This is the multi-page printable view of this section. Click here to print.
Error recovery using resiliency policies
- 1: Overview
- 2: Resiliency policies
- 2.1: Timeout resiliency policies
- 2.2: Retry and back-off resiliency policies
- 2.3: Circuit breaker resiliency policies
- 2.4: Default resiliency policies
- 3: Targets
- 4: Health checks
- 4.1: App health checks
- 4.2: Sidecar health
1 - Overview
Dapr provides the capability for defining and applying fault tolerance resiliency policies via a resiliency spec. Resiliency specs are saved in the same location as components specs and are applied when the Dapr sidecar starts. The sidecar determines how to apply resiliency policies to your Dapr API calls.
- In self-hosted mode: The resiliency spec must be named
resiliency.yaml. - In Kubernetes: Dapr finds the named resiliency specs used by your application.
Policies
You can configure Dapr resiliency policies with the following parts:
- Metadata defining where the policy applies (like namespace and scope)
- Policies specifying the resiliency name and behaviors, like:
- Targets determining which interactions these policies act on, including:
- Apps via service invocation
- Components
- Actors
Once defined, you can apply this configuration to your local Dapr components directory, or to your Kubernetes cluster using:
kubectl apply -f <resiliency-spec-name>.yaml
Additionally, you can scope resiliency policies to specific apps.
See known limitations.
Resiliency policy structure
Below is the general structure of a resiliency policy:
apiVersion: dapr.io/v1alpha1
kind: Resiliency
metadata:
name: myresiliency
scopes:
# optionally scope the policy to specific apps
spec:
policies:
timeouts:
# timeout policy definitions
retries:
# retry policy definitions
circuitBreakers:
# circuit breaker policy definitions
targets:
apps:
# apps and their applied policies here
actors:
# actor types and their applied policies here
components:
# components and their applied policies here
Complete example policy
apiVersion: dapr.io/v1alpha1
kind: Resiliency
metadata:
name: myresiliency
# similar to subscription and configuration specs, scopes lists the Dapr App IDs that this
# resiliency spec can be used by.
scopes:
- app1
- app2
spec:
# policies is where timeouts, retries and circuit breaker policies are defined.
# each is given a name so they can be referred to from the targets section in the resiliency spec.
policies:
# timeouts are simple named durations.
timeouts:
general: 5s
important: 60s
largeResponse: 10s
# retries are named templates for retry configurations and are instantiated for life of the operation.
retries:
pubsubRetry:
policy: constant
duration: 5s
maxRetries: 10
retryForever:
policy: exponential
maxInterval: 15s
maxRetries: -1 # retry indefinitely
important:
policy: constant
duration: 5s
maxRetries: 30
someOperation:
policy: exponential
maxInterval: 15s
largeResponse:
policy: constant
duration: 5s
maxRetries: 3
# circuit breakers are automatically instantiated per component and app instance.
# circuit breakers maintain counters that live as long as the Dapr sidecar is running. They are not persisted.
circuitBreakers:
simpleCB:
maxRequests: 1
timeout: 30s
trip: consecutiveFailures >= 5
pubsubCB:
maxRequests: 1
interval: 8s
timeout: 45s
trip: consecutiveFailures > 8
# targets are what named policies are applied to. Dapr supports 3 target types - apps, components and actors
targets:
apps:
appB:
timeout: general
retry: important
# circuit breakers for services are scoped app instance.
# when a breaker is tripped, that route is removed from load balancing for the configured `timeout` duration.
circuitBreaker: simpleCB
actors:
myActorType: # custom Actor Type Name
timeout: general
retry: important
# circuit breakers for actors are scoped by type, id, or both.
# when a breaker is tripped, that type or id is removed from the placement table for the configured `timeout` duration.
circuitBreaker: simpleCB
circuitBreakerScope: both ##
circuitBreakerCacheSize: 5000
components:
# for state stores, policies apply to saving and retrieving state.
statestore1: # any component name -- happens to be a state store here
outbound:
timeout: general
retry: retryForever
# circuit breakers for components are scoped per component configuration/instance. For example myRediscomponent.
# when this breaker is tripped, all interaction to that component is prevented for the configured `timeout` duration.
circuitBreaker: simpleCB
pubsub1: # any component name -- happens to be a pubsub broker here
outbound:
retry: pubsubRetry
circuitBreaker: pubsubCB
pubsub2: # any component name -- happens to be another pubsub broker here
outbound:
retry: pubsubRetry
circuitBreaker: pubsubCB
inbound: # inbound only applies to delivery from sidecar to app
timeout: general
retry: important
circuitBreaker: pubsubCB
Limitations
- Service invocation via gRPC: Currently, resiliency policies are not supported for service invocation via gRPC.
Demos
Watch this video for how to use resiliency:
Learn more about how to write resilient microservices with Dapr.
Next steps
Learn more about resiliency policies and targets:
- Policies
- Targets
Related links
Try out one of the Resiliency quickstarts:
2 - Resiliency policies
Define timeouts, retries, and circuit breaker policies under policies. Each policy is given a name so you can refer to them from the targets section in the resiliency spec.
2.1 - Timeout resiliency policies
Network calls can fail for many reasons, causing your application to wait indefinitely for responses. By setting a timeout duration, you can cut off those unresponsive services, freeing up resources to handle new requests.
Timeouts are optional policies that can be used to early-terminate long-running operations. Set a realistic timeout duration that reflects actual response times in production. If you’ve exceeded a timeout duration:
- The operation in progress is terminated (if possible).
- An error is returned.
Timeout policy format
spec:
policies:
# Timeouts are simple named durations.
timeouts:
timeoutName: timeout1
general: 5s
important: 60s
largeResponse: 10s
Spec metadata
| Field | Details | Example |
| timeoutName | Name of the timeout policy | timeout1 |
| general | Time duration for timeouts marked as “general”. Uses Go’s time.ParseDuration format. No set maximum value. | 15s, 2m, 1h30m |
| important | Time duration for timeouts marked as “important”. Uses Go’s time.ParseDuration format. No set maximum value. | 15s, 2m, 1h30m |
| largeResponse | Time duration for timeouts awaiting a large response. Uses Go’s time.ParseDuration format. No set maximum value. | 15s, 2m, 1h30m |
If you don’t specify a timeout value, the policy does not enforce a time and defaults to whatever you set up per the request client.
Next steps
- Learn more about default resiliency policies
- Learn more about:
Related links
Try out one of the Resiliency quickstarts:
2.2 - Retry and back-off resiliency policies
2.2.1 - Retry resiliency policies
Requests can fail due to transient errors, like encountering network congestion, reroutes to overloaded instances, and more. Sometimes, requests can fail due to other resiliency policies set in place, like triggering a defined timeout or circuit breaker policy.
In these cases, configuring retries can either:
- Send the same request to a different instance, or
- Retry sending the request after the condition has cleared.
Retries and timeouts work together, with timeouts ensuring your system fails fast when needed, and retries recovering from temporary glitches.
Dapr provides default resiliency policies, which you can overwrite with user-defined retry policies.
