This is the multi-page printable view of this section. Click here to print.
Jobs
1 - Jobs overview
Many applications require job scheduling, or the need to take an action in the future. The jobs API is an orchestrator for scheduling these future jobs, either at a specific time or for a specific interval.
Not only does the jobs API help you with scheduling jobs, but internally, Dapr uses the Scheduler service to schedule actor reminders.
Jobs in Dapr consist of:
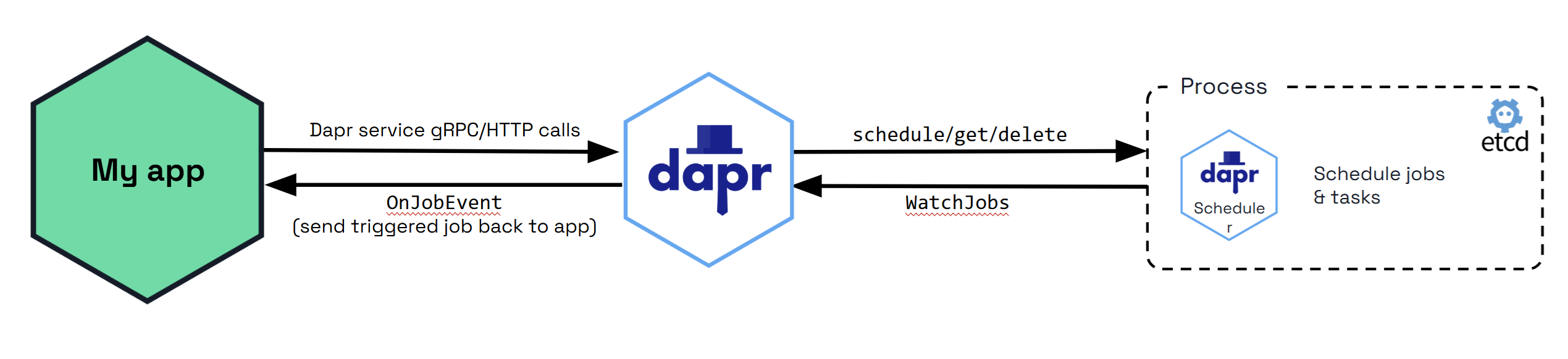
How it works
The jobs API is a job scheduler, not the executor which runs the job. The design guarantees at least once job execution with a bias towards durability and horizontal scaling over precision. This means:
- Guaranteed: A job is never invoked before the schedule time is due.
- Not guaranteed: A ceiling time on when the job is invoked after the due time is reached.
All job details and user-associated data for scheduled jobs are stored in an embedded Etcd database in the Scheduler service. You can use jobs to:
- Delay your pub/sub messaging. You can publish a message in a future specific time (for example: a week from today, or a specific UTC date/time).
- Schedule service invocation method calls between applications.
Scenarios
Job scheduling can prove helpful in the following scenarios:
Automated Database Backups: Ensure a database is backed up daily to prevent data loss. Schedule a backup script to run every night at 2 AM, which will create a backup of the database and store it in a secure location.
Regular Data Processing and ETL (Extract, Transform, Load): Process and transform raw data from various sources and load it into a data warehouse. Schedule ETL jobs to run at specific times (for example: hourly, daily) to fetch new data, process it, and update the data warehouse with the latest information.
Email Notifications and Reports: Receive daily sales reports and weekly performance summaries via email. Schedule a job that generates the required reports and sends them via email at 6 a.m. every day for daily reports and 8 a.m. every Monday for weekly summaries.
Maintenance Tasks and System Updates: Perform regular maintenance tasks such as clearing temporary files, updating software, and checking system health. Schedule various maintenance scripts to run at off-peak hours, such as weekends or late nights, to minimize disruption to users.
Batch Processing for Financial Transactions: Processes a large number of transactions that need to be batched and settled at the end of each business day. Schedule batch processing jobs to run at 5 PM every business day, aggregating the day’s transactions and performing necessary settlements and reconciliations.
Dapr’s jobs API ensures the tasks represented in these scenarios are performed consistently and reliably without manual intervention, improving efficiency and reducing the risk of errors.
Features
The main functionality of the Jobs API allows you to create, retrieve, and delete scheduled jobs. By default, when you create a job with a name that already exists, the operation fails unless you explicitly set the overwrite flag to true. This ensures that existing jobs are not accidentally modified or overwritten.
