This is the multi-page printable view of this section. Click here to print.
Overview of the Dapr services
1 - Dapr sidecar (daprd) overview
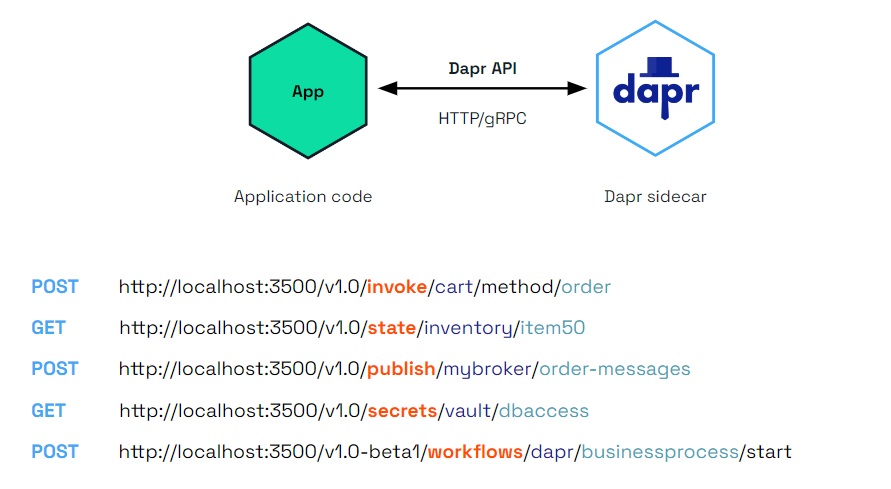
Dapr uses a sidecar pattern, meaning the Dapr APIs are run and exposed on a separate process, the Dapr sidecar, running alongside your application. The Dapr sidecar process is named daprd and is launched in different ways depending on the hosting environment.
The Dapr sidecar exposes:
- Building block APIs used by your application business logic
- A metadata API for discoverability of capabilities and to set attributes
- A health API to determine health status and sidecar readiness and liveness
The Dapr sidecar will reach readiness state once the application is accessible on its configured port. The application cannot access the Dapr components during application start up/initialization.
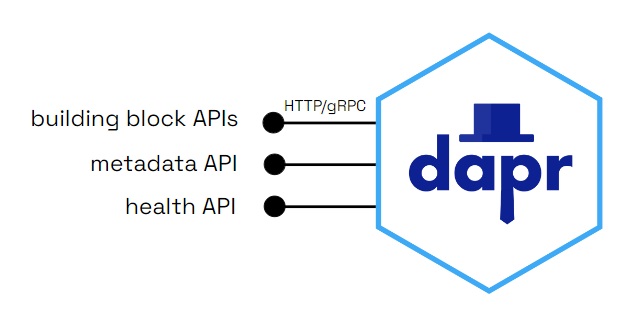
The sidecar APIs are called from your application over local http or gRPC endpoints.
Self-hosted with dapr run
When Dapr is installed in self-hosted mode, the daprd binary is downloaded and placed under the user home directory ($HOME/.dapr/bin for Linux/macOS or %USERPROFILE%\.dapr\bin\ for Windows).
In self-hosted mode, running the Dapr CLI run command launches the daprd executable with the provided application executable. This is the recommended way of running the Dapr sidecar when working locally in scenarios such as development and testing.
You can find the various arguments that the CLI exposes to configure the sidecar in the Dapr run command reference.
Kubernetes with dapr-sidecar-injector
On Kubernetes, the Dapr control plane includes the dapr-sidecar-injector service, which watches for new pods with the dapr.io/enabled annotation and injects a container with the daprd process within the pod. In this case, sidecar arguments can be passed through annotations as outlined in the Kubernetes annotations column in this table.
Running the sidecar directly
In most cases you do not need to run daprd explicitly, as the sidecar is either launched by the CLI (self-hosted mode) or by the dapr-sidecar-injector service (Kubernetes). For advanced use cases (debugging, scripted deployments, etc.) the daprd process can be launched directly.
For a detailed list of all available arguments run daprd --help or see this table which outlines how the daprd arguments relate to the CLI arguments and Kubernetes annotations.
Examples
Start a sidecar alongside an application by specifying its unique ID.