Important
Each pub/sub component has its own built-in retry behaviors. Explicity applying a Dapr resiliency policy doesn’t override these implicit retry policies. Rather, the resiliency policy augments the built-in retry, which can cause repetitive clustering of messages.Retry policy format
Example 1
spec:
policies:
# Retries are named templates for retry configurations and are instantiated for life of the operation.
retries:
pubsubRetry:
policy: constant
duration: 5s
maxRetries: 10
retryForever:
policy: exponential
maxInterval: 15s
maxRetries: -1 # Retry indefinitely
Example 2
spec:
policies:
retries:
retry5xxOnly:
policy: constant
duration: 5s
maxRetries: 3
matching:
httpStatusCodes: "429,500-599" # retry the HTTP status codes in this range. All others are not retried.
gRPCStatusCodes: "1-4,8-11,13,14" # retry gRPC status codes in these ranges and separate single codes.
Spec metadata
The following retry options are configurable:
| Retry option | Description |
|---|---|
policy |
Determines the back-off and retry interval strategy. Valid values are constant and exponential.Defaults to constant. |
duration |
Determines the time interval between retries. Only applies to the constant policy.Valid values are of the form 200ms, 15s, 2m, etc.Defaults to 5s. |
maxInterval |
Determines the maximum interval between retries to which the exponential back-off policy can grow.Additional retries always occur after a duration of maxInterval. Defaults to 60s. Valid values are of the form 5s, 1m, 1m30s, etc |
maxRetries |
The maximum number of retries to attempt. -1 denotes an unlimited number of retries, while 0 means the request will not be retried (essentially behaving as if the retry policy were not set).Defaults to -1. |
matching.httpStatusCodes |
Optional: a comma-separated string of HTTP status codes or code ranges to retry. Status codes not listed are not retried. Valid values: 100-599, Reference Format: <code> or range <start>-<end>Example: “429,501-503” Default: empty string "" or field is not set. Retries on all HTTP errors. |
matching.gRPCStatusCodes |
Optional: a comma-separated string of gRPC status codes or code ranges to retry. Status codes not listed are not retried. Valid values: 0-16, Reference Format: <code> or range <start>-<end>Example: “4,8,14” Default: empty string "" or field is not set. Retries on all gRPC errors. |
Exponential back-off policy
The exponential back-off window uses the following formula:
BackOffDuration = PreviousBackOffDuration * (Random value from 0.5 to 1.5) * 1.5
if BackOffDuration > maxInterval {
BackoffDuration = maxInterval
}
Retry status codes
When applications span multiple services, especially on dynamic environments like Kubernetes, services can disappear for all kinds of reasons and network calls can start hanging. Status codes provide a glimpse into our operations and where they may have failed in production.
HTTP
The following table includes some examples of HTTP status codes you may receive and whether you should or should not retry certain operations.
| HTTP Status Code | Retry Recommended? | Description |
|---|---|---|
| 404 Not Found | ❌ No | The resource doesn’t exist. |
| 400 Bad Request | ❌ No | Your request is invalid. |
| 401 Unauthorized | ❌ No | Try getting new credentials. |
| 408 Request Timeout | ✅ Yes | The server timed out waiting for the request. |
| 429 Too Many Requests | ✅ Yes | (Respect the Retry-After header, if present). |
| 500 Internal Server Error | ✅ Yes | The server encountered an unexpected condition. |
| 502 Bad Gateway | ✅ Yes | A gateway or proxy received an invalid response. |
| 503 Service Unavailable | ✅ Yes | Service might recover. |
| 504 Gateway Timeout | ✅ Yes | Temporary network issue. |
gRPC
The following table includes some examples of gRPC status codes you may receive and whether you should or should not retry certain operations.
| gRPC Status Code | Retry Recommended? | Description |
|---|---|---|
| Code 1 CANCELLED | ❌ No | N/A |
| Code 3 INVALID_ARGUMENT | ❌ No | N/A |
| Code 4 DEADLINE_EXCEEDED | ✅ Yes | Retry with backoff |
| Code 5 NOT_FOUND | ❌ No | N/A |
| Code 8 RESOURCE_EXHAUSTED | ✅ Yes | Retry with backoff |
| Code 14 UNAVAILABLE | ✅ Yes | Retry with backoff |
Retry filter based on status codes
The retry filter enables granular control over retry policies by allowing users to specify HTTP and gRPC status codes or ranges for which retries should apply.
spec:
policies:
retries:
retry5xxOnly:
# ...
matching:
httpStatusCodes: "429,500-599" # retry the HTTP status codes in this range. All others are not retried.
gRPCStatusCodes: "4,8-11,13,14" # retry gRPC status codes in these ranges and separate single codes.
Note
Field values for status codes must follow the format specified above. An incorrectly formatted value produces an error log (“Could not read resiliency policy”) and thedaprd startup sequence will proceed.
Demo
Watch a demo presented during Diagrid’s Dapr v1.15 celebration to see how to set retry status code filters using Diagrid Conductor
Next steps
- [Learn how to override default retry policies for specific APIs.]({[< ref override-default-retries.md >]})
- Learn how to target your retry policies from the resiliency spec.
- Learn more about:
Related links
Try out one of the Resiliency quickstarts:
2.2.2 - Override default retry resiliency policies
Dapr provides default retries for any unsuccessful request, such as failures and transient errors. Within a resiliency spec, you have the option to override Dapr’s default retry logic by defining policies with reserved, named keywords. For example, defining a policy with the name DaprBuiltInServiceRetries, overrides the default retries for failures between sidecars via service-to-service requests. Policy overrides are not applied to specific targets.
Note: Although you can override default values with more robust retries, you cannot override with lesser values than the provided default value, or completely remove default retries. This prevents unexpected downtime.
Below is a table that describes Dapr’s default retries and the policy keywords to override them:
| Capability | Override Keyword | Default Retry Behavior | Description |
|---|---|---|---|
| Service Invocation | DaprBuiltInServiceRetries | Per call retries are performed with a backoff interval of 1 second, up to a threshold of 3 times. | Sidecar-to-sidecar requests (a service invocation method call) that fail and result in a gRPC code Unavailable or Unauthenticated |
| Actors | DaprBuiltInActorRetries | Per call retries are performed with a backoff interval of 1 second, up to a threshold of 3 times. | Sidecar-to-sidecar requests (an actor method call) that fail and result in a gRPC code Unavailable or Unauthenticated |
| Actor Reminders | DaprBuiltInActorReminderRetries | Per call retries are performed with an exponential backoff with an initial interval of 500ms, up to a maximum of 60s for a duration of 15mins | Requests that fail to persist an actor reminder to a state store |
| Initialization Retries | DaprBuiltInInitializationRetries | Per call retries are performed 3 times with an exponential backoff, an initial interval of 500ms and for a duration of 10s | Failures when making a request to an application to retrieve a given spec. For example, failure to retrieve a subscription, component or resiliency specification |
The resiliency spec example below shows overriding the default retries for all service invocation requests by using the reserved, named keyword ‘DaprBuiltInServiceRetries’.