Schedule jobs across multiple replicas
When you create a job, it does not replace an existing job with the same name, unless you explicitly set the overwrite flag. This means that every time a job is created, it resets the count and only keeps 1 record in the embedded etcd for that job. Therefore, you don’t need to worry about multiple jobs being created and firing off — only the most recent job is recorded and executed, even if all your apps schedule the same job on startup.
The Scheduler service enables the scheduling of jobs to scale across multiple replicas, while guaranteeing that a job is only triggered by 1 Scheduler service instance.
Try out the jobs API
You can try out the jobs API in your application. After Dapr is installed, you can begin using the jobs API, starting with the How-to: Schedule jobs guide.
Next steps
2 - Features and concepts
Now that you’ve learned about the jobs building block at a high level, let’s deep dive into the features and concepts included with Dapr Jobs and the various SDKs. Dapr Jobs:
- Provides a robust and scalable API for scheduling operations to be triggered in the future.
- Exposes several capabilities which are common across all supported languages.
Job identity
All jobs are registered with a case-sensitive job name. These names are intended to be unique across all services interfacing with the Dapr runtime. The name is used as an identifier when creating and modifying the job as well as to indicate which job a triggered invocation is associated with.
Only one job can be associated with a name at any given time. By default, any attempt to create a new job using the same name as an existing job results in an error. However, if the overwrite flag is set to true, the new job overwrites the existing job with the same name.
Scheduling Jobs
A job can be scheduled using any of the following mechanisms:
- Intervals using Cron expressions, duration values, or period expressions
- Specific dates and times
For all time-based schedules, if a timestamp is provided with a time zone via the RFC3339 specification, that time zone is used. When not provided, the time zone used by the server running Dapr is used. In other words, do not assume that times run in UTC time zone, unless otherwise specified when scheduling the job.
Schedule using a Cron expression
When scheduling a job to execute on a specific interval using a Cron expression, the expression is written using 6 fields spanning the values specified in the table below:
| seconds | minutes | hours | day of month | month | day of week |
|---|---|---|---|---|---|
| 0-59 | 0-59 | 0-23 | 1-31 | 1-12/jan-dec | 0-6/sun-sat |
Example 1
"0 30 * * * *" triggers every hour on the half-hour mark.
Example 2
"0 15 3 * * *" triggers every day at 03:15.
Schedule using a duration value
You can schedule jobs using a Go duration string, in which
a string consists of a (possibly) signed sequence of decimal numbers, each with an optional fraction and a unit suffix.
Valid time units are "ns", "us", "ms", "s", "m", or "h".
Example 1
"2h45m" triggers every 2 hours and 45 minutes.
Example 2
"37m25s" triggers every 37 minutes and 25 seconds.
Schedule using a period expression
The following period expressions are supported. The “@every” expression also accepts a Go duration string.
| Entry | Description | Equivalent Cron expression |
|---|---|---|
| @every | Run every (e.g. “@every 1h30m”) | N/A |
| @yearly (or @annually) | Run once a year, midnight, January 1st | 0 0 0 1 1 * |
| @monthly | Run once a month, midnight, first of month | 0 0 0 1 * * |
| @weekly | Run once a week, midnight on Sunday | 0 0 0 * * 0 |
| @daily or @midnight | Run once a day at midnight | 0 0 0 * * * |
| @hourly | Run once an hour at the beginning of the hour | 0 0 * * * * |
Schedule using a specific date/time
A job can also be scheduled to run at a particular point in time by providing a date using the RFC3339 specification.
Example 1
"2025-12-09T16:09:53+00:00" Indicates that the job should be run on December 9, 2025 at 4:09:53 PM UTC.
Scheduled triggers
When a scheduled Dapr job is triggered, the runtime sends a message back to the service that scheduled the job using either the HTTP or gRPC approach, depending on which is registered with Dapr when the service starts.
gRPC
When a job reaches its scheduled trigger time, the triggered job is sent back to the application via the following callback function:
Note: The following example is in Go, but applies to any programming language with gRPC support.
import rtv1 "github.com/dapr/dapr/pkg/proto/runtime/v1"
...
func (s *JobService) OnJobEventAlpha1(ctx context.Context, in *rtv1.JobEventRequest) (*rtv1.JobEventResponse, error) {
// Handle the triggered job
}
This function processes the triggered jobs within the context of your gRPC server. When you set up the server, ensure that you register the callback server, which invokes this function when a job is triggered:
...
js := &JobService{}
rtv1.RegisterAppCallbackAlphaServer(server, js)
In this setup, you have full control over how triggered jobs are received and processed, as they are routed directly through this gRPC method.
