The documentation you are viewing is for Dapr v1.16 which is an older version of Dapr. For up-to-date documentation, see the latest version.
Dapr Scheduler control plane service overview
The Dapr Scheduler service is used to schedule different types of jobs, running in self-hosted mode or on Kubernetes.
- Jobs created through the Jobs API
- Actor reminder jobs (used by the actor reminders)
- Actor reminder jobs created by the Workflow API (which uses actor reminders)
From Dapr v1.15, the Scheduler service is used by default to schedule actor reminders as well as actor reminders for the Workflow API.
There is no concept of a leader Scheduler instance. All Scheduler service replicas are considered peers. All receive jobs to be scheduled for execution and the jobs are allocated between the available Scheduler service replicas for load balancing of the trigger events.
The diagram below shows how the Scheduler service is used via the jobs API when called from your application. All the jobs that are tracked by the Scheduler service are stored in the Etcd database.
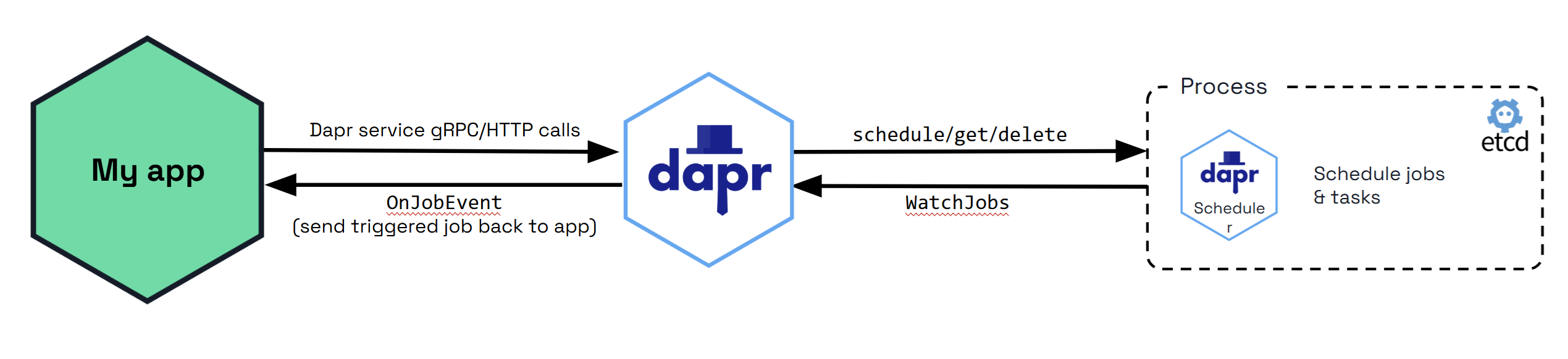
By default, Etcd is embedded in the Scheduler service, which means that the Scheduler service runs its own instance of Etcd. See Scheduler service flags for more information on how to configure the Scheduler service.
Actor Reminders
Prior to Dapr v1.15, actor reminders were run using the Placement service. Now, by default, the SchedulerReminders feature flag is set to true, and all new actor reminders you create are run using the Scheduler service to make them more scalable.
When you deploy Dapr v1.15, any existing actor reminders are automatically migrated from the Actor State Store to the Scheduler service as a one time operation for each actor type. Each replica will only migrate the reminders whose actor type and id are associated with that host. This means that only when all replicas implementing an actor type are upgraded to 1.15, will all the reminders associated with that type be migrated. There will be no loss of reminder triggers during the migration. However, you can prevent this migration and keep the existing actor reminders running using the Actor State Store by setting the SchedulerReminders flag to false in the application configuration file for the actor type.
To confirm that the migration was successful, check the Dapr sidecar logs for the following:
Running actor reminder migration from state store to scheduler
coupled with
Migrated X reminders from state store to scheduler successfully
or
Skipping migration, no missing scheduler reminders found
Job Locality
Default Job Behavior
By default, when the Scheduler service triggers jobs, they are sent back to a single replica for the same app ID that scheduled the job in a randomly load balanced manner. This provides basic load balancing across your application’s replicas, which is suitable for most use cases where strict locality isn’t required.