Also defined is a retry policy called ‘retryForever’ that is only applied to the appB target. appB uses the ‘retryForever’ retry policy, while all other application service invocation retry failures use the overridden ‘DaprBuiltInServiceRetries’ default policy.
spec:
policies:
retries:
DaprBuiltInServiceRetries: # Overrides default retry behavior for service-to-service calls
policy: constant
duration: 5s
maxRetries: 10
retryForever: # A user defined retry policy replaces default retries. Targets rely solely on the applied policy.
policy: exponential
maxInterval: 15s
maxRetries: -1 # Retry indefinitely
targets:
apps:
appB: # app-id of the target service
retry: retryForever
Related links
Try out one of the Resiliency quickstarts:
2.3 - Circuit breaker resiliency policies
Circuit breaker policies are used when other applications/services/components are experiencing elevated failure rates. Circuit breakers reduce load by monitoring the requests and shutting off all traffic to the impacted service when a certain criteria is met.
After a certain number of requests fail, circuit breakers “trip” or open to prevent cascading failures. By doing this, circuit breakers give the service time to recover from their outage instead of flooding it with events.
The circuit breaker can also enter a “half-open” state, allowing partial traffic through to see if the system has healed.
Once requests resume being successful, the circuit breaker gets into “closed” state and allows traffic to completely resume.
Circuit breaker policy format
spec:
policies:
circuitBreakers:
pubsubCB:
maxRequests: 1
interval: 8s
timeout: 45s
trip: consecutiveFailures > 8
Spec metadata
| Retry option | Description |
|---|---|
maxRequests |
The maximum number of requests allowed to pass through when the circuit breaker is half-open (recovering from failure). Defaults to 1. |
interval |
The cyclical period of time used by the circuit breaker to clear its internal counts. If set to 0 seconds, this never clears. Defaults to 0s. |
timeout |
The period of the open state (directly after failure) until the circuit breaker switches to half-open. Defaults to 60s. |
trip |
A Common Expression Language (CEL) statement that is evaluated by the circuit breaker. When the statement evaluates to true, the circuit breaker trips and becomes open. Defaults to consecutiveFailures > 5. Other possible values are requests and totalFailures where requests represents the number of either successful or failed calls before the circuit opens and totalFailures represents the total (not necessarily consecutive) number of failed attempts before the circuit opens. Example: requests > 5 and totalFailures >3. |
Next steps
- Learn more about default resiliency policies
- Learn more about:
Related links
Try out one of the Resiliency quickstarts:
2.4 - Default resiliency policies
In resiliency, you can set default policies, which have a broad scope. This is done through reserved keywords that let Dapr know when to apply the policy. There are 3 default policy types:
DefaultRetryPolicyDefaultTimeoutPolicyDefaultCircuitBreakerPolicy
If these policies are defined, they are used for every operation to a service, application, or component. They can also be modified to be more specific through the appending of additional keywords. The specific policies follow the following pattern, Default%sRetryPolicy, Default%sTimeoutPolicy, and Default%sCircuitBreakerPolicy. Where the %s is replaced by a target of the policy.
Below is a table of all possible default policy keywords and how they translate into a policy name.
| Keyword | Target Operation | Example Policy Name |
|---|---|---|
App |
Service invocation. | DefaultAppRetryPolicy |
Actor |
Actor invocation. | DefaultActorTimeoutPolicy |
Component |
All component operations. | DefaultComponentCircuitBreakerPolicy |
ComponentInbound |
All inbound component operations. | DefaultComponentInboundRetryPolicy |
ComponentOutbound |
All outbound component operations. | DefaultComponentOutboundTimeoutPolicy |
StatestoreComponentOutbound |
All statestore component operations. | DefaultStatestoreComponentOutboundCircuitBreakerPolicy |
PubsubComponentOutbound |
All outbound pubusub (publish) component operations. | DefaultPubsubComponentOutboundRetryPolicy |
PubsubComponentInbound |
All inbound pubsub (subscribe) component operations. | DefaultPubsubComponentInboundTimeoutPolicy |
BindingComponentOutbound |
All outbound binding (invoke) component operations. | DefaultBindingComponentOutboundCircuitBreakerPolicy |
BindingComponentInbound |
All inbound binding (read) component operations. | DefaultBindingComponentInboundRetryPolicy |
SecretstoreComponentOutbound |
All secretstore component operations. | DefaultSecretstoreComponentTimeoutPolicy |
ConfigurationComponentOutbound |
All configuration component operations. | DefaultConfigurationComponentOutboundCircuitBreakerPolicy |
LockComponentOutbound |
All lock component operations. | DefaultLockComponentOutboundRetryPolicy |
Policy hierarchy resolution
Default policies are applied if the operation being executed matches the policy type and if there is no more specific policy targeting it. For each target type (app, actor, and component), the policy with the highest priority is a Named Policy, one that targets that construct specifically.
If none exists, the policies are applied from most specific to most broad.
How default policies and built-in retries work together
In the case of the built-in retries, default policies do not stop the built-in retry policies from running. Both are used together but only under specific circumstances.
For service and actor invocation, the built-in retries deal specifically with issues connecting to the remote sidecar (when needed). As these are important to the stability of the Dapr runtime, they are not disabled unless a named policy is specifically referenced for an operation. In some instances, there may be additional retries from both the built-in retry and the default retry policy, but this prevents an overly weak default policy from reducing the sidecar’s availability/success rate.
Policy resolution hierarchy for applications, from most specific to most broad:
- Named Policies in App Targets
- Default App Policies / Built-In Service Retries
- Default Policies / Built-In Service Retries
Policy resolution hierarchy for actors, from most specific to most broad:
- Named Policies in Actor Targets
- Default Actor Policies / Built-In Actor Retries
- Default Policies / Built-In Actor Retries
Policy resolution hierarchy for components, from most specific to most broad:
- Named Policies in Component Targets
- Default Component Type + Component Direction Policies / Built-In Actor Reminder Retries (if applicable)
- Default Component Direction Policies / Built-In Actor Reminder Retries (if applicable)
- Default Component Policies / Built-In Actor Reminder Retries (if applicable)
- Default Policies / Built-In Actor Reminder Retries (if applicable)
As an example, take the following solution consisting of three applications, three components and two actor types:
Applications:
- AppA
- AppB
- AppC
Components:
- Redis Pubsub: pubsub
- Redis statestore: statestore
- CosmosDB Statestore: actorstore
Actors:
- EventActor
- SummaryActor
Below is policy that uses both default and named policies as applies these to the targets.
