
将配置应用到您的集群:
kubectl apply -f ./fluentd-config-map.yaml kubectl apply -f ./fluentd-dapr-with-rbac.yaml确保 Fluentd 作为 daemonset 运行。FluentD 实例的数量应与集群节点的数量相同。以下示例中,集群中只有一个节点:
$ kubectl get pods -n kube-system -w NAME READY STATUS RESTARTS AGE coredns-6955765f44-cxjxk 1/1 Running 0 4m41s coredns-6955765f44-jlskv 1/1 Running 0 4m41s etcd-m01 1/1 Running 0 4m48s fluentd-sdrld 1/1 Running 0 14s
安装 Dapr 并启用 JSON 格式日志
安装 Dapr 并启用 JSON 格式日志
helm repo add dapr https://dapr.github.io/helm-charts/ helm repo update helm install dapr dapr/dapr --namespace dapr-system --set global.logAsJson=true在 Dapr sidecar 中启用 JSON 格式日志
在您的部署 yaml 中添加
dapr.io/log-as-json: "true"注解。例如:apiVersion: apps/v1 kind: Deployment metadata: name: pythonapp namespace: default labels: app: python spec: replicas: 1 selector: matchLabels: app: python template: metadata: labels: app: python annotations: dapr.io/enabled: "true" dapr.io/app-id: "pythonapp" dapr.io/log-as-json: "true" ...
搜索日志