Using Actor Reminders for Perfect Locality
For users who require perfect job locality (having jobs triggered on the exact same host that created them), actor reminders provide a solution. To enforce perfect locality for a job:
- Create an actor type with a random UUID that is unique to the specific replica
- Use this actor type to create an actor reminder
This approach ensures that the job will always be triggered on the same host which created it, rather than being randomly distributed among replicas.
Job Triggering
Job Failure Policy and Staging Queue
When the Scheduler service triggers a job and it has a client side error, the job is retried by default with a 1s interval and 3 maximum retries.
For non-client side errors, for example, when a job cannot be sent to an available Dapr sidecar at trigger time, it is placed in a staging queue within the Scheduler service. Jobs remain in this queue until a suitable sidecar instance becomes available, at which point they are automatically sent to the appropriate Dapr sidecar instance.
Self-hosted mode
The Scheduler service Docker container is started automatically as part of dapr init. It can also be run manually as a process if you are running in slim-init mode.
The Scheduler can be run in both high availability (HA) and non-HA modes in self-hosted deployments. However, non-HA mode is not recommended for production use. If switching between non-HA and HA modes, the existing data directory must be removed, which results in loss of jobs and actor reminders. Run a back-up before making this change to avoid losing data.
Kubernetes mode
The Scheduler service is deployed as part of dapr init -k, or via the Dapr Helm charts. Scheduler always runs in high availability (HA) mode in Kubernetes deployments. Scaling the Scheduler service replicas up or down is not possible without incurring data loss due to the nature of the embedded data store. Learn more about setting HA mode in your Kubernetes service.
When a Kubernetes namespace is deleted, all the Job and Actor Reminders corresponding to that namespace are deleted.
Docker Compose Example
Here’s how to expose the etcd ports in a Docker Compose configuration for standalone mode. When running in HA mode, you only need to expose the ports for one scheduler instance to perform backup operations.
version: "3.5"
services:
scheduler-0:
image: "docker.io/daprio/scheduler:1.16.14"
command:
- "./scheduler"
- "--etcd-data-dir=/var/run/dapr/scheduler"
- "--id=scheduler-0"
- "--etcd-initial-cluster=scheduler-0=http://scheduler-0:2380,scheduler-1=http://scheduler-1:2380,scheduler-2=http://scheduler-2:2380"
ports:
- 2379:2379
volumes:
- ./dapr_scheduler/0:/var/run/dapr/scheduler
scheduler-1:
image: "docker.io/daprio/scheduler:1.16.14"
command:
- "./scheduler"
- "--etcd-data-dir=/var/run/dapr/scheduler"
- "--id=scheduler-1"
- "--etcd-initial-cluster=scheduler-0=http://scheduler-0:2380,scheduler-1=http://scheduler-1:2380,scheduler-2=http://scheduler-2:2380"
volumes:
- ./dapr_scheduler/1:/var/run/dapr/scheduler
scheduler-2:
image: "docker.io/daprio/scheduler:1.16.14"
command:
- "./scheduler"
- "--etcd-data-dir=/var/run/dapr/scheduler"
- "--id=scheduler-2"
- "--etcd-initial-cluster=scheduler-0=http://scheduler-0:2380,scheduler-1=http://scheduler-1:2380,scheduler-2=http://scheduler-2:2380"
volumes:
- ./dapr_scheduler/2:/var/run/dapr/scheduler
Managing jobs with the Dapr CLI
Dapr provides a CLI for inspecting and managing all scheduled jobs, regardless of type. The CLI is the recommended way to view, back up, and delete jobs.