HTTP
If a gRPC server isn’t registered with Dapr when the application starts up, Dapr instead triggers jobs by making a
POST request to the endpoint /job/<job-name>. The body includes the following information about the job:
Schedule: When the job triggers occurRepeatCount: An optional value indicating how often the job should repeatDueTime: An optional point in time representing either the one time when the job should execute (if not recurring) or the not-before time from which the schedule should take effectTtl: An optional value indicating when the job should expirePayload: A collection of bytes containing data originally stored when the job was scheduledOverwrite: A flag to allow the requested job to overwrite an existing job with the same name, if it already exists.FailurePolicy: An optional failure policy for the job.
The DueTime and Ttl fields will reflect an RC3339 timestamp value reflective of the time zone provided when the job was
originally scheduled. If no time zone was provided, these values indicate the time zone used by the server running
Dapr.
3 - How-To: Schedule and handle triggered jobs
Now that you’ve learned what the jobs building block provides, let’s look at an example of how to use the API. The code example below describes an application that schedules jobs for a database backup application and handles them at trigger time, also known as the time the job was sent back to the application because it reached it’s dueTime.
Start the Scheduler service
When you run dapr init in either self-hosted mode or on Kubernetes, the Dapr Scheduler service is started.
Set up the Jobs API
In your code, set up and schedule jobs within your application.
The following .NET SDK code sample schedules the job named prod-db-backup. The job data contains information
about the database that you’ll be seeking to backup regularly. Over the course of this example, you’ll:
- Define types used in the rest of the example
- Register an endpoint during application startup that handles all job trigger invocations on the service
- Register the job with Dapr
In the following example, you’ll create records that you’ll serialize and register alongside the job so the information is available when the job is triggered in the future:
- The name of the backup task (
db-backup) - The backup task’s
Metadata, including:- The database name (
DBName) - The database location (
BackupLocation)
- The database name (
Create an ASP.NET Core project and add the latest version of Dapr.Jobs from NuGet.
Note: While it’s not strictly necessary for your project to use the
Microsoft.NET.Sdk.WebSDK to create jobs, as of the time this documentation is authored, only the service that schedules a job receives trigger invocations for it. As those invocations expect an endpoint that can handle the job trigger and requires theMicrosoft.NET.Sdk.WebSDK, it’s recommended that you use an ASP.NET Core project for this purpose.
Start by defining types to persist our backup job data and apply our own JSON property name attributes to the properties so they’re consistent with other language examples.
//Define the types that we'll represent the job data with
internal sealed record BackupJobData([property: JsonPropertyName("task")] string Task, [property: JsonPropertyName("metadata")] BackupMetadata Metadata);
internal sealed record BackupMetadata([property: JsonPropertyName("DBName")]string DatabaseName, [property: JsonPropertyName("BackupLocation")] string BackupLocation);
Next, set up a handler as part of your application setup that will be called anytime a job is triggered on your application. It’s the responsibility of this handler to identify how jobs should be processed based on the job name provided.
This works by registering a handler with ASP.NET Core at /job/<job-name>, where <job-name> is parameterized and
passed into this handler delegate, meeting Dapr’s expectation that an endpoint is available to handle triggered named jobs.
Populate your Program.cs file with the following:
using System.Text;
using System.Text.Json;
using Dapr.Jobs;
using Dapr.Jobs.Extensions;
using Dapr.Jobs.Models;
using Dapr.Jobs.Models.Responses;
var builder = WebApplication.CreateBuilder(args);
builder.Services.AddDaprJobsClient();
var app = builder.Build();
//Registers an endpoint to receive and process triggered jobs
var cancellationTokenSource = new CancellationTokenSource(TimeSpan.FromSeconds(5));
app.MapDaprScheduledJobHandler((string jobName, ReadOnlyMemory<byte> jobPayload, ILogger logger, CancellationToken cancellationToken) => {
logger?.LogInformation("Received trigger invocation for job '{jobName}'", jobName);
switch (jobName)
{
case "prod-db-backup":
// Deserialize the job payload metadata
var jobData = JsonSerializer.Deserialize<BackupJobData>(jobPayload);
// Process the backup operation - we assume this is implemented elsewhere in your code
await BackupDatabaseAsync(jobData, cancellationToken);
break;
}
}, cancellationTokenSource.Token);
await app.RunAsync();
Finally, the job itself needs to be registered with Dapr so it can be triggered at a later point in time. You can do this
by injecting a DaprJobsClient into a class and executing as part of an inbound operation to your application, but for
this example’s purposes, it’ll go at the bottom of the Program.cs file you started above. Because you’ll be using the
DaprJobsClient you registered with dependency injection, start by creating a scope so you can access it.