spec:
policies:
retries:
# Global Retry Policy
DefaultRetryPolicy:
policy: constant
duration: 1s
maxRetries: 3
# Global Retry Policy for Apps
DefaultAppRetryPolicy:
policy: constant
duration: 100ms
maxRetries: 5
# Global Retry Policy for Apps
DefaultActorRetryPolicy:
policy: exponential
maxInterval: 15s
maxRetries: 10
# Global Retry Policy for Inbound Component operations
DefaultComponentInboundRetryPolicy:
policy: constant
duration: 5s
maxRetries: 5
# Global Retry Policy for Statestores
DefaultStatestoreComponentOutboundRetryPolicy:
policy: exponential
maxInterval: 60s
maxRetries: -1
# Named policy
fastRetries:
policy: constant
duration: 10ms
maxRetries: 3
# Named policy
retryForever:
policy: exponential
maxInterval: 10s
maxRetries: -1
targets:
apps:
appA:
retry: fastRetries
appB:
retry: retryForever
actors:
EventActor:
retry: retryForever
components:
actorstore:
retry: fastRetries
The table below is a break down of which policies are applied when attempting to call the various targets in this solution.
| Target | Policy Used |
|---|---|
| AppA | fastRetries |
| AppB | retryForever |
| AppC | DefaultAppRetryPolicy / DaprBuiltInActorRetries |
| pubsub - Publish | DefaultRetryPolicy |
| pubsub - Subscribe | DefaultComponentInboundRetryPolicy |
| statestore | DefaultStatestoreComponentOutboundRetryPolicy |
| actorstore | fastRetries |
| EventActor | retryForever |
| SummaryActor | DefaultActorRetryPolicy |
Next steps
Learn how to override default retry policies.
Related links
Try out one of the Resiliency quickstarts:
3 - Targets
Targets
Named policies are applied to targets. Dapr supports three target types that apply all Dapr building block APIs:
appscomponentsactors
Apps
With the apps target, you can apply retry, timeout, and circuitBreaker policies to service invocation calls between Dapr apps. Under targets/apps, policies are applied to each target service’s app-id. The policies are invoked when a failure occurs in communication between sidecars, as shown in the diagram below.
Dapr provides built-in service invocation retries, so any applied
retrypolicies are additional.
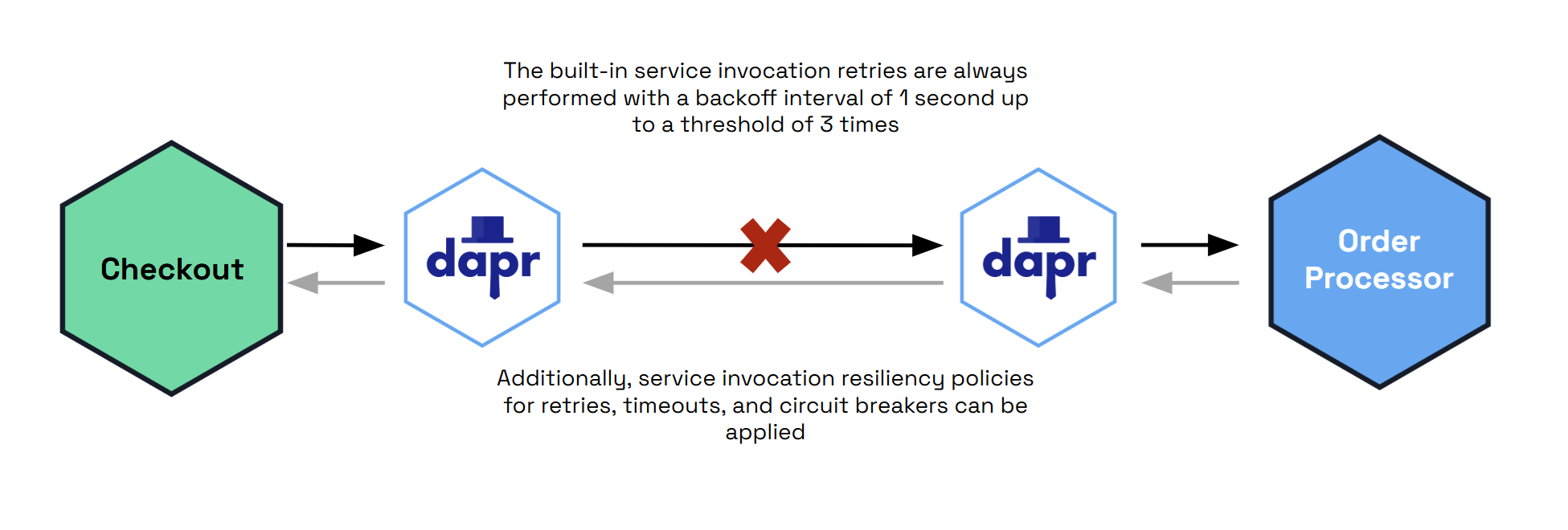
Example of policies to a target app with the app-id “appB”:
specs:
targets:
apps:
appB: # app-id of the target service
timeout: general
retry: general
circuitBreaker: general
Components
With the components target, you can apply retry, timeout and circuitBreaker policies to component operations.
Policies can be applied for outbound operations (calls to the Dapr sidecar) and/or inbound (the sidecar calling your app).
Outbound
outbound operations are calls from the sidecar to a component, such as:
- Persisting or retrieving state.
- Publishing a message on a PubSub component.
- Invoking an output binding.
Some components may have built-in retry capabilities and are configured on a per-component basis.
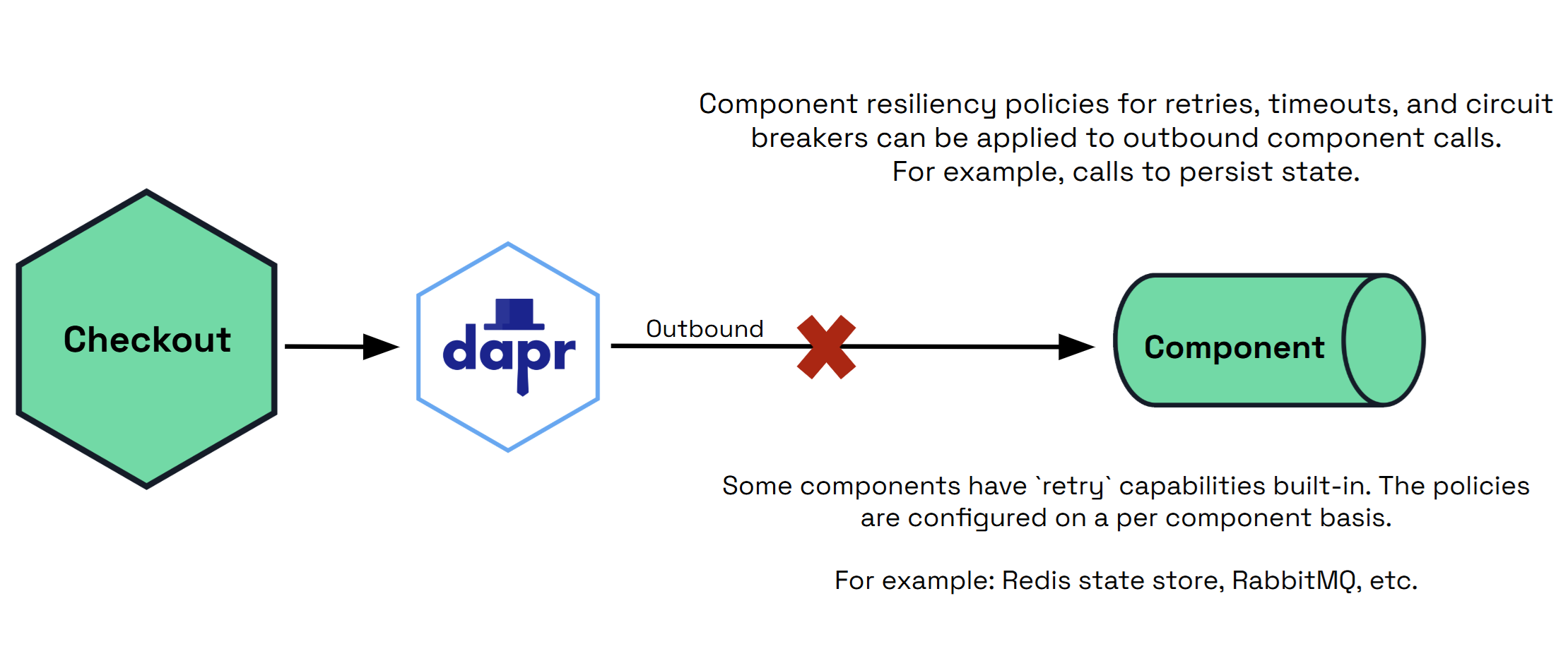
spec:
targets:
components:
myStateStore:
outbound:
retry: retryForever
circuitBreaker: simpleCB
Inbound
inbound operations are calls from the sidecar to your application, such as:
- PubSub subscriptions when delivering a message.