There are several different types of jobs which Scheduler manages:
app/{app-id}/{job-name}: Jobs created via the Jobs APIactor/{actor-type}/{actor-id}/{reminder-name}: Actor reminder jobs created via the Actor Reminders APIactivity/{app-id}/{instance-id}::{generation-name}::{activity-index}: Used internally for Workflow Activity remindersworkflow/{app-id}/{instance-id}/{random-name}: Used internally for Workflows.
Please see here for how to manage specifically reminders with the CLI.
List jobs
dapr scheduler list
Example output:
NAME BEGIN COUNT LAST TRIGGER
actor/myactortype/actorid1/test1 -3.89s 1 2025-10-03T16:58:55Z
actor/myactortype/actorid2/test2 -3.89s 1 2025-10-03T16:58:55Z
app/test-scheduler/test1 -3.89s 1 2025-10-03T16:58:55Z
app/test-scheduler/test2 -3.89s 1 2025-10-03T16:58:55Z
activity/test-scheduler/xyz1::0::1 -888.8ms 0
activity/test-scheduler/xyz2::0::1 -888.8ms 0
workflow/test-scheduler/abc1/timer-0-TVIQGkvu +50.0h 0
workflow/test-scheduler/abc2/timer-0-OM2xqG9m +50.0h 0
For more detail, use the wide output format:
dapr scheduler list -o wide
NAMESPACE NAME BEGIN EXPIRATION SCHEDULE DUE TIME TTL REPEATS COUNT LAST TRIGGER
default actor/myactortype/actorid1/test1 2025-10-03T16:58:55Z @every 2h46m40s 2025-10-03T17:58:55+01:00 100 1 2025-10-03T16:58:55Z
default actor/myactortype/actorid2/test2 2025-10-03T16:58:55Z @every 2h46m40s 2025-10-03T17:58:55+01:00 100 1 2025-10-03T16:58:55Z
default app/test-scheduler/test1 2025-10-03T16:58:55Z @every 100m 2025-10-03T17:58:55+01:00 1234 1 2025-10-03T16:58:55Z
default app/test-scheduler/test2 2025-10-03T16:58:55Z 2025-10-03T19:45:35Z @every 100m 2025-10-03T17:58:55+01:00 10000s 56788 1 2025-10-03T16:58:55Z
default activity/test-scheduler/xyz1::0::1 2025-10-03T16:58:58Z 0s 0
default activity/test-scheduler/xyz2::0::1 2025-10-03T16:58:58Z 0s 0
default workflow/test-scheduler/abc1/timer-0-TVIQGkvu 2025-10-05T18:58:58Z 2025-10-05T18:58:58Z 0
default workflow/test-scheduler/abc2/timer-0-OM2xqG9m 2025-10-05T18:58:58Z 2025-10-05T18:58:58Z 0
Get job details
dapr scheduler get app/my-app/job1 -o yaml
Delete jobs
Delete one or more specific jobs:
dapr scheduler delete app/my-app/job1 actor/MyActor/123/reminder1
Bulk delete jobs with filters:
dapr scheduler delete-all all
dapr scheduler delete-all app/my-app
dapr scheduler delete-all actor/MyActorType
Backup and restore jobs
Export all jobs to a file:
dapr scheduler export -o backup.bin
Re-import jobs from a backup file:
dapr scheduler import -f backup.bin
Monitoring Scheduler’s etcd Metrics
Port forward the Scheduler instance and view etcd’s metrics with the following:
curl -s http://localhost:2379/metrics
Fine tune the embedded etcd to your needs by reviewing and configuring the Scheduler’s etcd flags as needed.
Disabling the Scheduler service
If you are not using any features that require the Scheduler service (Jobs API, Actor Reminders, or Workflows), you can disable it by setting global.scheduler.enabled=false.
For more information on running Dapr on Kubernetes, visit the Kubernetes hosting page.
Flag tuning
A number of Etcd flags are exposed on Scheduler which can be used to tune for your deployment use case.