注意:Elastic Search 需要一些时间来索引 Fluentd 发送的日志。
从本地主机端口转发到
svc/kibana-kibana$ kubectl port-forward svc/kibana-kibana 5601 -n dapr-monitoring Forwarding from 127.0.0.1:5601 -> 5601 Forwarding from [::1]:5601 -> 5601 Handling connection for 5601 Handling connection for 5601浏览到
http://localhost:5601展开下拉菜单并点击 Management → Stack Management
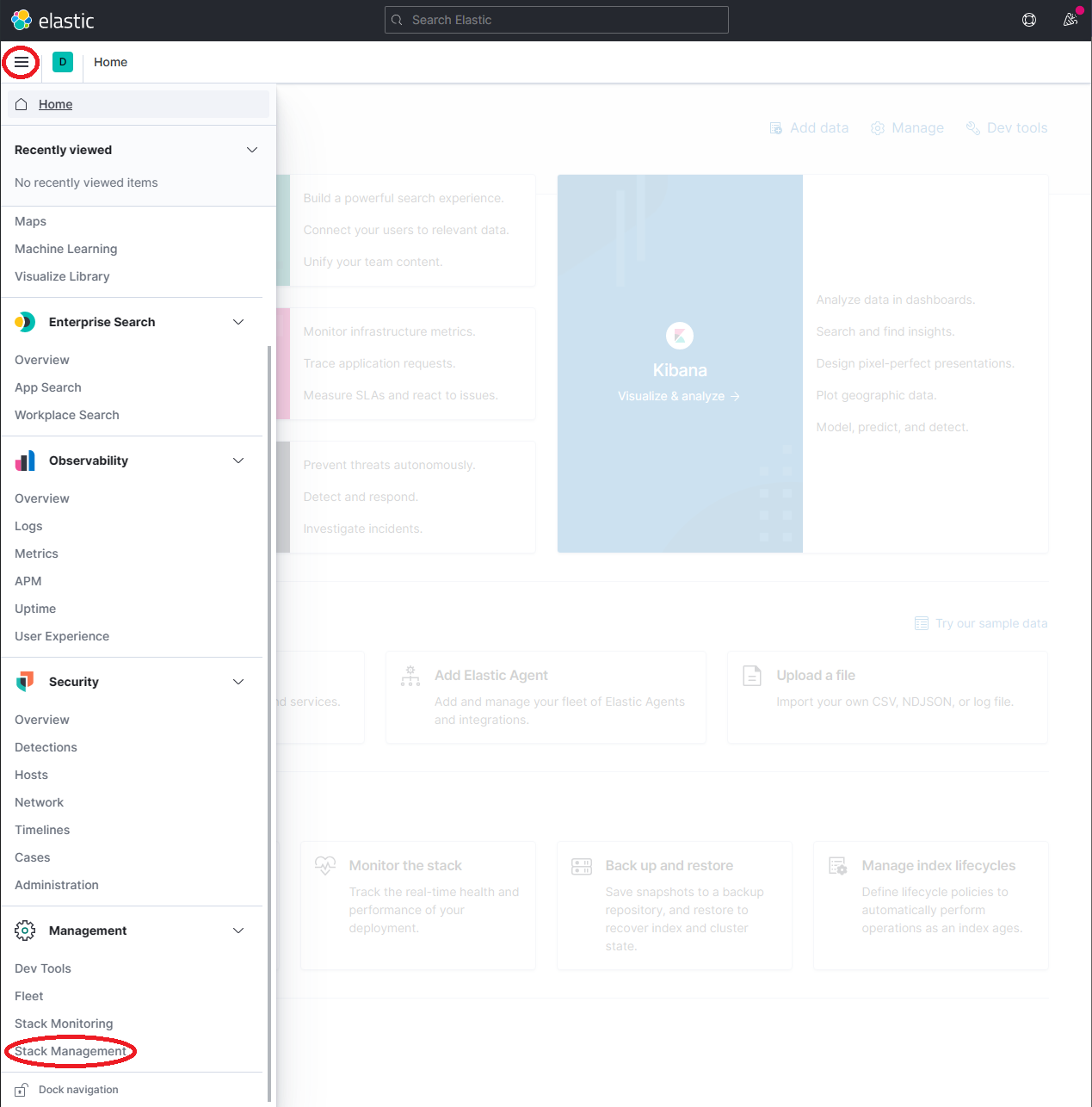
在 Stack Management 页面上,选择 Data → Index Management 并等待
dapr-*被索引。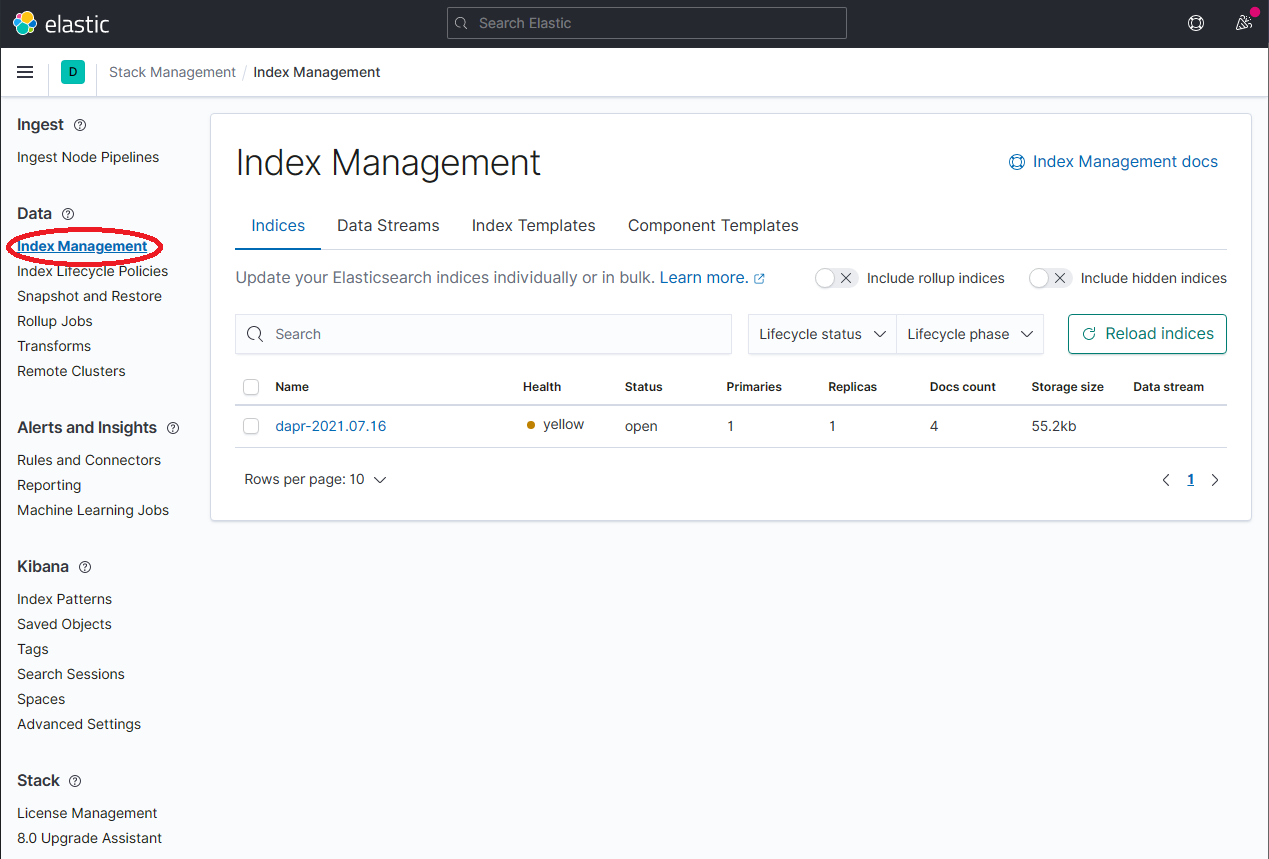
一旦