- Input bindings.
Some components may have built-in retry capabilities and are configured on a per-component basis.
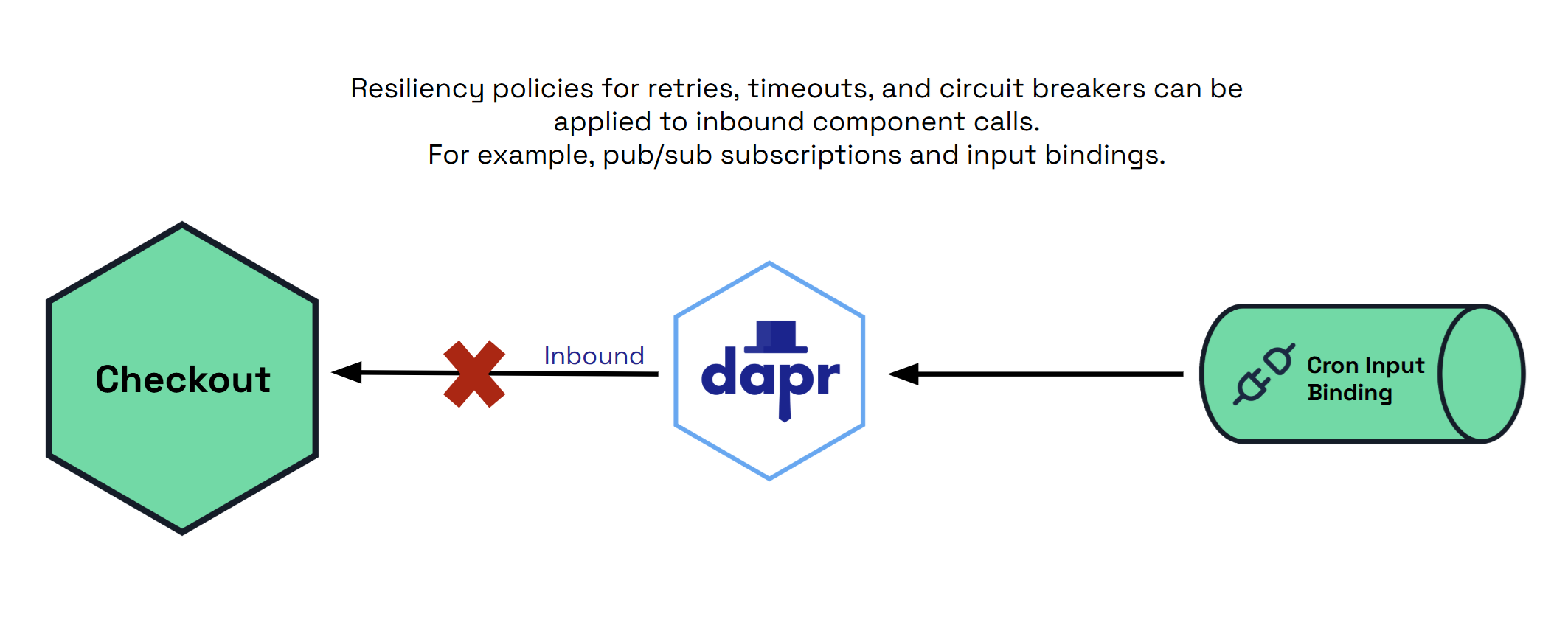
spec:
targets:
components:
myInputBinding:
inbound:
timeout: general
retry: general
circuitBreaker: general
PubSub
In a PubSub target/component, you can specify both inbound and outbound operations.
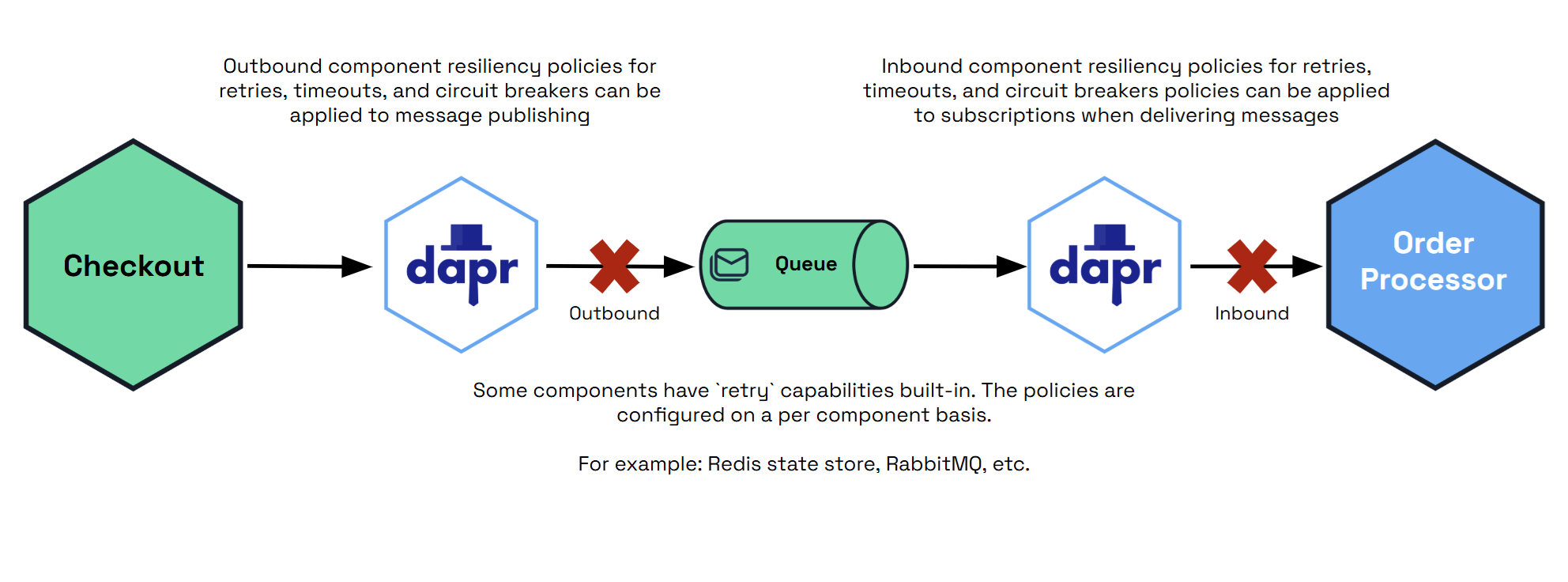
spec:
targets:
components:
myPubsub:
outbound:
retry: pubsubRetry
circuitBreaker: pubsubCB
inbound: # inbound only applies to delivery from sidecar to app
timeout: general
retry: general
circuitBreaker: general
Actors
With the actors target, you can apply retry, timeout, and circuitBreaker policies to actor operations.