External Etcd database
Scheduler can be configured to use an external Etcd database instead of the embedded one inside the Scheduler service replicas. It may be interesting to decouple the storage volume from the Scheduler StatefulSet or container, because of how the cluster or environment is administered or what storage backend is being used. It can also be the case that moving the persistent storage outside of the scheduler runtime completely is desirable, or there is some existing Etcd cluster provider which will be reused. Externalising the Etcd database also means that the Scheduler replicas can be horizontally scaled at will, however note that during scale events, job triggering will be paused. Scheduler replica count does not need to match the Etcd node count constraints.
To use an external Etcd cluster, set the --etcd-embed flag to false and provide the --etcd-client-endpoints flag with the endpoints of your Etcd cluster.
Optionally also include --etcd-client-username and --etcd-client-password flags for authentication if the Etcd cluster requires it.
--etcd-embed bool When enabled, the Etcd database is embedded in the scheduler server. If false, the scheduler connects to an external Etcd cluster using the --etcd-client-endpoints flag. (default true)
--etcd-client-endpoints stringArray Comma-separated list of etcd client endpoints to connect to. Only used when --etcd-embed is false.
--etcd-client-username string Username for etcd client authentication. Only used when --etcd-embed is false.
--etcd-client-password string Password for etcd client authentication. Only used when --etcd-embed is false.
Helm:
dapr_scheduler.etcdEmbed=true
dapr_scheduler.etcdClientEndpoints=[]
dapr_scheduler.etcdClientUsername=""
dapr_scheduler.etcdClientPassword=""
Etcd leadership election tuning
To improve the speed of election leadership of rescue nodes in the event of a failure, the following flag may be used to speed up the election process.
--etcd-initial-election-tick-advance Whether to fast-forward initial election ticks on boot for faster election. When it is true, then local member fast-forwards election ticks to speed up “initial” leader election trigger. This benefits the case of larger election ticks. Disabling this would slow down initial bootstrap process for cross datacenter deployments. Make your own tradeoffs by configuring this flag at the cost of slow initial bootstrap.
Helm:
dapr_scheduler.etcdInitialElectionTickAdvance=true
Storage tuning
The following options can be used to tune the embedded Etcd storage to the needs of your deployment. A deeper understanding of what these flags do can be found in the Etcd documentation.
Note
Changing these flags can greatly change the performance and behaviour of the Scheduler, so caution is advised when modifying them from the default set by Dapr. Changing these settings should always been done first in a testing environment, and monitored closely before applying to production.--etcd-backend-batch-interval string Maximum time before committing the backend transaction. (default "50ms")
--etcd-backend-batch-limit int Maximum operations before committing the backend transaction. (default 5000)
--etcd-compaction-mode string Compaction mode for etcd. Can be 'periodic' or 'revision' (default "periodic")
--etcd-compaction-retention string Compaction retention for etcd. Can express time or number of revisions, depending on the value of 'etcd-compaction-mode' (default "10m")
--etcd-experimental-bootstrap-defrag-threshold-megabytes uint Minimum number of megabytes needed to be freed for etcd to consider running defrag during bootstrap. Needs to be set to non-zero value to take effect. (default 100)
--etcd-max-snapshots uint Maximum number of snapshot files to retain (0 is unlimited). (default 10)
--etcd-max-wals uint Maximum number of write-ahead logs to retain (0 is unlimited). (default 10)
--etcd-snapshot-count uint Number of committed transactions to trigger a snapshot to disk. (default 10000)
Helm:
dapr_scheduler.etcdBackendBatchInterval="50ms"
dapr_scheduler.etcdBackendBatchLimit=5000
dapr_scheduler.etcdCompactionMode="periodic"
dapr_scheduler.etcdCompactionRetention="10m"
dapr_scheduler.etcdDefragThresholdMB=100
dapr_scheduler.etcdMaxSnapshots=10
Related links
- Learn more about the Jobs API.
- [Learn more about Actor Reminders.]https://docs.dapr.io/developing-applications/building-blocks/actors/actors-features-concepts/#reminders)