dapr-*被索引,点击 Kibana → Index Patterns 然后点击 Create index pattern 按钮。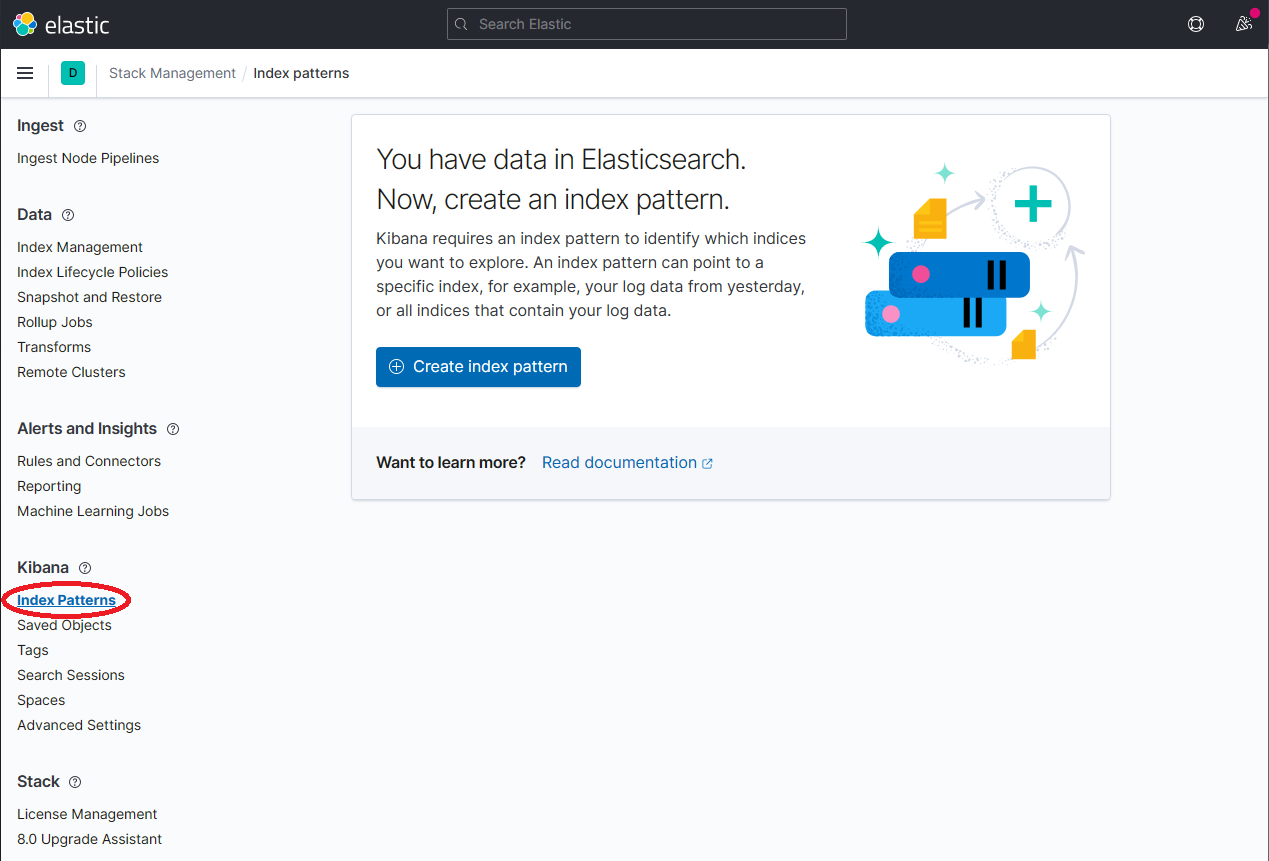
通过在 Index Pattern name 字段中输入
dapr*来定义一个新的索引模式,然后点击 Next step 按钮继续。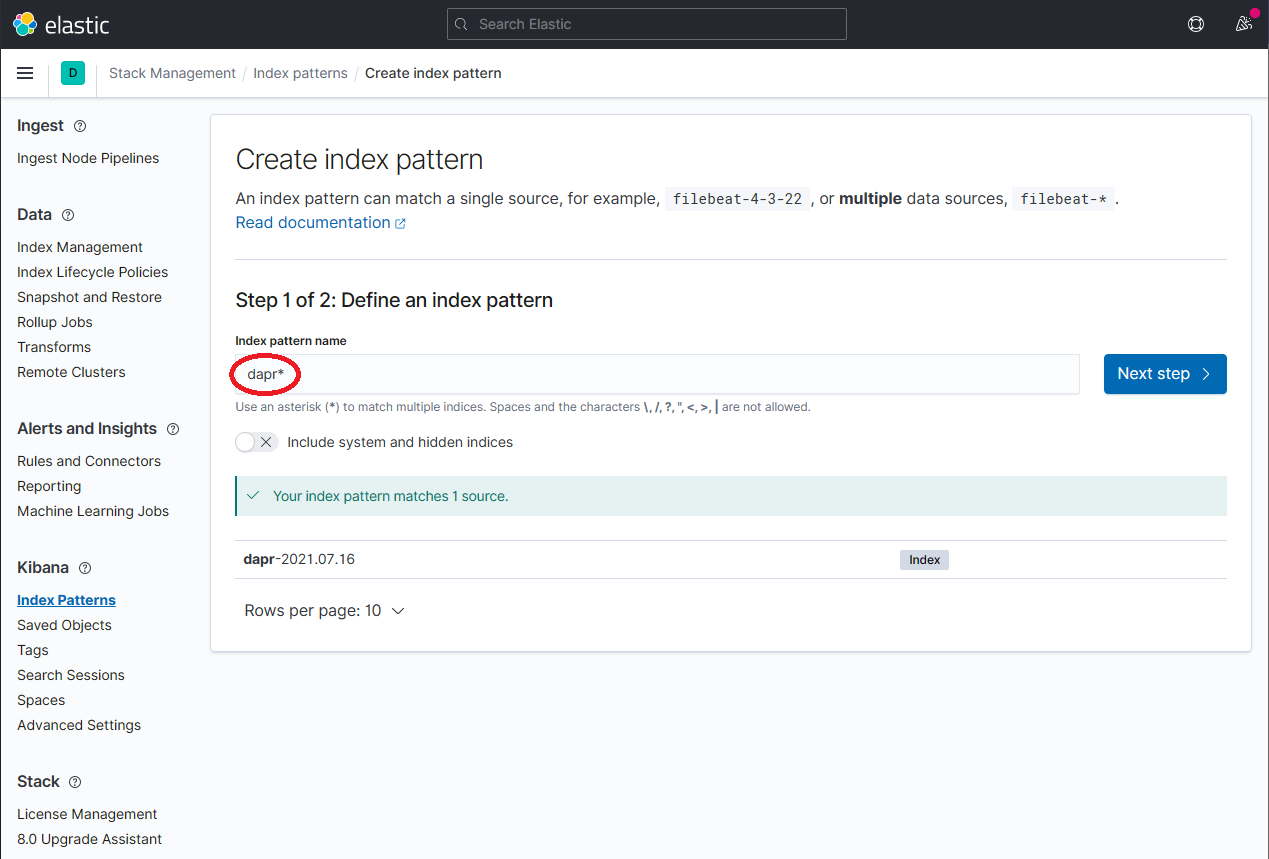
通过从 Time field 下拉菜单中选择
@timestamp选项来配置新索引模式的主要时间字段。点击 Create index pattern 按钮完成索引模式的创建。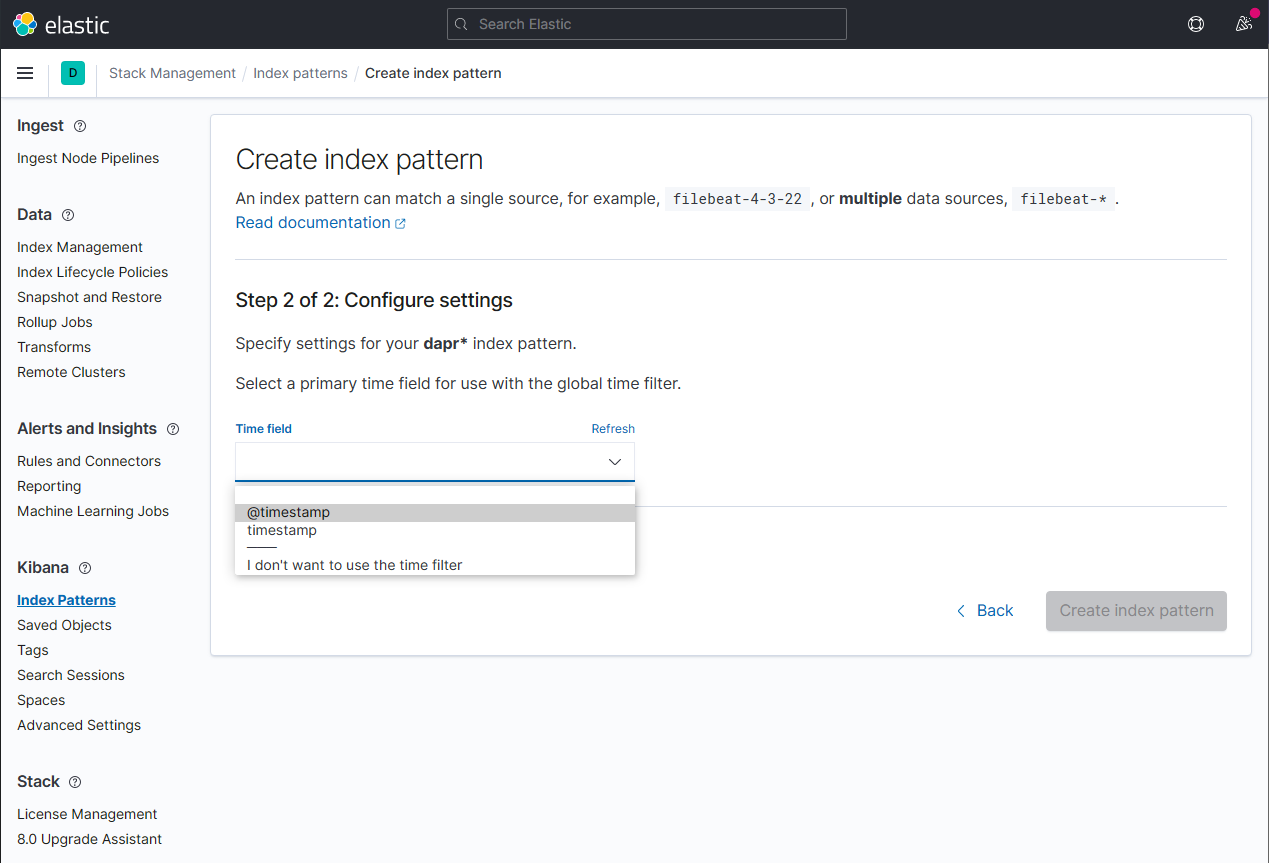
应显示新创建的索引模式。通过在 Fields 标签中的搜索框中使用搜索,确认感兴趣的字段如
scope、type、app_id、level等是否被索引。注意:如果找不到索引字段,请稍等。搜索所有索引字段所需的时间取决于数据量和 Elastic Search 运行的资源大小。