Note:
--app-idis a required field, and cannot contain dots.daprd --app-id myappSpecify the port your application is listening to
daprd --app-id myapp --app-port 5000If you are using several custom resources and want to specify the location of the resource definition files, use the
--resources-pathargument:daprd --app-id myapp --resources-path <PATH-TO-RESOURCES-FILES>If you’ve organized your components and other resources (for example, resiliency policies, subscriptions, or configuration) into separate folders or a shared folder, you can specify multiple resource paths:
daprd --app-id myapp --resources-path <PATH-1-TO-RESOURCES-FILES> --resources-path <PATH-2-TO-RESOURCES-FILES>Enable collection of Prometheus metrics while running your app
daprd --app-id myapp --enable-metricsListen to IPv4 and IPv6 loopback only
daprd --app-id myapp --dapr-listen-addresses '127.0.0.1,[::1]'
2 - Dapr Operator control plane service overview
When running Dapr in Kubernetes mode, a pod running the Dapr Operator service manages Dapr component updates and provides Kubernetes services endpoints for Dapr.
Running the operator service
The operator service is deployed as part of dapr init -k, or via the Dapr Helm charts. For more information on running Dapr on Kubernetes, visit the Kubernetes hosting page.
Additional configuration options
The operator service includes additional configuration options.
Injector watchdog
The operator service includes an injector watchdog feature which periodically polls all pods running in your Kubernetes cluster and confirms that the Dapr sidecar is injected in those which have the dapr.io/enabled=true annotation. It is primarily meant to address situations where the Injector service did not successfully inject the sidecar (the daprd container) into pods.
The injector watchdog can be useful in a few situations, including:
Recovering from a Kubernetes cluster completely stopped. When a cluster is completely stopped and then restarted (including in the case of a total cluster failure), pods are restarted in a random order. If your application is restarted before the Dapr control plane (specifically the Injector service) is ready, the Dapr sidecar may not be injected into your application’s pods, causing your application to behave unexpectedly.
Addressing potential random failures with the sidecar injector, such as transient failures within the Injector service.
If the watchdog detects a pod that does not have a sidecar when it should have had one, it deletes it. Kubernetes will then re-create the pod, invoking the Dapr sidecar injector again.
The injector watchdog feature is disabled by default.
You can enable it by passing the --watch-interval flag to the operator command, which can take one of the following values:
--watch-interval=0: disables the injector watchdog (default value if the flag is omitted).--watch-interval=<interval>: the injector watchdog is enabled and polls all pods at the given interval; the value for the interval is a string that includes the unit. For example:--watch-interval=10s(every 10 seconds) or--watch-interval=2m(every 2 minutes).--watch-interval=once: the injector watchdog runs only once when the operator service is started.
If you’re using Helm, you can configure the injector watchdog with the dapr_operator.watchInterval option, which has the same values as the command line flags.
The injector watchdog is safe to use when the operator service is running in HA (High Availability) mode with more than one replica. In this case, Kubernetes automatically elects a “leader” instance which is the only one that runs the injector watchdog service.
However, when in HA mode, if you configure the injector watchdog to run “once”, the watchdog polling is actually started every time an instance of the operator service is elected as leader. This means that, should the leader of the operator service crash and a new leader be elected, that would trigger the injector watchdog again.
Watch this video for an overview of the injector watchdog:
3 - Dapr Placement control plane service overview
The Dapr Placement service is used to calculate and distribute distributed hash tables for the location of Dapr actors running in self-hosted mode or on Kubernetes. Grouped by namespace, the hash tables map actor types to pods or processes so a Dapr application can communicate with the actor. Anytime a Dapr application activates a Dapr actor, the Placement service updates the hash tables with the latest actor location.
Self-hosted mode
The Placement service Docker container is started automatically as part of dapr init. It can also be run manually as a process if you are running in slim-init mode.
Kubernetes mode
The Placement service is deployed as part of dapr init -k, or via the Dapr Helm charts. You can run Placement in high availability (HA) mode. Learn more about setting HA mode in your Kubernetes service.
For more information on running Dapr on Kubernetes, visit the Kubernetes hosting page.
Placement tables
There is an HTTP API /placement/state for Placement service that exposes placement table information. The API is exposed on the sidecar on the same port as the healthz. This is an unauthenticated endpoint, and is disabled by default. You need to set DAPR_PLACEMENT_METADATA_ENABLED environment or metadata-enabled command line args to true to enable it. If you are using helm you just need to set dapr_placement.metadataEnabled to true.