When using a circuitBreaker policy for the actors target, you can specify how circuit breaking state should be scoped by using circuitBreakerScope:
id: an individual actor IDtype: all actors of a given actor typeboth: both of the above
You can also specify a cache size for the number of circuit breakers to keep in memory with the circuitBreakerCacheSize property, providing an integer value, e.g. 5000.
Example
spec:
targets:
actors:
myActorType:
timeout: general
retry: general
circuitBreaker: general
circuitBreakerScope: both
circuitBreakerCacheSize: 5000
Next steps
Try out one of the Resiliency quickstarts:
4 - Health checks
4.1 - App health checks
The app health checks feature allows probing for the health of your application and reacting to status changes.
Applications can become unresponsive for a variety of reasons. For example, your application:
- Could be too busy to accept new work;
- Could have crashed; or
- Could be in a deadlock state.
Sometimes the condition can be transitory, for example:
- If the app is just busy and will resume accepting new work eventually
- If the application is being restarted for whatever reason and is in its initialization phase
App health checks are disabled by default. Once you enable app health checks, the Dapr runtime (sidecar) periodically polls your application via HTTP or gRPC calls. When it detects a failure in the app’s health, Dapr stops accepting new work on behalf of the application by:
- Unsubscribing from all pub/sub subscriptions
- Stopping all input bindings
- Short-circuiting all service-invocation requests, which terminate in the Dapr runtime and are not forwarded to the application
- Unregistering Dapr Actor types, thereby causing Actor instances to migrate to a different replica if one is available
These changes are meant to be temporary, and Dapr resumes normal operations once it detects that the application is responsive again.

App health checks vs platform-level health checks
App health checks in Dapr are meant to be complementary to, and not replace, any platform-level health checks, like liveness probes when running on Kubernetes.
Platform-level health checks (or liveness probes) generally ensure that the application is running, and cause the platform to restart the application in case of failures.
Unlike platform-level health checks, Dapr’s app health checks focus on pausing work to an application that is currently unable to accept it, but is expected to be able to resume accepting work eventually. Goals include:
- Not bringing more load to an application that is already overloaded.
- Do the “polite” thing by not taking messages from queues, bindings, or pub/sub brokers when Dapr knows the application won’t be able to process them.
In this regard, Dapr’s app health checks are “softer”, waiting for an application to be able to process work, rather than terminating the running process in a “hard” way.
Note
For Kubernetes, a failing app health check won’t remove a pod from service discovery: this remains the responsibility of the Kubernetes liveness probe, not Dapr.Configuring app health checks
App health checks are disabled by default, but can be enabled with either:
- The
--enable-app-health-checkCLI flag; or - The
dapr.io/enable-app-health-check: trueannotation when running on Kubernetes.
Adding this flag is both necessary and sufficient to enable app health checks with the default options.
The full list of options are listed in this table:
| CLI flags | Kubernetes deployment annotation | Description | Default value |
|---|---|---|---|
--enable-app-health-check |
dapr.io/enable-app-health-check |
Boolean that enables the health checks | Disabled |
--app-health-check-path |
dapr.io/app-health-check-path |
Path that Dapr invokes for health probes when the app channel is HTTP (this value is ignored if the app channel is using gRPC) | /healthz |
--app-health-probe-interval |
dapr.io/app-health-probe-interval |
Number of seconds between each health probe | 5 |
--app-health-probe-timeout |
dapr.io/app-health-probe-timeout |
Timeout in milliseconds for health probe requests | 500 |
--app-health-threshold |
dapr.io/app-health-threshold |
Max number of consecutive failures before the app is considered unhealthy | 3 |
See the full Dapr arguments and annotations reference for all options and how to enable them.
Additionally, app health checks are impacted by the protocol used for the app channel, which is configured with the following flag or annotation:
| CLI flag | Kubernetes deployment annotation | Description | Default value |
|---|---|---|---|
--app-protocol |
dapr.io/app-protocol |
Protocol used for the app channel. supported values are http, grpc, https, grpcs, and h2c (HTTP/2 Cleartext). |
http |
Note
A low app health probe timeout value can classify an application as unhealthy if it experiences a sudden high load, causing the response time to degrade. If this happens, increase thedapr.io/app-health-probe-timeout value.
Health check paths
HTTP
When using HTTP (including http, https, and h2c) for app-protocol, Dapr performs health probes by making an HTTP call to the path specified in app-health-check-path, which is /health by default.
For your app to be considered healthy, the response must have an HTTP status code in the 200-299 range. Any other status code is considered a failure. Dapr is only concerned with the status code of the response, and ignores any response header or body.
gRPC
When using gRPC for the app channel (app-protocol set to grpc or grpcs), Dapr invokes the method /dapr.proto.runtime.v1.AppCallbackHealthCheck/HealthCheck in your application. Most likely, you will use a Dapr SDK to implement the handler for this method.
While responding to a health probe request, your app may decide to perform additional internal health checks to determine if it’s ready to process work from the Dapr runtime. However, this is not required; it’s a choice that depends on your application’s needs.
Intervals, timeouts, and thresholds
Intervals
By default, when app health checks are enabled, Dapr probes your application every 5 seconds. You can configure the interval, in seconds, with app-health-probe-interval. These probes happen regularly, regardless of whether your application is healthy or not.
Timeouts
When the Dapr runtime (sidecar) is initially started, Dapr waits for a successful health probe before considering the app healthy. This means that pub/sub subscriptions, input bindings, and service invocation requests won’t be enabled for your application until this first health check is complete and successful.
Health probe requests are considered successful if the application sends a successful response (as explained above) within the timeout configured in app-health-probe-timeout. The default value is 500, corresponding to 500 milliseconds (half a second).
Thresholds
Before Dapr considers an app to have entered an unhealthy state, it will wait for app-health-threshold consecutive failures, whose default value is 3. This default value means that your application must fail health probes 3 times in a row to be considered unhealthy.