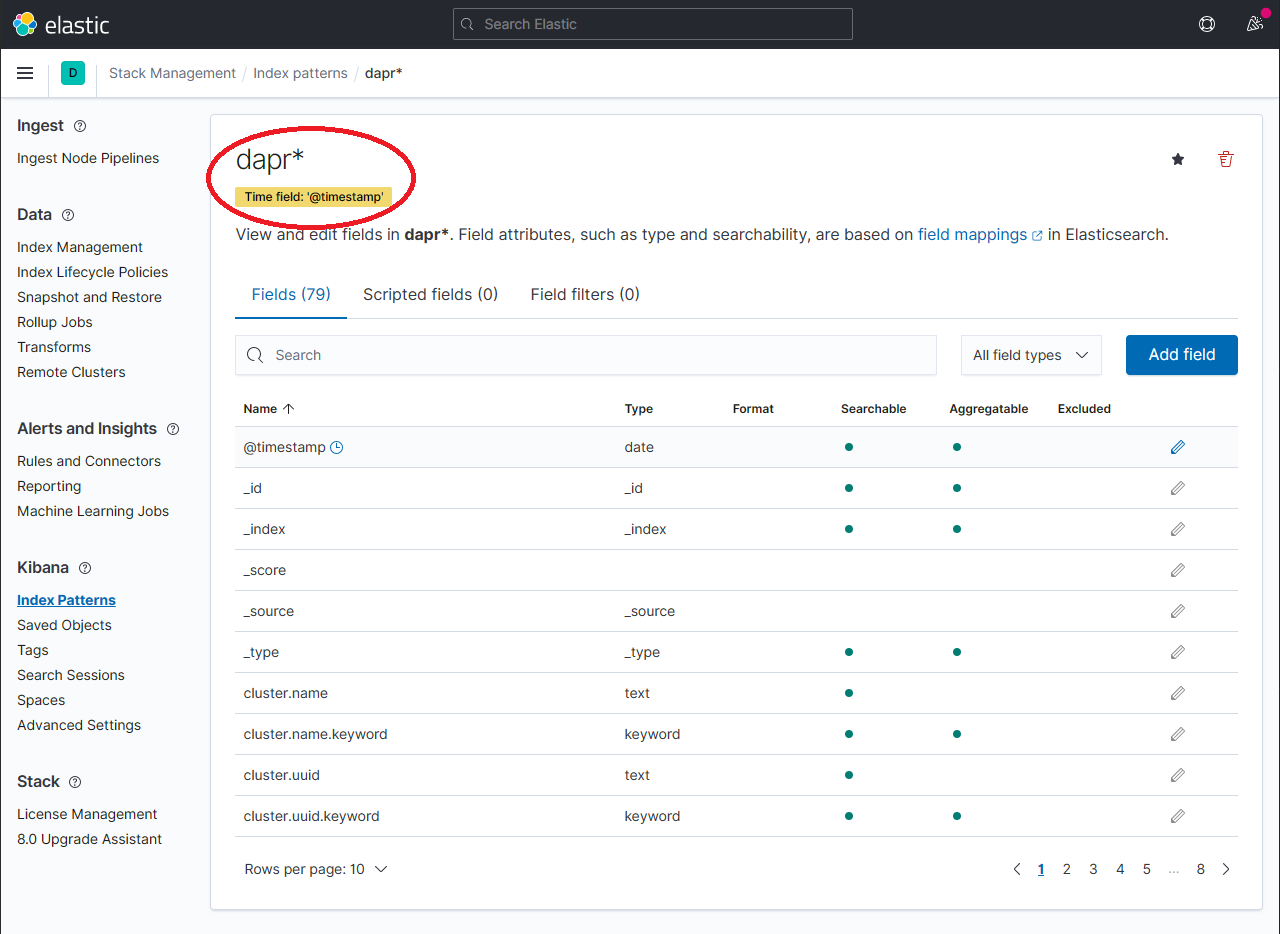
要探索索引的数据,展开下拉菜单并点击 Analytics → Discover。
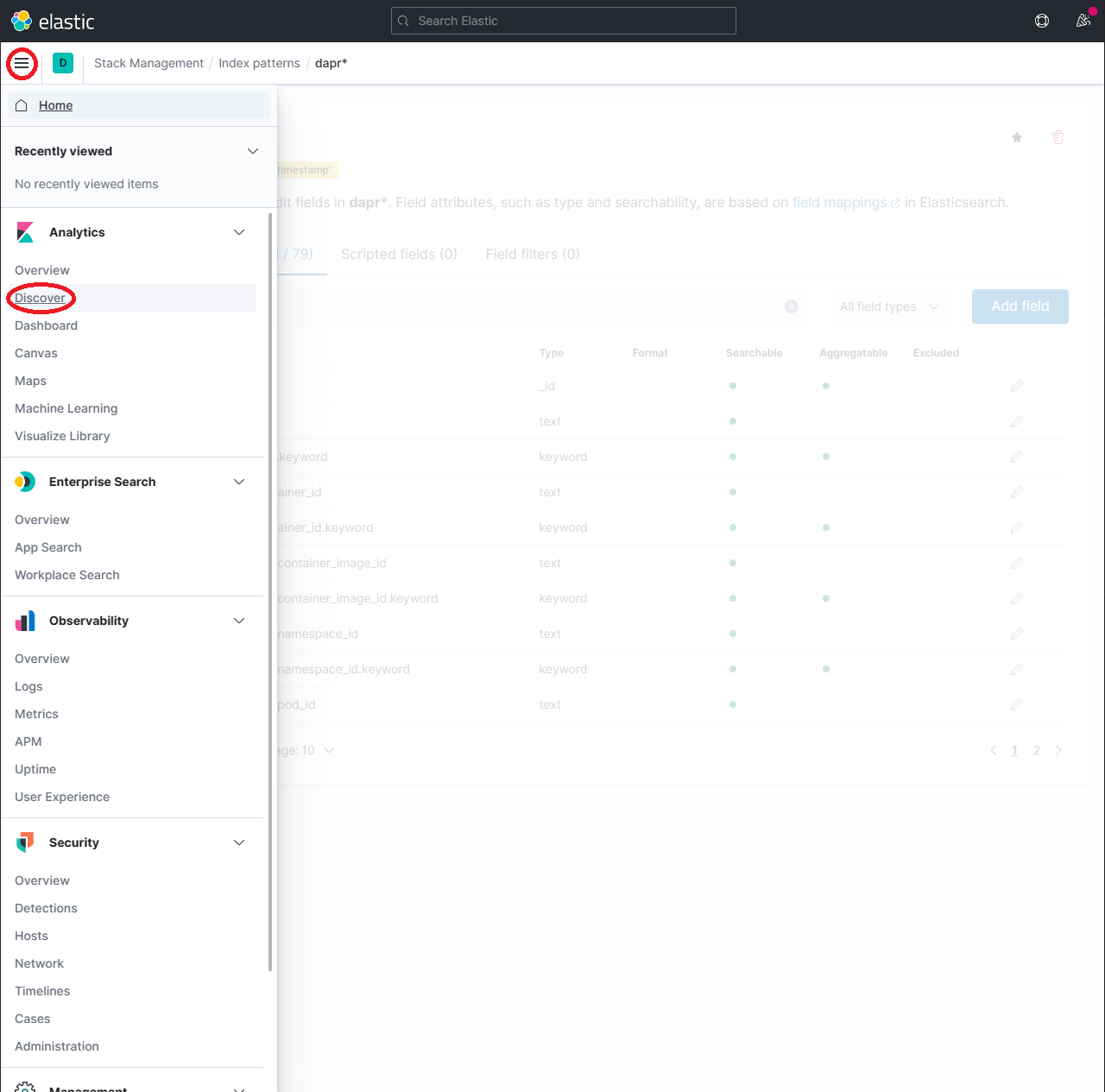
在搜索框中输入查询字符串如
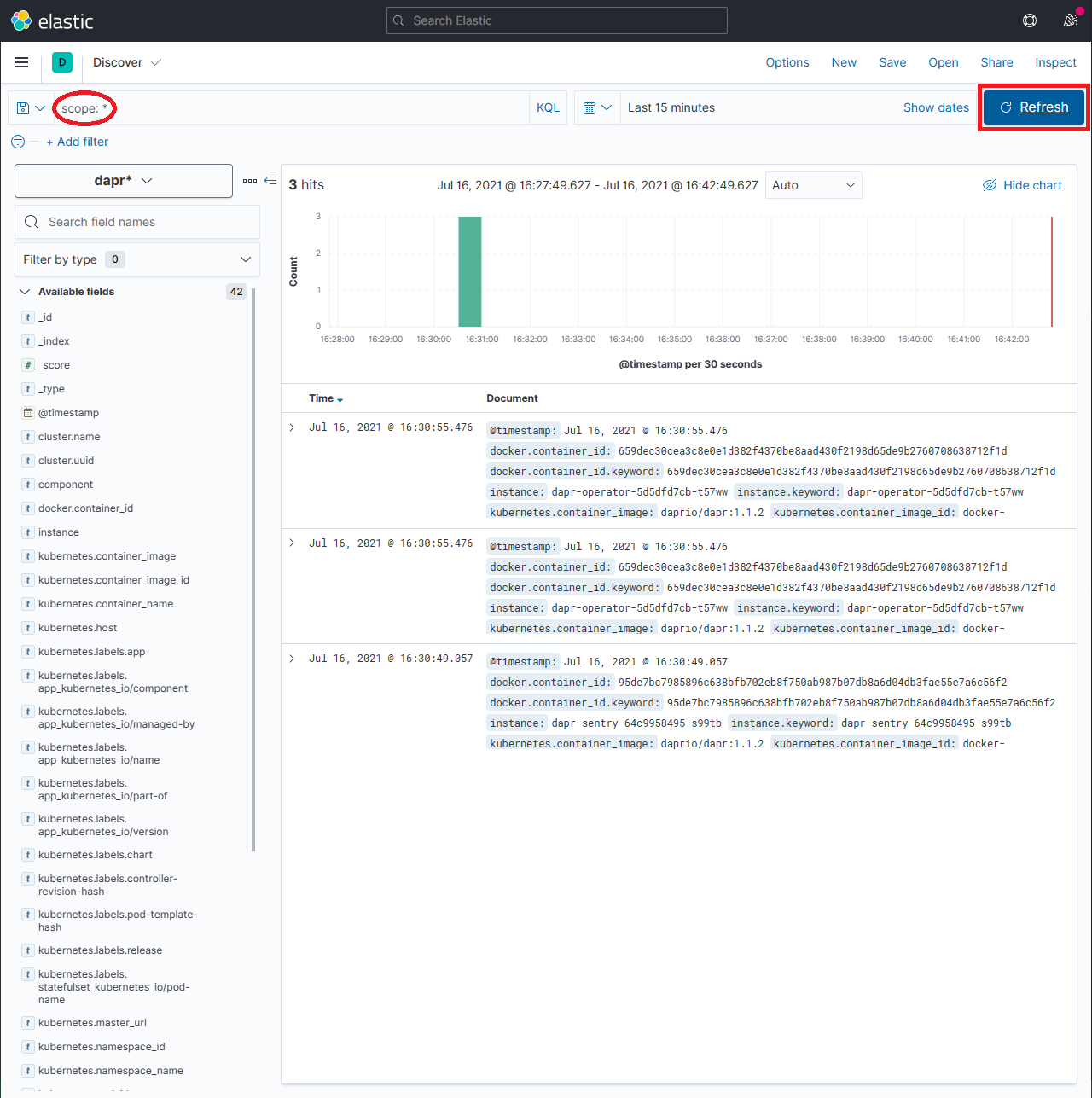
scope:*并点击 Refresh 按钮查看结果。注意:这可能需要很长时间。返回所有结果所需的时间取决于数据量和 Elastic Search 运行的资源大小。
参考资料
3.3 - 操作指南:为 Dapr 日志配置 New Relic
为 Dapr 日志配置 New Relic
前提条件
- 注册一个 New Relic 账户,享受每月 100 GB 的免费数据摄取、1 个免费完全访问用户和无限制的免费基本用户。
背景
New Relic 提供了一个 Fluent Bit 输出 插件,可以轻松地将日志转发到 New Relic Logs。该插件也可以作为独立的 Docker 镜像使用,并在 Kubernetes 集群中以 DaemonSet 的形式安装,我们称之为 Kubernetes 插件。