Important
When deploying actors into different namespaces (https://v1-16.docs.dapr.io/developing-applications/building-blocks/actors/namespaced-actors/), it is recommended to disable themetadata-enabled if you want to prevent retrieving actors from all namespaces. The metadata endpoint is scoped to all namespaces.Usecase:
The placement table API can be used to retrieve the current placement table, which contains all the actors registered across all namespaces. This is helpful for debugging and allowing tools to extract and present information about actors.
HTTP Request
GET http://localhost:<healthzPort>/placement/state
HTTP Response Codes
| Code | Description |
|---|---|
| 200 | Placement tables information returned |
| 500 | Placement could not return the placement tables information |
HTTP Response Body
Placement tables API Response Object
| Name | Type | Description |
|---|---|---|
| tableVersion | int | The placement table version |
| hostList | Actor Host Info[] | A json array of registered actors host info. |
| Name | Type | Description |
|---|---|---|
| name | string | The host:port address of the actor. |
| appId | string | app id. |
| actorTypes | json string array | List of actor types it hosts. |
| updatedAt | timestamp | Timestamp of the actor registered/updated. |
Examples
curl localhost:8080/placement/state
{
"hostList": [{
"name": "198.18.0.1:49347",
"namespace": "ns1",
"appId": "actor1",
"actorTypes": ["testActorType1", "testActorType3"],
"updatedAt": 1690274322325260000
},
{
"name": "198.18.0.2:49347",
"namespace": "ns2",
"appId": "actor2",
"actorTypes": ["testActorType2"],
"updatedAt": 1690274322325260000
},
{
"name": "198.18.0.3:49347",
"namespace": "ns2",
"appId": "actor2",
"actorTypes": ["testActorType2"],
"updatedAt": 1690274322325260000
}
],
"tableVersion": 1
}
Disabling the Placement service
The Placement service can be disabled with the following setting:
global.actors.enabled=false
The Placement service is not deployed with this setting in Kubernetes mode. This not only disables actor deployment, but also disables workflows, given that workflows use actors. This setting only applies in Kubernetes mode, however initializing Dapr with --slim excludes the Placement service from being deployed in self-hosted mode.
For more information on running Dapr on Kubernetes, visit the Kubernetes hosting page.
Related links
4 - Dapr Scheduler control plane service overview
The Dapr Scheduler service is used to schedule different types of jobs, running in self-hosted mode or on Kubernetes.
- Jobs created through the Jobs API
- Actor reminder jobs (used by the actor reminders)
- Actor reminder jobs created by the Workflow API (which uses actor reminders)
From Dapr v1.15, the Scheduler service is used by default to schedule actor reminders as well as actor reminders for the Workflow API.
There is no concept of a leader Scheduler instance. All Scheduler service replicas are considered peers. All receive jobs to be scheduled for execution and the jobs are allocated between the available Scheduler service replicas for load balancing of the trigger events.
The diagram below shows how the Scheduler service is used via the jobs API when called from your application. All the jobs that are tracked by the Scheduler service are stored in the Etcd database.
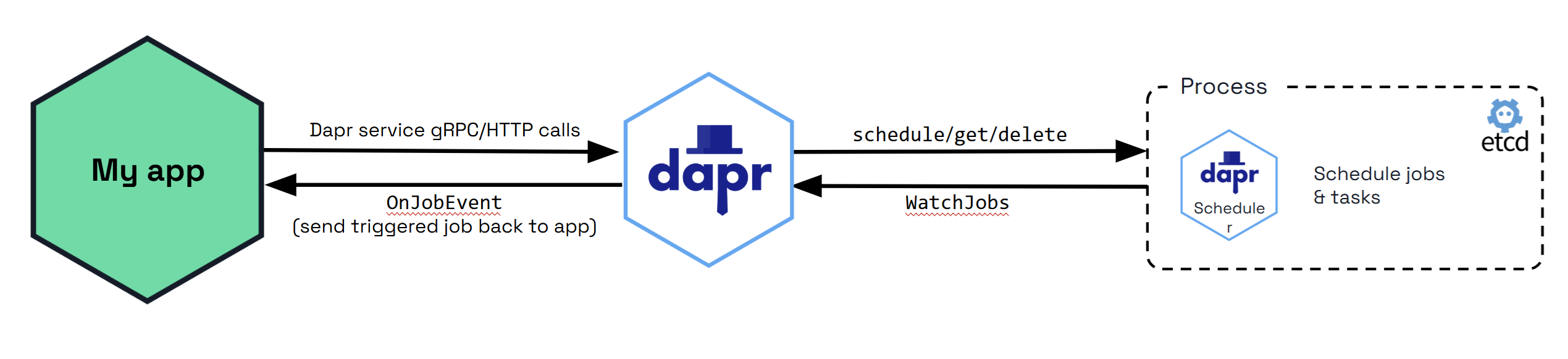
By default, Etcd is embedded in the Scheduler service, which means that the Scheduler service runs its own instance of Etcd. See Scheduler service flags for more information on how to configure the Scheduler service.