If you set the threshold to 1, any failure causes Dapr to assume your app is unhealthy and will stop delivering work to it.
A threshold greater than 1 can help exclude transient failures due to external circumstances. The right value for your application depends on your requirements.
Thresholds only apply to failures. A single successful response is enough for Dapr to consider your app to be healthy and resume normal operations.
Example
Use the CLI flags with the dapr run command to enable app health checks:
dapr run \
--app-id my-app \
--app-port 7001 \
--app-protocol http \
--enable-app-health-check \
--app-health-check-path=/healthz \
--app-health-probe-interval 3 \
--app-health-probe-timeout 200 \
--app-health-threshold 2 \
-- \
<command to execute>
To enable app health checks in Kubernetes, add the relevant annotations to your Deployment:
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-app
labels:
app: my-app
spec:
template:
metadata:
labels:
app: my-app
annotations:
dapr.io/enabled: "true"
dapr.io/app-id: "my-app"
dapr.io/app-port: "7001"
dapr.io/app-protocol: "http"
dapr.io/enable-app-health-check: "true"
dapr.io/app-health-check-path: "/healthz"
dapr.io/app-health-probe-interval: "3"
dapr.io/app-health-probe-timeout: "200"
dapr.io/app-health-threshold: "2"
Demo
Watch this video for an overview of using app health checks:
4.2 - Sidecar health
Dapr provides a way to determine its health using an HTTP /healthz endpoint. With this endpoint, the daprd process, or sidecar, can be:
- Probed for its overall health
- Probed for Dapr sidecar readiness from infrastructure platforms
- Determined for readiness and liveness with Kubernetes
In this guide, you learn how the Dapr /healthz endpoint integrates with health probes from the application hosting platform (for example, Kubernetes) as well as the Dapr SDKs.
Important
Do not depend on the/healthz endpoint in your application code. Having your application depend on the /healthz endpoint will fail for some cases (such as apps using Actor and Workflow APIs) and is considered bad practice in others as it creates a circular dependency. The /healthz endpoint is designed for infrastructure health checks (like Kubernetes probes), not for application-level health validation.
Note
Dapr actors also have a health API endpoint where Dapr probes the application for a response to a signal from Dapr that the actor application is healthy and running. See actor health API.The following diagram shows the steps when a Dapr sidecar starts, the healthz endpoint and when the app channel is initialized.
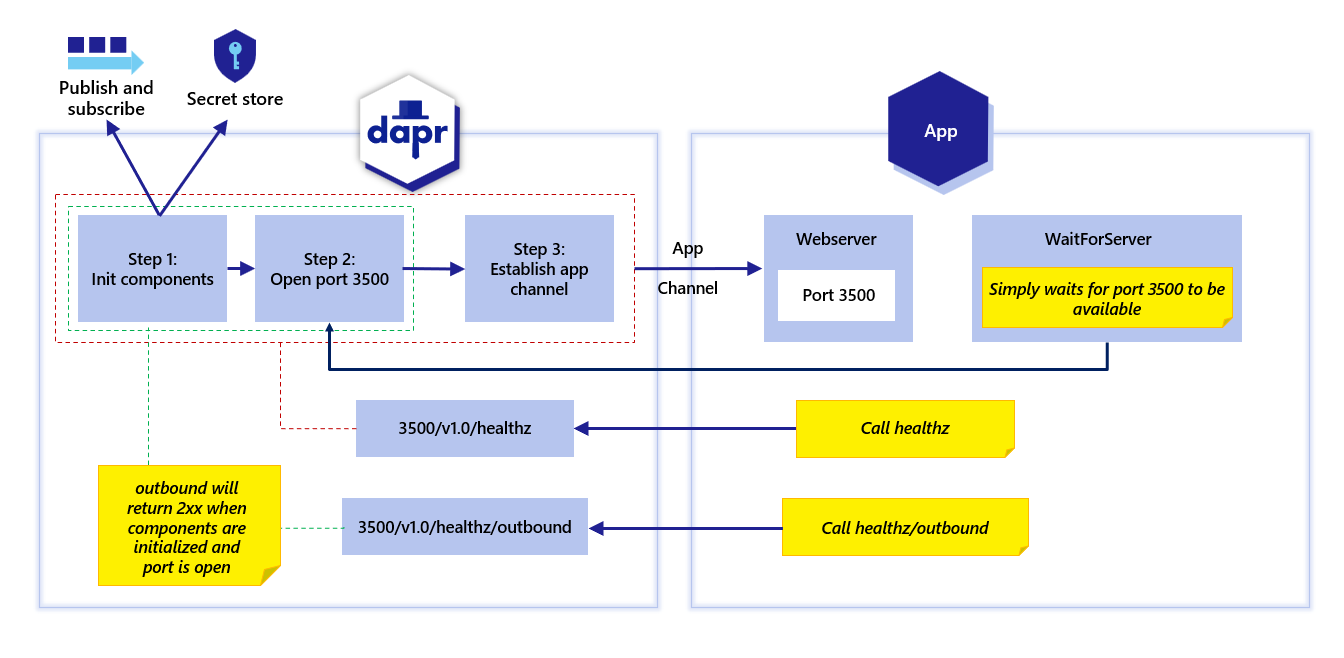
Outbound health endpoint
As shown by the red boundary lines in the diagram above, the v1.0/healthz/ endpoint is used to wait for when:
- All components are initialized;
- The Dapr HTTP port is available; and,
- The app channel is initialized.
This is used to check the complete initialization of the Dapr sidecar and its health.
Setting the DAPR_HEALTH_TIMEOUT environment variable lets you control the health timeout, which, for example, can be important in different environments with higher latency.
On the other hand, as shown by the green boundary lines in the diagram above, the v1.0/healthz/outbound endpoint returns successfully when:
- All the components are initialized;
- The Dapr HTTP port is available; but,
- The app channel is not yet established.
In the Dapr SDKs, the waitForSidecar/wait_until_ready method (depending on which SDK you use) is used for this specific check with the v1.0/healthz/outbound endpoint. Using this behavior, instead of waiting for the app channel to be available (see: red boundary lines) with the v1.0/healthz/ endpoint, Dapr waits for a successful response from v1.0/healthz/outbound. This approach enables your application to perform calls on the Dapr sidecar APIs before the app channel is initalized - for example, reading secrets with the secrets API.
If you are using the waitForSidecar/wait_until_ready method on the SDKs, then the correct initialization is performed. Otherwise, you can call the v1.0/healthz/outbound endpoint during initalization, and if successesful, you can call the Dapr sidecar APIs.
SDKs supporting outbound health endpoint
Currently, the v1.0/healthz/outbound endpoint is supported in the:
Health endpoint: Integration with Kubernetes
When deploying Dapr to a hosting platform like Kubernetes, the Dapr health endpoint is automatically configured for you.
Kubernetes uses readiness and liveness probes to determines the health of the container.
Liveness
The kubelet uses liveness probes to know when to restart a container. For example, liveness probes could catch a deadlock (a running application that is unable to make progress). Restarting a container in such a state can help to make the application more available despite having bugs.