本文档将解释如何在集群中安装此插件,推荐使用 Helm chart,也可以通过应用 Kubernetes 清单手动安装。
安装
使用 Helm chart 安装(推荐)
按照官方说明安装 Helm。
添加 New Relic 官方 Helm chart 仓库。
运行以下命令通过 Helm 安装 New Relic Logging Kubernetes 插件,并将占位符 YOUR_LICENSE_KEY 替换为您的 New Relic 许可证密钥:
Helm 3
helm install newrelic-logging newrelic/newrelic-logging --set licenseKey=YOUR_LICENSE_KEYHelm 2
helm install newrelic/newrelic-logging --name newrelic-logging --set licenseKey=YOUR_LICENSE_KEY
对于欧盟用户,请在上述命令中添加 --set endpoint=https://log-api.eu.newrelic.com/log/v1。
默认情况下,日志跟踪路径设置为 /var/log/containers/*.log。要更改此设置,请在上述命令中添加 –set fluentBit.path=DESIRED_PATH,并提供您首选的路径。
安装 Kubernetes 清单
下载以下 3 个清单文件到当前工作目录:
curl https://raw.githubusercontent.com/newrelic/helm-charts/master/charts/newrelic-logging/k8s/fluent-conf.yml > fluent-conf.yml curl https://raw.githubusercontent.com/newrelic/helm-charts/master/charts/newrelic-logging/k8s/new-relic-fluent-plugin.yml > new-relic-fluent-plugin.yml curl https://raw.githubusercontent.com/newrelic/helm-charts/master/charts/newrelic-logging/k8s/rbac.yml > rbac.yml在下载的 new-relic-fluent-plugin.yml 文件中,将占位符 LICENSE_KEY 替换为您的 New Relic 许可证密钥。
对于欧盟用户,将 ENDPOINT 环境变量替换为 https://log-api.eu.newrelic.com/log/v1。
添加许可证密钥后,在终端或命令行界面中运行以下命令:
kubectl apply -f .[可选] 您可以通过编辑 fluent-conf.yml 文件中的 parsers.conf 部分来配置插件如何解析数据。有关更多信息,请参阅 Fluent Bit 的 Parsers 配置文档。
默认情况下,日志跟踪路径设置为 /var/log/containers/*.log。要更改此设置,请在 new-relic-fluent-plugin.yml 文件中将默认路径替换为您首选的路径。
查看日志