Actor Reminders
Prior to Dapr v1.15, actor reminders were run using the Placement service. Now, by default, the SchedulerReminders feature flag is set to true, and all new actor reminders you create are run using the Scheduler service to make them more scalable.
When you deploy Dapr v1.15, any existing actor reminders are automatically migrated from the Actor State Store to the Scheduler service as a one time operation for each actor type. Each replica will only migrate the reminders whose actor type and id are associated with that host. This means that only when all replicas implementing an actor type are upgraded to 1.15, will all the reminders associated with that type be migrated. There will be no loss of reminder triggers during the migration. However, you can prevent this migration and keep the existing actor reminders running using the Actor State Store by setting the SchedulerReminders flag to false in the application configuration file for the actor type.
To confirm that the migration was successful, check the Dapr sidecar logs for the following:
Running actor reminder migration from state store to scheduler
coupled with
Migrated X reminders from state store to scheduler successfully
or
Skipping migration, no missing scheduler reminders found
Job Locality
Default Job Behavior
By default, when the Scheduler service triggers jobs, they are sent back to a single replica for the same app ID that scheduled the job in a randomly load balanced manner. This provides basic load balancing across your application’s replicas, which is suitable for most use cases where strict locality isn’t required.
Using Actor Reminders for Perfect Locality
For users who require perfect job locality (having jobs triggered on the exact same host that created them), actor reminders provide a solution. To enforce perfect locality for a job:
- Create an actor type with a random UUID that is unique to the specific replica
- Use this actor type to create an actor reminder
This approach ensures that the job will always be triggered on the same host which created it, rather than being randomly distributed among replicas.
Job Triggering
Job Failure Policy and Staging Queue
When the Scheduler service triggers a job and it has a client side error, the job is retried by default with a 1s interval and 3 maximum retries.
For non-client side errors, for example, when a job cannot be sent to an available Dapr sidecar at trigger time, it is placed in a staging queue within the Scheduler service. Jobs remain in this queue until a suitable sidecar instance becomes available, at which point they are automatically sent to the appropriate Dapr sidecar instance.
Self-hosted mode
The Scheduler service Docker container is started automatically as part of dapr init. It can also be run manually as a process if you are running in slim-init mode.
The Scheduler can be run in both high availability (HA) and non-HA modes in self-hosted deployments. However, non-HA mode is not recommended for production use. If switching between non-HA and HA modes, the existing data directory must be removed, which results in loss of jobs and actor reminders. Run a back-up before making this change to avoid losing data.
Kubernetes mode
The Scheduler service is deployed as part of dapr init -k, or via the Dapr Helm charts. Scheduler always runs in high availability (HA) mode in Kubernetes deployments. Scaling the Scheduler service replicas up or down is not possible without incurring data loss due to the nature of the embedded data store. Learn more about setting HA mode in your Kubernetes service.
When a Kubernetes namespace is deleted, all the Job and Actor Reminders corresponding to that namespace are deleted.