How to configure a liveness probe in Kubernetes
In the pod configuration file, the liveness probe is added in the containers spec section as shown below:
livenessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 3
periodSeconds: 3
In the above example, the periodSeconds field specifies that the kubelet should perform a liveness probe every 3 seconds. The initialDelaySeconds field tells the kubelet that it should wait 3 seconds before performing the first probe. To perform a probe, the kubelet sends an HTTP GET request to the server that is running in the container and listening on port 8080. If the handler for the server’s /healthz path returns a success code, the kubelet considers the container to be alive and healthy. If the handler returns a failure code, the kubelet kills the container and restarts it.
Any HTTP status code between 200 and 399 indicates success; any other status code indicates failure.
Readiness
The kubelet uses readiness probes to know when a container is ready to start accepting traffic. A pod is considered ready when all of its containers are ready. One use of this readiness signal is to control which pods are used as backends for Kubernetes services. When a pod is not ready, it is removed from Kubernetes service load balancers.
Note
The Dapr sidecar will be in ready state once the application is accessible on its configured port. The application cannot access the Dapr components during application start up/initialization.How to configure a readiness probe in Kubernetes
Readiness probes are configured similarly to liveness probes. The only difference is that you use the readinessProbe field instead of the livenessProbe field:
readinessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 3
periodSeconds: 3
Sidecar Injector
When integrating with Kubernetes, the Dapr sidecar is injected with a Kubernetes probe configuration telling it to use the Dapr healthz endpoint. This is done by the “Sidecar Injector” system service. The integration with the kubelet is shown in the diagram below.
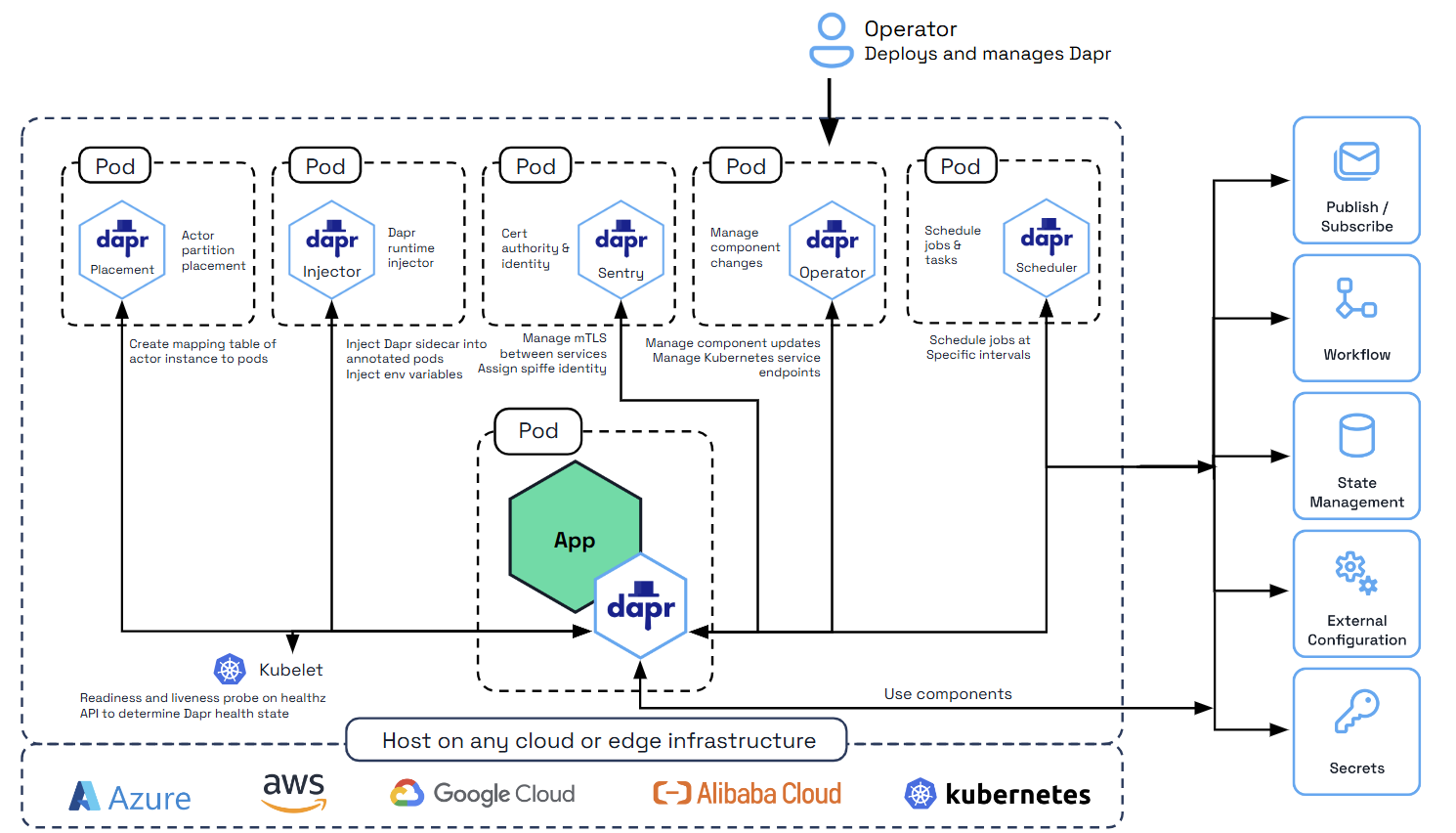
How the Dapr sidecar health endpoint is configured with Kubernetes
As mentioned above, this configuration is done automatically by the Sidecar Injector service. This section describes the specific values that are set on the liveness and readiness probes.
Dapr has its HTTP health endpoint /v1.0/healthz on port 3500. This can be used with Kubernetes for readiness and liveness probe. When the Dapr sidecar is injected, the readiness and liveness probes are configured in the pod configuration file with the following values:
livenessProbe:
httpGet:
path: v1.0/healthz
port: 3500
initialDelaySeconds: 5
periodSeconds: 10
timeoutSeconds : 5
failureThreshold : 3
readinessProbe:
httpGet:
path: v1.0/healthz
port: 3500
initialDelaySeconds: 5
periodSeconds: 10
timeoutSeconds : 5
failureThreshold: 3
Delay graceful shutdown
Dapr accepts a dapr.io/block-shutdown-duration annotation or --dapr-block-shutdown-duration CLI flag, which delays the full shutdown procedure for the specified duration, or until the app reports as unhealthy, whichever is sooner.
During this period, all subscriptions and input bindings are closed. This is useful for applications that need to use the Dapr APIs as part of their own shutdown procedure.
Applicable annotations or CLI flags include:
--dapr-graceful-shutdown-seconds/dapr.io/graceful-shutdown-seconds--dapr-block-shutdown-duration/dapr.io/block-shutdown-duration--dapr-graceful-shutdown-seconds/dapr.io/graceful-shutdown-seconds--dapr-block-shutdown-duration/dapr.io/block-shutdown-duration
Learn more about these and how to use them in the Annotations and arguments guide.