//Create a scope so we can access the registered DaprJobsClient
await using scope = app.Services.CreateAsyncScope();
var daprJobsClient = scope.ServiceProvider.GetRequiredService<DaprJobsClient>();
//Create the payload we wish to present alongside our future job triggers
var jobData = new BackupJobData("db-backup", new BackupMetadata("my-prod-db", "/backup-dir"));
//Serialize our payload to UTF-8 bytes
var serializedJobData = JsonSerializer.SerializeToUtf8Bytes(jobData);
//Schedule our backup job to run every minute, but only repeat 10 times
await daprJobsClient.ScheduleJobAsync("prod-db-backup", DaprJobSchedule.FromDuration(TimeSpan.FromMinutes(1)),
serializedJobData, repeats: 10);
The following Go SDK code sample schedules the job named prod-db-backup. Job data is housed in a backup database ("my-prod-db") and is scheduled with ScheduleJobAlpha1. This provides the jobData, which includes:
- The backup
Taskname - The backup task’s
Metadata, including:- The database name (
DBName) - The database location (
BackupLocation)
- The database name (
package main
import (
//...
daprc "github.com/dapr/go-sdk/client"
"github.com/dapr/go-sdk/examples/dist-scheduler/api"
"github.com/dapr/go-sdk/service/common"
daprs "github.com/dapr/go-sdk/service/grpc"
)
func main() {
// Initialize the server
server, err := daprs.NewService(":50070")
// ...
if err = server.AddJobEventHandler("prod-db-backup", prodDBBackupHandler); err != nil {
log.Fatalf("failed to register job event handler: %v", err)
}
log.Println("starting server")
go func() {
if err = server.Start(); err != nil {
log.Fatalf("failed to start server: %v", err)
}
}()
// ...
// Set up backup location
jobData, err := json.Marshal(&api.DBBackup{
Task: "db-backup",
Metadata: api.Metadata{
DBName: "my-prod-db",
BackupLocation: "/backup-dir",
},
},
)
// ...
}
The job is scheduled with a Schedule set and the amount of Repeats desired. These settings determine a max amount of times the job should be triggered and sent back to the app.
In this example, at trigger time, which is @every 1s according to the Schedule, this job is triggered and sent back to the application up to the max Repeats (10).
// ...
// Set up the job
job := daprc.Job{
Name: "prod-db-backup",
Schedule: "@every 1s",
Repeats: 10,
Data: &anypb.Any{
Value: jobData,
},
}
When a job is triggered, Dapr will automatically route the job to the event handler you set up during the server initialization. For example, in Go, you’d register the event handler like this:
...
if err = server.AddJobEventHandler("prod-db-backup", prodDBBackupHandler); err != nil {
log.Fatalf("failed to register job event handler: %v", err)
}
Dapr takes care of the underlying routing. When the job is triggered, your prodDBBackupHandler function is called with
the triggered job data. Here’s an example of handling the triggered job:
// ...
// At job trigger time this function is called
func prodDBBackupHandler(ctx context.Context, job *common.JobEvent) error {
var jobData common.Job
if err := json.Unmarshal(job.Data, &jobData); err != nil {
// ...
}
var jobPayload api.DBBackup
if err := json.Unmarshal(job.Data, &jobPayload); err != nil {
// ...
}
fmt.Printf("job %d received:\n type: %v \n typeurl: %v\n value: %v\n extracted payload: %v\n", jobCount, job.JobType, jobData.TypeURL, jobData.Value, jobPayload)
jobCount++
return nil
}
Run the Dapr sidecar
Once you’ve set up the Jobs API in your application, in a terminal window run the Dapr sidecar with the following command.
dapr run --app-id=distributed-scheduler \
--metrics-port=9091 \
--dapr-grpc-port 50001 \
--app-port 50070 \
--app-protocol grpc \
--log-level debug \
go run ./main.go