Docker Compose Example
Here’s how to expose the etcd ports in a Docker Compose configuration for standalone mode. When running in HA mode, you only need to expose the ports for one scheduler instance to perform backup operations.
version: "3.5"
services:
scheduler-0:
image: "docker.io/daprio/scheduler:1.16.0"
command:
- "./scheduler"
- "--etcd-data-dir=/var/run/dapr/scheduler"
- "--id=scheduler-0"
- "--etcd-initial-cluster=scheduler-0=http://scheduler-0:2380,scheduler-1=http://scheduler-1:2380,scheduler-2=http://scheduler-2:2380"
ports:
- 2379:2379
volumes:
- ./dapr_scheduler/0:/var/run/dapr/scheduler
scheduler-1:
image: "docker.io/daprio/scheduler:1.16.0"
command:
- "./scheduler"
- "--etcd-data-dir=/var/run/dapr/scheduler"
- "--id=scheduler-1"
- "--etcd-initial-cluster=scheduler-0=http://scheduler-0:2380,scheduler-1=http://scheduler-1:2380,scheduler-2=http://scheduler-2:2380"
volumes:
- ./dapr_scheduler/1:/var/run/dapr/scheduler
scheduler-2:
image: "docker.io/daprio/scheduler:1.16.0"
command:
- "./scheduler"
- "--etcd-data-dir=/var/run/dapr/scheduler"
- "--id=scheduler-2"
- "--etcd-initial-cluster=scheduler-0=http://scheduler-0:2380,scheduler-1=http://scheduler-1:2380,scheduler-2=http://scheduler-2:2380"
volumes:
- ./dapr_scheduler/2:/var/run/dapr/scheduler
Back Up and Restore Scheduler Data
In production environments, it’s recommended to perform periodic backups of this data at an interval that aligns with your recovery point objectives.
Port Forward for Backup Operations
To perform backup and restore operations, you’ll need to access the embedded etcd instance. This requires port forwarding to expose the etcd ports (port 2379).
Kubernetes Example
Here’s how to port forward and connect to the etcd instance:
kubectl port-forward svc/dapr-scheduler-server 2379:2379 -n dapr-system
Performing Backup and Restore
Once you have access to the etcd ports, you can follow the official etcd backup and restore documentation to perform backup and restore operations. The process involves using standard etcd commands to create snapshots and restore from them.
Monitoring Scheduler’s etcd Metrics
Port forward the Scheduler instance and view etcd’s metrics with the following:
curl -s http://localhost:2379/metrics
Fine tune the embedded etcd to your needs by reviewing and configuring the Scheduler’s etcd flags as needed.
Disabling the Scheduler service
If you are not using any features that require the Scheduler service (Jobs API, Actor Reminders, or Workflows), you can disable it by setting global.scheduler.enabled=false.
For more information on running Dapr on Kubernetes, visit the Kubernetes hosting page.
Flag tuning
A number of Etcd flags are exposed on Scheduler which can be used to tune for your deployment use case.
External Etcd database
Scheduler can be configured to use an external Etcd database instead of the embedded one inside the Scheduler service replicas. It may be interesting to decouple the storage volume from the Scheduler StatefulSet or container, because of how the cluster or environment is administered or what storage backend is being used. It can also be the case that moving the persistent storage outside of the scheduler runtime completely is desirable, or there is some existing Etcd cluster provider which will be reused. Externalising the Etcd database also means that the Scheduler replicas can be horizontally scaled at will, however note that during scale events, job triggering will be paused. Scheduler replica count does not need to match the Etcd node count constraints.
To use an external Etcd cluster, set the --etcd-embed flag to false and provide the --etcd-client-endpoints flag with the endpoints of your Etcd cluster.
Optionally also include --etcd-client-username and --etcd-client-password flags for authentication if the Etcd cluster requires it.
--etcd-embed bool When enabled, the Etcd database is embedded in the scheduler server. If false, the scheduler connects to an external Etcd cluster using the --etcd-client-endpoints flag. (default true)
--etcd-client-endpoints stringArray Comma-separated list of etcd client endpoints to connect to. Only used when --etcd-embed is false.
--etcd-client-username string Username for etcd client authentication. Only used when --etcd-embed is false.
--etcd-client-password string Password for etcd client authentication. Only used when --etcd-embed is false.
Helm:
dapr_scheduler.etcdEmbed=true
dapr_scheduler.etcdClientEndpoints=[]
dapr_scheduler.etcdClientUsername=""
dapr_scheduler.etcdClientPassword=""
Etcd leadership election tuning
To improve the speed of election leadership of rescue nodes in the event of a failure, the following flag may be used to speed up the election process.
--etcd-initial-election-tick-advance Whether to fast-forward initial election ticks on boot for faster election. When it is true, then local member fast-forwards election ticks to speed up “initial” leader election trigger. This benefits the case of larger election ticks. Disabling this would slow down initial bootstrap process for cross datacenter deployments. Make your own tradeoffs by configuring this flag at the cost of slow initial bootstrap.
Helm:
dapr_scheduler.etcdInitialElectionTickAdvance=true
Storage tuning
The following options can be used to tune the embedded Etcd storage to the needs of your deployment. A deeper understanding of what these flags do can be found in the Etcd documentation.
Note
Changing these flags can greatly change the performance and behaviour of the Scheduler, so caution is advised when modifying them from the default set by Dapr. Changing these settings should always been done first in a testing environment, and monitored closely before applying to production.--etcd-backend-batch-interval string Maximum time before committing the backend transaction. (default "50ms")
--etcd-backend-batch-limit int Maximum operations before committing the backend transaction. (default 5000)
--etcd-compaction-mode string Compaction mode for etcd. Can be 'periodic' or 'revision' (default "periodic")
--etcd-compaction-retention string Compaction retention for etcd. Can express time or number of revisions, depending on the value of 'etcd-compaction-mode' (default "10m")
--etcd-experimental-bootstrap-defrag-threshold-megabytes uint Minimum number of megabytes needed to be freed for etcd to consider running defrag during bootstrap. Needs to be set to non-zero value to take effect. (default 100)
--etcd-max-snapshots uint Maximum number of snapshot files to retain (0 is unlimited). (default 10)
--etcd-max-wals uint Maximum number of write-ahead logs to retain (0 is unlimited). (default 10)
--etcd-snapshot-count uint Number of committed transactions to trigger a snapshot to disk. (default 10000)
Helm:
dapr_scheduler.etcdBackendBatchInterval="50ms"
dapr_scheduler.etcdBackendBatchLimit=5000
dapr_scheduler.etcdCompactionMode="periodic"
dapr_scheduler.etcdCompactionRetention="10m"
dapr_scheduler.etcdDefragThresholdMB=100
dapr_scheduler.etcdMaxSnapshots=10
Related links
5 - Dapr Sentry control plane service overview
The Dapr Sentry service manages mTLS between services and acts as a certificate authority. It generates mTLS certificates and distributes them to any running sidecars. This allows sidecars to communicate with encrypted, mTLS traffic. For more information read the sidecar-to-sidecar communication overview.
Self-hosted mode
The Sentry service Docker container is not started automatically as part of dapr init. However it can be executed manually by following the instructions for setting up mutual TLS.
It can also be run manually as a process if you are running in slim-init mode.
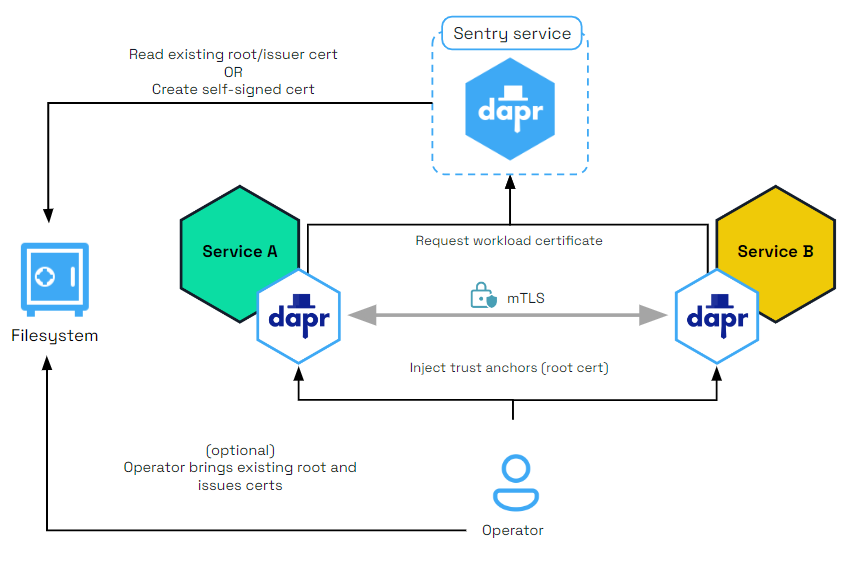
Kubernetes mode
The sentry service is deployed as part of dapr init -k, or via the Dapr Helm charts. For more information on running Dapr on Kubernetes, visit the Kubernetes hosting page.
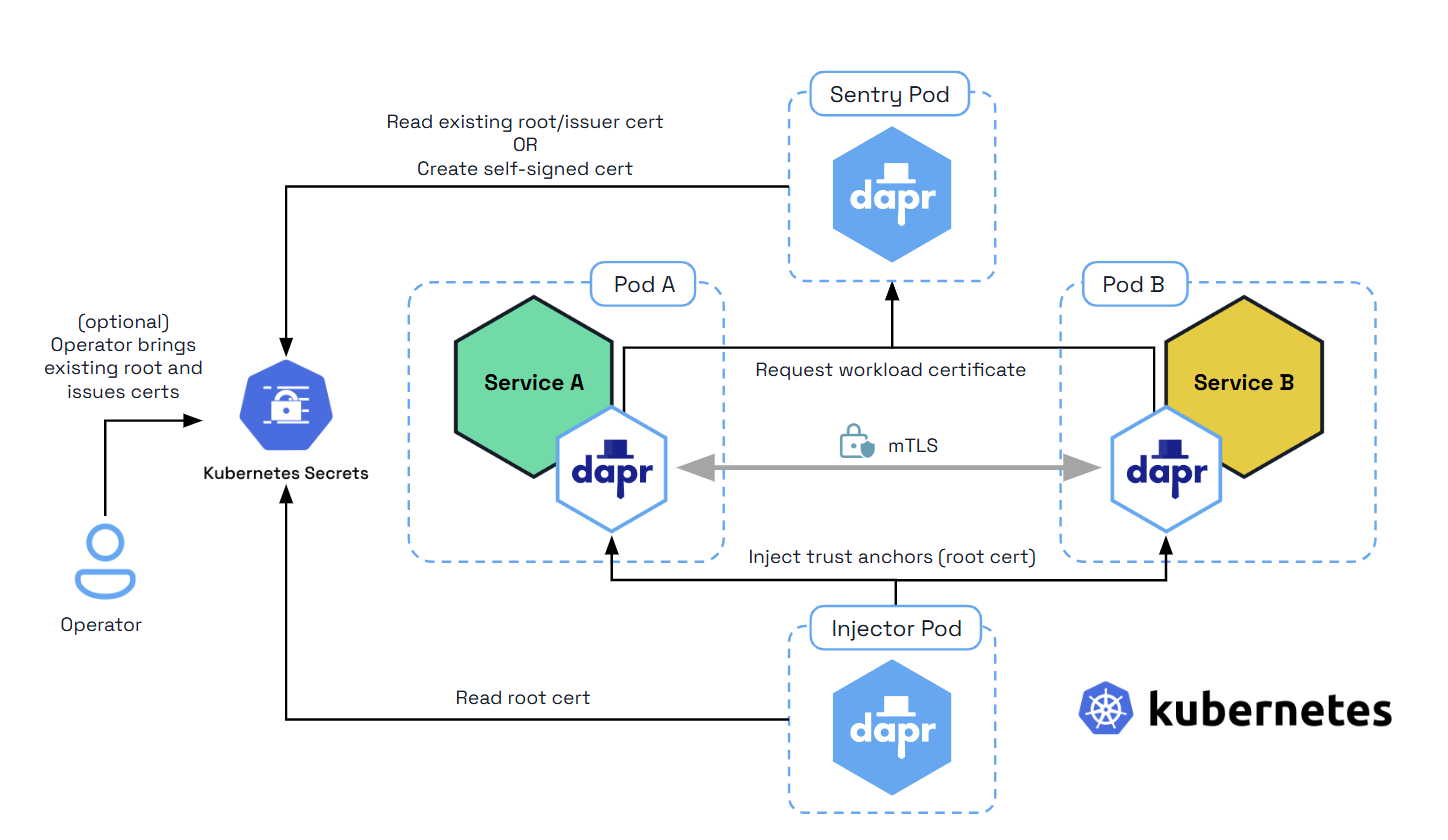
Further reading
6 - Dapr Sidecar Injector control plane service overview
When running Dapr in Kubernetes mode, a pod is created running the Dapr Sidecar Injector service, which looks for pods initialized with the Dapr annotations, and then creates another container in that pod for the daprd service
Running the sidecar injector
The sidecar injector service is deployed as part of dapr init -k, or via the Dapr Helm charts. For more information on running Dapr on Kubernetes, visit the Kubernetes hosting page.